LTE/SAE的QoS机制
具备更高的数据传输率、 更灵活的频谱带宽配置、更小的系统时延、 更低的运营成本、 更多样化的业务、以及无缝移动性是运营商对下一代移动网络的必然要求。根据 3GPP R8 版本确定的长期演进( LTE)与系统架构演进( SAE) 两大标准所构建的LTE/ SAE 系统,通过基于全 IP的分组核心网, 扁平化的网络层次架构, 并支持多种接入技术灵活接入的特点满足了以上的要求。
同时, 提供具有严格服务质量( QoS)保证的数据、语音、 图像、 视频等多媒体业务, 和支持跨不同接入网络的端到端QoS 保证, 成为 LTE/ SAE 系统的研究重点之一。
保证服务质量的目的是向用户提供满意的服务,不同类型的业务对服务质量的要求有所不同, 传统的衡量服务质量的参数包括端到端延迟、 抖动、 分组丢失率、 网络吞吐率和数据传输可靠性等。
由于LTE/ SAE 系统在接入网络结构上的优化,接入网结构更加扁平化, 即把通用移动通信系统( UMT S)的无线网络控制器( RNC) 和基站( Node B)两个节点, 简化到只有演进型基站( eNode B)一个节点,从而演进系统的 QoS 结构相比 UMT S 的QoS 进行了简化, 但也做了不少增强和改进。比如由于希望更好地实现用户的“永远在线”体验, 故引入了默认承载
概念; 为了取消 UMTS 系统复杂的QoS 协商机制, 放弃了专用信道概念, 采用共享信道和配备灵活的动态调度机制。
下文将通过介绍 LTE/ SAE 的承载业务架构, 分析承载级QoS的参数和属性, 然后将其与 2G和3G 的QoS 比较, 进一步说明 LTE/ SAE 给用户带来的体验的提高。
1、LTE/SAE的QoS机制
1.1 SAE承载业务架构,
由于 LTE/ SAE 系统需要提供的是端到端 QoS,所以沿用了 UMTS 系统相似的QoS框架——分层次、分区域的QoS体系结构,即上层的QoS要求分解为下层的QoS要求分解为下层的QoS属性, 下层为上层提供承载业务。SAE 的QoS 承载业务架构如下图所示。 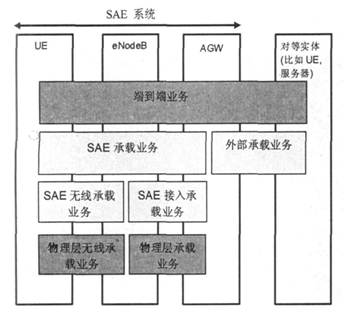
图中端到端的承载业务可以沿着端到端的路径划分成不同的网络段业务。端到端承载业务可以分解成两部分: SAE 承载业务与外部承载业务。其中, 外部承载业务用于连接 UMT S 核心网和位于外部网络节点之间的业务承载。SAE 承载业务则可以分为 SAE无线承载业务与 SAE 接入承载业务两部分。SAE 无线承载业务根据必需的QoS, 在eNodeB与 UE 之间传输承载业务数据, 将无线承载链接到对应的承载业务;SAE 接入承载业务根据必需的QoS, 在AGW 和 eNodeB 之间传输承载业务数据, 向 eNode B 提供端到端承载的聚合 QoS描述, 同时将接入承载链接到对应的承载业务。
SAE 的QoS 控制的基本粒度是承载, 即相同承载上的所有流量将获得相同的 QoS 保障, 不同类型的承载提供不同的 QoS 保障。SAE 还提出了一些新的承载类型概念, 比如默认承载、 专用承载、GBR 承载和Non- GBR承载等。
1)默认承载: 一种满足默认 QoS 的数据和信令的用户承载。默认承载可以简单理解为一种提供尽力而为 IP 连接的承载, 给用户设备( UE) 提供 永远在线!的 IP连接。默认承载的 QoS参数可以来自于从归属用户服务器( HSS)中获取的签约数据, 也可以通过策略计费规则功能( PCRF)交互或者基于本地配置。
2)专用承载: 对某些特定业务所使用的 SAE 承载。一般情况下专用SAE 承载的 QoS 比默认 QoS 的要求高。专用承载在 UE 关联上行( UL )业务流模板( TFT ) , 在PDN GW关联一个 DL( 下行) T FT, T FT 中包含业务数据流的过滤器, 而这些过滤器只能匹配某些准则的分组, 专用承载的QoS 参数总是由分组核心网分配。
3) GBR承载: 与保证比特速率( GBR)承载相关的专用网络资源, 在承载建立或修改过程中通过例如eNode B 的接纳控制等功能永久分配给某个承载, 这个承载在比特速率上要求能够保证不变。
4) Non- GBR承载: 与 GBR 承载相反, 网络资源不能永久分配给某个承载, 即不能保证该承载的比特速率不变, 就是 Non- GBR承载。专用承载可以是GBR承载或Non- GBR 承载, 而默认承载应该是 Non- GBR 承载。一个承载维护的是一个服务数据流( SDF )的集合体, 对应相同承载级别 QoS 的多个 SDF的集合, 每个SDF是由 IP的5元组(源 IP地址、 目的 IP 地址、 源端口号、 目的端口号、IP 层以上协议 ID)描述, 以此来识别终端和应用或服务。所以 SDF 可以用来连接到Web、 流媒体服务器或邮箱服务器。
