MYSQL支持事务吗?
在缺省模式下,MYSQL是autocommit模式的,所有的数据库更新操作都会即时提交,所以在缺省情况下,mysql是不支持事务的。
但是如果你的MYSQL表类型是使用InnoDB Tables 或 BDB tables的话,你的MYSQL就可以使用事务处理,使用SET AUTOCOMMIT=0就可以使MYSQL允许在非autocommit模式,在非autocommit模式下,你必须使用COMMIT来提交你的更改,或者用ROLLBACK来回滚你的更改。
示例如下:
START TRANSACTION;
SELECT @A:=SUM(salary) FROM table1 WHERE type=1;
UPDATE table2 SET summmary=@A WHERE type=1;
COMMIT;
MYSQL相比于其他数据库有哪些特点?
MySQL是一个小型关系型数据库管理系统,开发者为瑞典MySQL AB公司,现在已经 被Sun公司收购,支持FreeBSD、Linux、MAC、Windows等多种操作系统
与其他的大型数据库例如Oracle、DB2、SQL Server等相比功能稍弱一些
1、可以处理拥有上千万条记录的大型数据
2、支持常见的SQL语句规范
3、可移植行高,安装简单小巧
4、良好的运行效率,有丰富信息的网络支持
5、调试、管理,优化简单(相对其他大型数据库)
介绍一下mysql的日期和时间函数
这里是一个使用日期函数的例子。下面的查询选择所有 date_col 值在最后 30 天内的记录。 mysql> SELECT something FROM tbl_name
WHERE TO_DAYS(NOW()) – TO_DAYS(date_col) <= 30;
DAYOFWEEK(date)
返回 date 的星期索引(1 = Sunday, 2 = Monday, ... 7 = Saturday)。索引值符合 ODBC 的标准。
mysql> SELECT DAYOFWEEK(’1998-02-03');
-> 3
WEEKDAY(date)
返回 date 的星期索引(0 = Monday, 1 = Tuesday, ? 6 = Sunday):
mysql> SELECT WEEKDAY(’1998-02-03 22:23:00′);
-> 1
mysql> SELECT WEEKDAY(’1997-11-05′);
-> 2
DAYOFMONTH(date)
返回 date 是一月中的第几天,范围为 1 到 31:
mysql> SELECT DAYOFMONTH(’1998-02-03′);
-> 3
DAYOFYEAR(date)
返回 date 是一年中的第几天,范围为 1 到 366:
mysql> SELECT DAYOFYEAR(’1998-02-03′);
-> 34
MONTH(date)
返回 date 中的月份,范围为 1 到 12:
mysql> SELECT MONTH(’1998-02-03′);
-> 2
DAYNAME(date)
返回 date 的星期名:
mysql> SELECT DAYNAME(”1998-02-05″);
-> ?Thursday?
MONTHNAME(date)
返回 date 的月份名:
mysql> SELECT MONTHNAME(”1998-02-05″);
-> ?February?