1.2 SAE QoS参数与属性
1. 2. 1 QoS 参数
一个 SAE 的承载关联到下列承载级 QoS 参数。
( 1) QoS 分类标识( QCI)。
QCI 可同时应用于 GBR和 Non- GBR 承载。一个 QCI是一个值, 用于指定访问节点内定义的控制承载级分组转发方式(如调度权重、 接纳门限、 队列管理门限、 链路层协议配置等) , 这些都可以有运营商预先设置到接入网节点(比如eNode B) 中。在接口上使用QCI 而不是传输一组 QoS 参数主要是为了减少接口上的控制信令数据传输量, 并且在多厂商互联和漫游环境下使用不同设备或系统间的互连互通更加容易。
( 2)分配和保留优先级( ARP)。
ARP 可同时应用于 GBR 和 Non - GBR 承载。ARP的主要目的是能够决定是否接受请求的承载建立/修改(尤其对于 GBR承载的无线容量是否有效) ,或者在资源受限时拒绝上述请求。另外, eNode B 可以使用 ARP 决定资源受限时,哪个承载可以丢弃。一个承载的 ARP仅在承载建立成功之前对承载的建立产生影响。承载建立之后再需要对承载的特性进行改变时, 应该由QCI、 GBR、 MBR和AMBR等参数决定。
( 3)保证比特速率( GBR)。
GBR仅应用于 GBR承载, 提供给 GBR承载保证的比特速率, GBR承载的业务包括语音、 流媒体、 实时游戏等。
( 4)最大比特速率( MBR)。
MBR仅应用于 GBR 承载, 它为业务设置数据传输速率的限制。如果发现业务的数据传输速率超过MBR时, 网络将通过业务量整形算法来限制速率。MBR的值一般大于或等于 GBR 的值。
( 5)聚合最大比特速率( AMBR)。
AMBR仅应用于 Non- GBR 承载, 同一个 UE 的多个SAE 承载可以共享同一个AMBR, 即一组SAE承载中的每个承载可以使用全部的 AMBR 资源, 例如当其他SAE 承载没有任何业务流时, 有业务流的那个承载可以使用全部的 AMBR定义的全部带宽。如果超出了 AMBR限制, 网络可能在上行链路和下行链路使用业务流量调节算法,就像 MBR的调节算法一样。
1. 2. 2 标准 QCI 属性
一个 QCI 特性可由承载类型、 优先级、 分组延迟预算、 分组丢失率等组成, 它代表了 SAE 系统为某个SDF 提供的QoS 特性。每个SDF仅与一个QCI 关联,如果多个 SDF 具有相同的 QCI 和 ARP 值, 则它们可以作为单独的业务集合来处理, 这就是 SDF 集合。QCI 特性一般由运营商根据实际需求预配置在 eNodeB 上,下表给出了SAE 系统定义的标准QCI 属性。
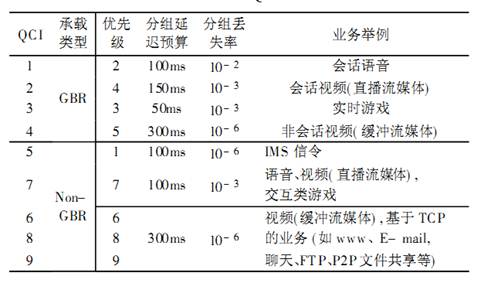
( 1)承载类型: 决定是否需要在整个承载生存时间内固定分配与承载相关的资源,也就是决定是GBR承载还是 Non- GBR承载。对于一个业务的承载类型是由运营商的策略决定, 当有足够的容量时, 实时业务和非实时业务都可由 Non- GBR承载进行传输。
( 2)优先级: 用来区分相同或不同 UE 的 SDF 集合。每个 QCI 都与一个优先级相关联, 优先级数越小表示优先级别越高。
( 3)分组延迟预算( PDB) : 定义了链路层 SDU 在接入节点和 UE 之间的链路中的逗留时间。链路层中可包括排队管理功能, 对于某一特定的 QCI 特性, PDB对于上行和下行的取值是相同的。采用 PDB 的目的是为了支持对调度和链路层功能进行配置。
( 4) 分组丢失率( PLR) : 定义了由发送方链路层ARQ 协议处理的SDU 没有成功到达相应的接收方的比率。因此, PLR是一个非拥塞情况下的分组丢失情况。这个参数允许适当的链路层协议配置。对于某一特定的 QCI 特性, PLR对于上行和下行的取值是相同的。
2 、2G、 3G和 LTE/ SAE的 QoS比较
LTE/ SAE 承载等价于2G- GPRS 和 3G- UMT S标准中使用的“PDP上下文”,所以在与 2G和 3G的比较中, 重点比较 2G 对应的 R97/ 98 PDP 属性和 3G 对应的 R99 PDP 属性。其中 R97/ 98 PDP 属性是指3GPP标准Release 1997和 1998的 2G- GPRS 部分的分组数据协议( PDP)服务质量属性; R99 PDP 属性是指 3G- UMT S 和 2G- GPRS 在 3GPP 标准 Release99 的PDP服务质量属性。下表描述了不同版本标准的服务质量属性。
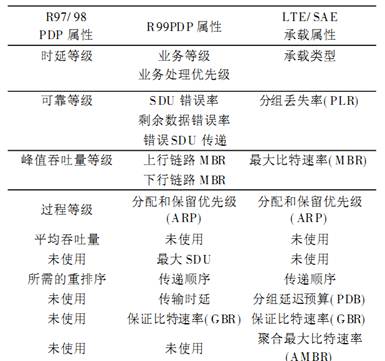
从上表可以看出, 3GPP的服务质量( QoS)是如何从2G发展到 3G最后演进到LTE/ SAE 的过程。
在2G- GPRS 的 R97/ 98 版本中, 语音是基于电路交换的, 电路连接建立后即可保证业务的服务质量,所以语音的QoS保证比较简单; 而 GPRS 采用的是分组交换方式, 由于 GSM 无线接口技术的限制, GPRS只能提供尽力而为的服务质量, 这种业务对传输时延和传输速率是没有任何保证的。
3G- UMT S 的 R99 版本, 在对 R97/ R98 版本的QoS 参数进一步细化的同时, 也增加了一些新参数, 比如前面提到的传输时延和传输速率, 其目的是: 对已有的和将要出现的所有电路和分组交换服务类型来说,网络的资源分配机制和调度算法要尽可能灵活。这一层面的灵活性和在UTRAN 中专用传输信道定义的所有可能选项是一致的。同时 R99 版本按业务流对时延的敏感程度不同定义了 4种 QoS 的业务类型: 会话类、 流类、 交互类和后台类, 每种类型都有相对应的QoS 具体属性和应用举例。
发展到R8 版本的LTE/SAE, 舍弃了电路交换,支持全IP网络, 服务质量( QoS)的表示相比 R99 版本更加简单。由于包括更少的属性域和预定义的标签, 所以减少了可能的组合数量; 通过保持不同制造商对相同类型服务的网络应用的一致性, 实现用户跨网络的无缝移动的体验; 通过预定义的默认承载, 缩短了业务建立的时延, 实现用户的 永远在线!的体验; 通过采用QCI 和预定义的承载类型( GBR或 Non- GBR) , 确定了不同类型的业务的 QoS 具体需求, 提供给用户高速且流畅的体验。
总结
LTE/SAE 系统是移动网络向全 IP 网络发展的重要一步, 为了满足其需求, LTE/ SAE 的 QoS 做了诸多的改进, 引入了许多新的概念: 比如简化了 UMTS 的承载架构, 发展成LTE/ SAE 的承载业务架构, 提出了默认承载、 专用承载、 GBR 承载和 Non- GBR承载等概念; 在描述 QoS 参数和属性时, 提出了 QCI 和AMBR等新概念。文章最后将LTE/ SAE 的QoS 与2G和3G 的QoS比较, 表明 LTE/ SAE给用户带来的体验的提高。随着 LTE 于 20## 年底在瑞典和挪威开始商用,移动通信网络进入了无线高速分组交换时代, 这将给LTE/ SAE 的QoS管理带来有益的探索, 比如LTE 与3GPP的 2G 或 3G 网络切换导致的 QoS 映射问题,LTE与 Non- 3GPP 网络切换导致的 QoS 映射问题等。
第二篇:qos学习总结
QOS学习总结(完整版)??????????(把学习当做一种生活,让你每天都在进步)?
这是我学了很长时间后的成果,拿出来与大家分享,如果有错误的地方还请大家见谅?并及时与我联系,大家一起进步??QQ?535918047?天空?
?
分类?
1. 集成的qos?主要是RSVP?
现在的rsvp很少单独使用了?主要是和mpls,一起做TE,在TE里rsvp主要负责分发标签(TE研究的还不深啊?呵呵~~~)?
2. 区分的QOS?
3. 分类的依据?
基于DSCP的分类?
快速转发?EF?推荐的DsCP值101110?相当于优先级5?
确定转发?AF?AF01‐AF04?相当于优先级1到4?
6和7留给网络系统和路由协议使用了?
dscp值?
***??***??**?
前三位和ip优先级相对应?中间3位做丢弃状况说明?
????????????????????????010???低丢弃?
????????????????????????100???中丢弃?
????????????????????????110???高丢弃(RED使用)?
最后2位可以做ECN?显示拥塞机制(RED使用)??
????10和01是同样的意思代表主机可以识别ecn字段??
????当网路发生拥塞的时候,如果路由器配置了ecn功能的话,路由器会把应该丢弃的包,置位为11,以通知主机发生了拥塞,主机识别拥塞,从而降低发送数据的速率?dscp值为全0,意味着路由器会尽力而为的转发数据?
CS(IP?precedence)?cs0‐7?兼容IP优先级?