QUARTER(date)
返回 date 在一年中的季度,范围为 1 到 4:
mysql> SELECT QUARTER(’98-04-01′);
-> 2
WEEK(date)
WEEK(date,first)
对于星期日是一周中的第一天的场合,如果函数只有一个参数调用,返回 date 为一年的第几周,返回值范围为 0 到 53 (是的,可能有第 53 周的开始)。两个参数形式的 WEEK() 允许你指定一周是否以星期日或星期一开始,以及返回值为 0-53 还是 1-52。这里的一个表显示第二个参数是如何工作的: 值 含义
0 一周以星期日开始,返回值范围为 0-53
1 一周以星期一开始,返回值范围为 0-53
2 一周以星期日开始,返回值范围为 1-53
3 一周以星期一开始,返回值范围为 1-53 (ISO 8601)
mysql> SELECT WEEK(’1998-02-20′);
-> 7
mysql> SELECT WEEK(’1998-02-20′,0);
-> 7
mysql> SELECT WEEK(’1998-02-20′,1);
-> 8
mysql> SELECT WEEK(’1998-12-31′,1);
-> 53
注意,在版本 4.0 中,WEEK(#,0) 被更改为匹配 USA 历法。 注意,如果一周是上一年的最后一周,当你没有使用 2 或 3 做为可选参数时,MySQL 将返回 0:
mysql> SELECT YEAR(’2000-01-01′), WEEK(’2000-01-01′,0);
-> 2000, 0
mysql> SELECT WEEK(’2000-01-01′,2);
-> 52
你可能会争辩说,当给定的日期值实际上是 1999 年的第 52 周的一部分时,MySQL 对 WEEK() 函数应该返回 52。我们决定返回 0 ,是因为我们希望该函数返回“在指定年份
中是第几周”。当与其它的提取日期值中的月日值的函数结合使用时,这使得 WEEK() 函数的用法可靠。如果你更希望能得到恰当的年-周值,那么你应该使用参数 2 或 3 做为可选参数,或者使用函数 YEARWEEK() :
mysql> SELECT YEARWEEK(’2000-01-01′);
-> 199952
mysql> SELECT MID(YEARWEEK(’2000-01-01′),5,2);
-> 52
YEAR(date)
返回 date 的年份,范围为 1000 到 9999:
mysql> SELECT YEAR(’98-02-03′);
-> 1998
YEARWEEK(date)
YEARWEEK(date,first)
返回一个日期值是的哪一年的哪一周。第二个参数的形式与作用完全与 WEEK() 的第二个参数一致。注意,对于给定的日期参数是一年的第一周或最后一周的,返回的年份值可能与日期参数给出的年份不一致:
mysql> SELECT YEARWEEK(’1987-01-01′);
-> 198653
注意,对于可选参数 0 或 1,周值的返回值不同于 WEEK() 函数所返回值(0), WEEK() 根据给定的年语境返回周值。
HOUR(time)
返回 time 的小时值,范围为 0 到 23:
mysql> SELECT HOUR(’10:05:03′);
-> 10
MINUTE(time)
返回 time 的分钟值,范围为 0 到 59:
mysql> SELECT MINUTE(’98-02-03 10:05:03′);
-> 5
SECOND(time)
返回 time 的秒值,范围为 0 到 59:
mysql> SELECT SECOND(’10:05:03′);
-> 3
PERIOD_ADD(P,N)
增加 N 个月到时期 P(格式为 YYMM 或 YYYYMM)中。以 YYYYMM 格式返回值。 注意,期间参数 P 不是 一个日期值:
mysql> SELECT PERIOD_ADD(9801,2);
-> 199803
PERIOD_DIFF(P1,P2)
返回时期 P1 和 P2 之间的月数。P1 和 P2 应该以 YYMM 或 YYYYMM 指定。 注意,时期参数 P1 和 P2 不是 日期值:
mysql> SELECT PERIOD_DIFF(9802,199703);
-> 11
DATE_ADD(date,INTERVAL expr type)
DATE_SUB(date,INTERVAL expr type)
ADDDATE(date,INTERVAL expr type)
SUBDATE(date,INTERVAL expr type)
这些函数执行日期的算术运算。ADDDATE() 和 SUBDATE() 分别是 DATE_ADD() 和 DATE_SUB() 的同义词。 在 MySQL 3.23 中,如果表达式的右边是一个日期值或一个日期时间型字段,你可以使用 + 和 – 代替 DATE_ADD() 和 DATE_SUB()(示例如下)。 参数 date 是一个 DATETIME 或 DATE 值,指定一个日期的开始。expr 是一个表达式,指定从开始日期上增加还是减去间隔值。expr 是一个字符串;它可以以一个 “-” 领头表示一个负的间隔值。type 是一个关键词,它标志着表达式以何格式被解释。 下表显示 type 和 expr 参数是如何关联的: type 值 expr 期望的格式