?
?
tos字段????***??****??*?
????????前3位代表优先级?后四位代表延迟?开销之类的(实际中很少应用)?最后一位没有使用?
?
qos字段?只在本路由器内有用,不会对数据做任何标记??
?
?
cos是2层封装802.1q或ISL的优先级字段?
cos和dscp都可以和ip优先级有映射关系?
??
CAR?
1?承诺速率CAR?????用于在接口进行分类和限速?
CAR的令牌不是周期性的增加?而是连续的以一定速率的增加?采样点1/3000?S??
命令详解rate-limit {input | output}
参数
access-group 可以接访问控制列表进行定义
rate-limit 可以匹配优先级mac地址等 dscp 匹配dscp值进行限速
qos-group 匹配qos组进行限速 (qos不标记数据包)
Bits per second 基本速率 (CIR)
burst-normal burst-max 顺从突发速录 (Bc)NB 推荐值 等于cir/ 8)x1.5 默认的 Maximum burst bytes 最大突发速率 推荐值 等于bcX2 其中TC(时间间隔)= Bc/CIR
CAR?的推荐参数??BC=CIR/8*1.5?
????????????????BC单位为byte??CIR单位为bite??/8进行单位换算??
????????????????1.5是推荐的采样的点?
????????????????最大突发量=?BC*2?
conform-action 定义行为
continue 匹配下一个列表
drop 丢弃包
set-dscp-continue 设置dscp值
set-dscp-transmit 设置dscp值并传输
set-mpls-exp-imposition-continue 设置mpls标签并匹配下一个列表 set-mpls-exp-imposition-transmit
set-prec-continue
set-prec-transmit
set-qos-continue
set-qos-transmit 设置qos并传输
transmit 传输
exceed-action 定义扩展行为
定义速率列表
速录列表access‐list?rate‐limit?1?mask?07?
07包括0?,1,2三个优先级的字段?
优先级??????????掩码?
0???????????????00000001?
1???????????????00000010?
2???????????????00000100?
3???????????????00001000?
4???????????????00010000?
5???????????????00100000?
6???????????????01000000?
7???????????????10000000?
匹配0,1,2的掩码是0000111?
写成十六进制是?)0x07?
例:?
?接口下调用rate‐limit?access‐group?1?input?450000000?2000000?2000000?conform‐action?set‐prec‐transmit?5?execeed‐ation?set‐prec‐transmit?5?
?
?
CAR的令牌桶调度机制??单?桶?
|?
|?
|?
|?
|?
|?
|?
黑|?代表NB?正常突发量
?
红|?代表?丢弃的概率?
?
假设筒的bc?为48Kb??总大突发量为96?
速录范围????????????行为???????????动作?
?
小于48?KB???????????confim????????设置优先级为1?传送?
在48与96之间?????无法定义行为???随机丢弃?
大于96?????????????exceed?????????丢弃?
??
*动作是可以自己单独定义的?
?
?
?
?
?
?
?
?
?
?
策略路由PBR?
?(一般不建议用PBR策略路由对数据包进行分类)?
PBR只可以应用在入接口?
策略路由不基于任何动态路由协议,而是使用路由器中的本地静态配置。?PBR应用在接口下,只能处理入站方向的数据包和本地起源的数据包?PBR默认对于本地产生的流量不起作用,?
Ip?local?policy?route‐map?map‐name?
在全局模式下调用?对本地产生的数据包进行处理?
?
接口下调用?
int?f0/0?
ip?policy?route‐map?cisco、?
使用route‐map命令?
route‐map?cisco?
match?ip?address?1?
set?isp?precedence?5?
?
查看命令show?route‐map??
?????????Debug?ip?policy?
?
3使用Q?P?P?B??
(只在高级路由器上才可使用?e.g?7200)?
int?f0/0?
bgp?soure?ip‐prec‐map?
?
router?bgp?10?
table‐map?cisco?
?
route‐map?cisco?
match?ip?add?1?
set?ip?precedence?5?
access‐list?1___‐‐‐‐‐?
使用QPPB对QOS分组标记?(本地有效)?
int?f0/0?
bgp?source?ip‐qos‐map?
?
router?bgp?10?
table‐map?cisco?
route‐map?cisco?
match?ip?add?1?
set?ip?qos‐qroup?3?
access‐list?_____‐‐‐?
?
?
QOS?队列机制?
队列只可以作在出接口上,因为入接口没有缓存??
??
调度规则决定给流分配资源的方式?调度规则决定传输队列中的那个分组。?
?
?
最大?最小?公平份额的概念?
?????????????????????未被满足的用户将获得同样的份额,结果是应为公平分配,所以未
被满足的用户最大化?
最大?最小公平份额提供了一种绝对的公平机制,它确保了所有非空流都会被访问到,这种
机制由GPS?通用处理共享实现?
?
?????????????????????FQ公平队列?就是尽力模拟gps的行为??
一般情况下接口带宽可用为75%,剩下的25%保留给2层控制协议等作为预留带宽,不做生
产流量使用?可以再接口下使用命令?max‐reserved‐bandwidth?来更
该?
?
FIFO??????大于2M接口的默认排队机制??
先进先出?没有流的概念?也就没优先级的概念??
???????????FIFO中流获得的资源和源向网络发送数据的速度正比?
????
?
??
WFQ??and?CBWFQ?
定义:??区别对待不同流的调度规则?每个流会得到一个权重值,传输服务的频率与权重成
正比,WFQ为不同权重的值分配不同的优先级。?
?
调度机制?:?
WFQ是基于序列号的排队机制?序列号等于轮次+字节数?or?分组字节数+最大队列长度?
权重=8*4096/(ip优先级+1)?
?????????????权重与优先级成反比?权重越小数据包得到处理的机会就越大?
?????????????所以尽力而为的服务?ip的优先级为0?权重值为32768?最大权重?
权重?X字节数?用来模拟减小数据包的大小?来分配更多的资源?注意?权重?
越小分配的资源越多?权重与优先级成反比。??????
以上机制只有在接口发生拥塞(硬件接口队列满)时候才起作用,当硬件缓存没有满的时候用fifo排队机制。?
???????*??由于硬件缓存的先进先出机制可能影响到一些实时性强的应用有影响(增加延迟)?
所以可以适当调整硬件缓存??接口下?tx‐queue‐limit?
??WFQ中流的定义是根据哈希值来确定的??
?????????????????????哈希值是由五元素+tos中的5位但是不包括ip优先级来计算的,这
样的结果是同一个流内部是fifo机制的?以防止同一个流的数据包
的错序??对实时的数据是有益处的?。?
一般来说WFQ只丢弃最活跃流的数据包?最活跃的数据包的意思是指?丢弃那些数据量较
大的数据包。结果是tcp的全局同步没有fifo那样对WFQ中那样影
响。?
WFQ默认以活动的流为队列数,每一个流一个队列,默认最大256个队列?
????????????修改命令?
接口下???fair-queue??
???????????????????????????????????后面参数依次为?
丢弃门限(CDT)????????定义拥塞丢弃门限?
最大会话数????????定义最大会话,默认256?
保留会话数??????为RSVP保留的流数目?默认0?
?????????????????????Hold?queue?[queue?length]??out/in?定义队列长度?单位是数据包?
??show?queue??查看命令?
所有低于2M的的接口上默认是WFQ?
根据WFQ的排队机制所产生的结果是?
1. Ip优先级相同的流获得的带宽相同?
2. Ip优先级高的队列获得的处理几率就更多?多以分配的贷款
也就越多?
????????????????????????3.??每个流分配的贷款根据流的数量和优先级分配?
?
DWFQ?在基于多功能接口处理器(VIP)7500上实现的功能?
开启DWFQ必须要在接口上打开DCEF?
CBWFQ?最多可以分64个类?
max?total?最大总值=输出保持队列?也就是所有队列的缓存总和,可以再接口下用hold‐queue来进行修改。?
Threshold?门限?是单个会话允许的最大缓存。?
LLQ与CBWFQ?
??Policy‐map?name?
??Class?class‐name?
??Priority?bandwidth?为优先级队列预留带宽?
?
?
?
?
?
?
?
?
?
?
PQ??优先级队列??
优先级队列可以分为4个队列,分别是?高,?中,普通和低。?
没有分类的队列归类到普通队列?
缺点?:优先级队列有可能出现优先级霸占行为的产生,优先高的具有据对的有限权,以至
会影响优先级低的队列的传输。?
同一个优先级队列内是以FIFO排队的?
命令??
Priority‐list?1?potocol?ip?heig?list?101?
Access‐list?101?permit?ip?any?any??
Int?f0/0?
Priority‐group?1?
参数详解?
default??????Set?priority?queue?for?unspecified?datagrams?
把没有被定义的类分配到指定的优先级队列里?
??interface????Establish?priorities?for?packets?from?a?named?interface?
??把某个接口的流量分配到某个优先级对队列里?
??protocol?????priority?queueing?by?protocol?
??根据路由分配队列?
??queue‐limit??Set?queue?limits?for?priority?queues?
??为每个优先级分配队列限制?
?
?
?
?
?
CQ队列?
有16个队列?和一个特殊的系统队列0,0队列具有较高的优先级?每一个队列内部排队机制都是fifo?调度机制是轮训,但是她的轮训是基于数据包的也就是字节计数为100,那么队列里500的包也被发出去了?所以有可能带来不公平?要为每个队列的字节计数器?
例子??
Interface?f0/0?
Custom‐queue‐list?1?
Queue‐list?1?protocol?1?ip?1?tcp?telnet??
Queue‐list?1?protocol?2?ip?2?tcp?ftp?
分别把tcp的telnet?和ftp流量放入队列1和队列2?
?
?
Queue‐list?1?queue?1?byte‐count?2172?
Queue‐list?1?queue?2?byte‐count?6693?
分配队列字节计数器?队列计数器就是定义队列的深度?
?
Queue‐list?1?queue?3?limit?20???
定义这个队列放多少个包?
?
queue‐list?1?lowst‐custom?5??
这个的命令的意思是?前面1到5个队列为优先级队列?优先级次序分别是1最大?5最小优先级?6到16?为普通的CQ队列?
?
当应用一些实时的数据的时候可以把语音流量放入优先级较高的队列里面,但是当调度机制正在调取CQ队列的时候?某个优先级队列数据包到达了?要等调度机制完成后才可以调取优先级高的队列,所以要应用一些实时的数据的时候?不要把队列计数器调的过大?以防止延迟。优先级队列是绝对优先级队列是PQ行为?
?
查看命令?show?queueing?custom?
?
系统队列和普通队列之间的关系是严格优先级的关系?
?
?
?
?
?
?
LLQ??
???????语音流量要想获得严格的优先级流量?可以再接口下使用?
IP?rtp?priority?16384?16383?100K?端口号范围?预留带宽范围?
LLQ?只可以用于语音流量?
?
具有严格优先级的CBWFQ?
对基于流的WFQ中?启用上述名令相当于对语音流分配权重0(最大带宽)?
对基于CBWFQ的优先级队列中?也不能保证对语音流量的快速转发?因为受到调度机制的影
响?
????????????????例:?
???????????????????Policy‐map?voip?
???????????????????Class?voip?
???????????????????Priority?bandwitch?
??关键字priority定义优先级预留带宽?
?
?
?
?
MWRR?
?
RR?WRR?MWRR?
MWRR差错循环算法??
只有当差额计数器大于0是,队列才能获得服务?实际队列带宽=(队列权重*接口带宽)/所有活动队列的权重综合?当差额技术器为负的?将不会获得服务??
严格优先模式?
交替优先模式?
?
队列数随交换机平台的不同而不同?一般不会很大?3到4队??cos会和队列有一个映射关系?
show??mls?qos?int?f0/0?queueing?
cos‐?Qid?
0 1??
1 1?
2 2?
3 2?
4 3?
5 3?
6 4?
7 4?
全局??mls?qos??
??????开启mls?qos?开关?
??????Mls?qos?min‐reserve?1?20??
??为每个队列分配等级(长度)buffer?
等级有8个?默认等级buffer全部是100?
一个借口有4个队列,可为每个队列分配不同的等级?接口下?wrr‐queue?min‐seserve?2?2??
???????队列2?分配等级2??
??????Priority‐queue?out?
使队列4为优先级队列??
查看?show?mls?qos?interface?f0/1?queuing?
查看?show?mls?qos?int?f0/0?buffers?
?
Int?f0/0?
Wrr‐queue?cos‐map?做队列和cos的映射?
Wrr?–queue?bandwidth?25?25?25?25??
为每个队列分配带宽百分比?
?
接口下?wrr‐queueing?bandwidth?50?1?25?25?做队列和带宽的映射关系,队列1,2,3,4对应带宽分别是?百分之50?1?25?25?注意?1代表的意思是不占带宽。?
Show?mls?qos?int?f0/0?queueing?
?查看定义队列深度大小?
?接口下??mls?qos?queue‐limit?对应关系?定义队列深度?buffer?
查看?show?mls?qos?int?f0/0?buffer?
?
?
接口下??
Internet??e0/1?
Mls?qos?cos?5?
cos?值为5,即从此端口进来的报文如果不带cos?值,在端口ethernet?0/0/1?配置缺省则分配默认cos?值为5?
?
Mls?qos?trust?cos???
信任?接口流量的cos值?,不对其进行改变?
参数cos?pass‐through?dscp?配置端口信任cos?值,但是不更改包的dscp?值?
ip‐precedence?配置端口信任ip?优先级;?
dscp?pass‐through?cos?配置端口?信任dscp?值,但是不更改包的cos?值。?
?
Mls?qos?cos?overlay??
不信任接口的cos值?对其进行覆盖?覆盖后的cos值为0(优先级为0)?
Show?mls?qos?int?f0/0??
查看命令?
Show?mls?qos?maps?cos‐descp??
查看接口的cos‐dscp?映射关系?
Mls?qos?map?dscp‐cos??dscp?到cos映射?
全局下修改dscp‐cos的映射关系?
?
交换机的流量整形?
Mls?qos?aggregate‐police?name?CIR?BC?exceed‐ation?drop?
?
Policy‐map?name??
Policy下调用??
Class?name?
Police?aggregate?name?
接口下调用即可?
?
?
17.2.2.13 mls qos dscp-mutation
命令:mls qos dscp-mutation [dscp-mutation-name]
no mls qos dscp-mutation [dscp-mutation-name]
功能:在交换机端口上应用dscp 转换映射,本命令的no 操作为恢复dscp 转换映射的缺省值。
参数: [dscp-mutation-name] dscp 转换映射的名称。
缺省情况:缺省没有dscp 转换映射。
命令模式:端口配置模式
使用指南:在交换机端口配置dscp 转换映射,该端口的信任状态必须为trust dscp 才会生效,应用dscp 转换映射,可以使指定dscp 值不经过class 和policy 直接转换为新的dscp 值;应用到千兆端口的dscp 转换映射只对本端口有效;应用到百兆端口的dscp转换映射则存在一个作用范围,如果在1~8 号端口中的某个端口应用dscp 转换映射,这个dscp 转换映射对于1~8 号端口同时有效,在9~16 号端口中的某个端口应用dscp号端口有效,在17~24 号端口中的某个端口应用dscp 转换映射,它的作用范围是同时对17~24 号端口有效。
举例:在端口ethernet 0/0/1 上配置信任dscp,采用mu1 的dscp 转换映射。
switch(config)#interface ethernet 0/0/1
switch(config-ethernet0/0/1)#mls qos trust dscp pass-through cos
switch(config-ethernet0/0/1)#mls qos dscp-mutation mu1?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
Shaping?
?
流量整形只能应用在出接口,police即可应用在出接口,也可应用在入接口。??
流量整形?就是对数据包进行缓存,流量整形会增大延迟,减少抖动?
*流量整形这能用在输出接口上?
顺从最大突发量Bc?扩展突发量Be??
时间间隔T?
换算公式T=Bc/CIR?
CIR是许诺平均速录?
GTS?通用流量整形??
policy‐map?cisco?
class?cisco?
shape?average?256000???16384???0?
???????????????CIR????Bc????Be?
查看技术?show?int?shape?
流量整形是缓存后,在排队会降低数据的抖动,但会增大数据传输工程中的延迟,所以对一些实时的应用并不适合?
?
?
1. 将流量整形为256kb?(企业的出接口且购得的流量是256KB)?int?f0/0?
traffic‐shape?rate?256000?
查看命令?show?traffic‐shape?f0/0?
?
?
2. 分类的流量整形?
int?f0/0?
traffic‐shap?group?101?128000?
access‐list?101?tcp?ang?any??
?
3. 基于MQC?
policy‐map??
class?cisco?
shape?peak?128000?8192?1280????*?发送突发量Bc+Be?
???????????CIR???Bc???Be?
把输出流量整形为平均速率128kb?T=8192/128000=64ms?分组最大突发量等于BC+BE?8192+1280=9412位?
?
4. 依据ecn位进行流量整形的例子?
policy‐map?cisco?
class?cisco?
shape?average??256000?16384?1280??*不发送扩展突发量?只发送Bc?
shape?adaptive?64000?
通常以256kb的平均速录发送数据?当受到ecn置位的信息后以64kb的速率发送信息??
????????????????
?
?
帧中继的流量整形?
Map‐class?frame‐relay??name?
Frame‐relay?CIR?
接口下调用?
Interface?f0/0?
Frame‐relay?class?name?
(针对接口下所有pvc)?
设置帧中继?DE丢弃位?
全局下?frame‐relay?de‐list?3?(列表号)?protoacl?ip?ge?512??
数据帧大于512的DE位置位?
接口下调用?
Interface??f0/0?
Frame‐relay?de‐group?3(组号)?201(DLCI号)?
?
FECN?前向拥塞?
BECN?后向拥塞?
?
帧中继下的流量整形?
1??Class‐map?fram‐relay?name??
???Frame‐relay?adaptive‐shapint?becn?
帧中继根据收到的BECN?自动适配速率?
?Frame‐relay?fecn‐adapt?
??接口可识别并反射BECN?
Frame‐relay?mincir?设定Mincir?micir默认是CIR的一半?是有真正有保证的CIR?Frame‐relay?priority‐group?namber?
帧中继下调用优先级队列?
?
2?接口下?
??Frame‐relay?traffic‐shaping??
?帧中继接口开启流量整形功能?
?Frame‐relay?class?name??
?接口下调用class‐map?
Traffic‐shape?adaptive?320000?
?收到ECN后下降的最低流量?(默认下降一次)?
?
?
?
?
?Shaping令牌桶?
?
?
单筒?总容量=BC+BE???BC?正常突发量??BE?超额突发量?帧中继流量整形?
周期TC=0.25??(八分之一秒)?
CIR=BC/TC?
?
?
GTS?通用流量整形?
接口下?traffic‐shape?rate??[CIR??BC?BE??buffer]??
MQC??
基于类的流量shaping???
Policy‐map?name?
Class‐map?name?
Shape?average??CIR??BC?BE??
接口下调用?
查看?show?traffic‐shape?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
POLICE???
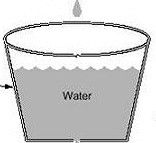
Car属于police的一种?car是单筒制?而police?属于双筒制
?
?
第一个桶代表BC??第二个桶?代表be???假设他们都是48KB?
一共96kb?桶的总深度?
?
速录范围????????????行为????????动作??
小于48?KB???????????confim??????设置优先级为1?在48与96之间??????exceed??????设置优先级为2?传送?大于96??????????????Violate??????丢弃???
配置?policy‐map?
Police??CIR??(bit)???BC?(byte)??BE?(byte)???????????PIR??峰值速率??BC+BE/Tc??
*如果不用violate参数?又恢复到cir的单筒制??
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
WRED?
?
?
传统的fifo是使用尾部丢弃机制?
尾部丢弃带来的问题?
???tcp的同步和tcp的饥饿?
为解决上述问题有效利用带宽??
引入了RED?or?WRED机制?用于防止拥塞的预先队列提前丢弃?
丢弃根据最小门限和最大门限?
最小门限开始丢包?丢包比率以至增大?知道超过组大门限?全部丢弃?
默认情况下所有优先级的最大门限都是相同的?但是最小门限随分组的优先级而异?优先级为0的通信默认最小门限是最大门限的一半?
优先级越高的数据包最小门限也就越高?
接口下random‐detect?命令启动WRED?
??????Randon‐?detect?dscp‐based?打开基于dscp的wred?
??????random‐detect?dscp?cs7?最小门限minimum?threshold??最大门限maximum?丢弃概率?查看?show?queueing?
?
WRED必须与FQ?WFQ?CBWFQ?结合使用?
?
RED计算队列的长度是基于加权的平局队列长度?而不是实际长度?
通过使用平局队列长度?RED避免了对网络中瞬间的突发做出反应,而对持久的拥塞做出反应?
平均队列长度=(以前的平均队列长度*(1‐1/2^n)+(当前的队列长度*1/2^n)?n是指权重因子?默认值是9?
n越大,旧队列长度对当前队列长度的重要性就越高??
n越小,当前队列长度相对于旧队列长度对平均队列长度的影响也就越大?标记几率丢弃分母?是当平均队列到达组大门限深度的时候?丢弃比率?
e.g?标记丢弃分母是10?当平局队列长度等于最大门限时,每10个包就有一个被丢弃??
e.g?基于类的WRED?
class‐map?cisco?
match?access‐group?101?
?
policy‐map?cisco?
class?cisco?
random‐detect?exponential‐weighting‐constant?9?设置权重值为9?默认为9?
random‐detect?precedence?0?112?375?1?优先级为0的最小丢弃门限为112?最大丢弃门限为375?丢弃分母比例为1?(到了最大门限后全部丢弃,尾丢弃)?
random‐detect?ecn?这个命令可以使路由器开启ecn功能,ecn功能通过置位11?来实现通知主机发生拥塞,从而降低发送速率,代替了丢弃,更友好。?
?
?
int?f0/0?
service‐policy?output?cisco?
对于udp这种非自适应流?WRED对这类流做了修订?以防止这类流对贷款的消耗?公式是?新的最大门限值=最小门限值+(最大门限‐最小门限)/2?
?
?
最小门限等于(1/2+i/18)x输出保持队列??
最大门限等于输出保持队列?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?经典案例研究研究1?
?
?
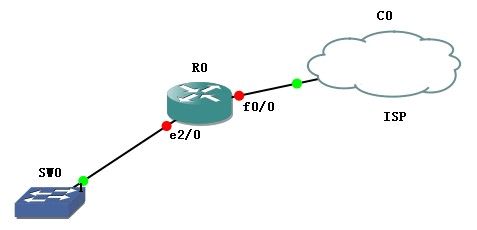
ISP现在在一条100M的链路上为客户提供30M的CIR服务?
客户的要求是所有www的流量在15M以内的要求优先级4,超过15M的要求优先级为0.其余的流量全部设置为4.?
ISP接客户的接口?
Intface?f0/0?
Rate‐limit?input?30000000?15000?15000?conform‐action?continue?exceed‐action?drop?
定义接口速录30M以内的传输?,超过30M的丢弃,其中关键字continue指定30M以内的数据匹配下个列表?
Rate‐limit?input?access‐group?101?150000000?10000?10000?conform‐action?set?–prec‐transmit?4?exceed‐action??set‐prec‐transmit?0?
Rate‐limit?input??150000000?10000?10000?conform‐action?set?–prec‐transmit?4?exceed‐action??set‐prec‐transmit?4?
Access‐list?101?per?tcp?any?an?eq?www?
Access‐list?101?per?tcp?any?eq?www?any?
查看命令show?int?f0/0?rate?
?
?
案例2?
层次化的策略应用?
应用一条错略要求限制链路上的tcp流量为10M,同时限制tcp流量中的telnetl流量为1M?Access‐list?101?per?tcp?any?any?
Access‐list?102?per?tcp?any?any?eq?telnet??
Class‐map??telnet??
Match?access‐group?101?
Class‐map??tcp?
Match???Access‐group?102?
Policy‐map?telnet??
Class?telnet?
Bandwitch?1000000?
Policy‐map?tcp‐telnet??
Class?tcp??
Bandwitch?10000000?
Service‐policy?telnet?
Int?f0/0?
Service‐policy?tcp‐telnet??
?
?
例3??
用MQC做速录限制??
对www的数据进行限速在8M?在8M以内设置优先级5并传递?对超过8M,超出了设置优先级4并传递,违背了丢弃?
正常突发量1.5M?
最大突发量1.3M?
Policy‐map?www?
Class?www?
Police?cir?8000000?bc?1500000?be?1300000?
conform‐action?set‐prec‐transmit?5?在8M以内设置为5?
exceed‐action?set‐prec‐transmit?4??在正常和最大突发量这件为4?
violate‐action?drop?超过了丢弃?
????
?
?
?
?
?
?
所有优先级队列强制预留贷款?
?