SECOND SECONDS
MINUTE MINUTES
HOUR HOURS
DAY DAYS
MONTH MONTHS
YEAR YEARS
MINUTE_SECOND “MINUTES:SECONDS”
HOUR_MINUTE “HOURS:MINUTES”
DAY_HOUR “DAYS HOURS”
YEAR_MONTH “YEARS-MONTHS”
HOUR_SECOND “HOURS:MINUTES:SECONDS”
DAY_MINUTE “DAYS HOURS:MINUTES”
DAY_SECOND “DAYS HOURS:MINUTES:SECONDS”
在 expr 的格式中,MySQL 允许任何字符作为定界符。表中所显示的是建议的定界字符。如果 date 参数是一个 DATE 值,并且计算的间隔仅仅有 YEAR、MONTH 和 DAY 部分(没有时间部分),那么返回值也是一个 DATE 值。否则返回值是一个 DATETIME 值: mysql> SELECT “1997-12-31 23:59:59″ + INTERVAL 1 SECOND;
-> 1998-01-01 00:00:00
mysql> SELECT INTERVAL 1 DAY + “1997-12-31″;
-> 1998-01-01
mysql> SELECT “1998-01-01″ – INTERVAL 1 SECOND;
-> 1997-12-31 23:59:59
mysql> SELECT DATE_ADD(”1997-12-31 23:59:59″,
-> INTERVAL 1 SECOND);
-> 1998-01-01 00:00:00
mysql> SELECT DATE_ADD(”1997-12-31 23:59:59″,
-> INTERVAL 1 DAY);
-> 1998-01-01 23:59:59
mysql> SELECT DATE_ADD(”1997-12-31 23:59:59″,
-> INTERVAL “1:1″ MINUTE_SECOND);
-> 1998-01-01 00:01:00
mysql> SELECT DATE_SUB(”1998-01-01 00:00:00″,
-> INTERVAL “1 1:1:1″ DAY_SECOND);
-> 1997-12-30 22:58:59
mysql> SELECT DATE_ADD(”1998-01-01 00:00:00″,
-> INTERVAL “-1 10″ DAY_HOUR);
-> 1997-12-30 14:00:00
mysql> SELECT DATE_SUB(”1998-01-02″, INTERVAL 31 DAY);
-> 1997-12-02
如果你指定了一个太短的间隔值(没有包括 type 关键词所期望的所有间隔部分),MySQL 假设你遗漏了间隔值的最左边部分。例如,如果指定一个 type 为 DAY_SECOND,那么 expr 值被期望包含天、小时、分钟和秒部分。如果你象 “1:10″ 样指定一个值,MySQL 假设天和小时部分被遗漏了,指定的值代表分钟和秒。换句话说,”1:10″ DAY_SECOND 被解释为等价于 “1:10″ MINUTE_SECOND。这类似于 MySQL 解释 TIME 值为经过的时间而不是一天的时刻。注意,如果依着包含一个时间部分的间隔增加或减少一个日期值,该日期值将被自动地转换到一个日期时间值:
mysql> SELECT DATE_ADD(”1999-01-01″, INTERVAL 1 DAY);
-> 1999-01-02
mysql> SELECT DATE_ADD(”1999-01-01″, INTERVAL 1 HOUR);
-> 1999-01-01 01:00:00
如果你使用了确定不正确的日期,返回结果将是 NULL。如果你增加 MONTH、YEAR_MONTH 或 YEAR,并且结果日期的天比新月份的最大天数还大,那么它将被调整到新月份的最大天数:
mysql> SELECT DATE_ADD(’1998-01-30′, INTERVAL 1 MONTH);
-> 1998-02-28
注意,上面的例子中,单词 INTERVAL 和关键词 type 是不区分字母大小写的。 EXTRACT(type FROM date)
EXTRACT() 函数使用与 DATE_ADD() 或 DATE_SUB() 一致的间隔类型,但是它用于指定从日期中提取的部分,而不是进行日期算术运算。
mysql> SELECT EXTRACT(YEAR FROM “1999-07-02″);
-> 1999
mysql> SELECT EXTRACT(YEAR_MONTH FROM “1999-07-02 01:02:03″);
-> 199907
mysql> SELECT EXTRACT(DAY_MINUTE FROM “1999-07-02 01:02:03″);
-> 20102
TO_DAYS(date)
给出一个日期 date,返回一个天数(从 0 年开始的天数):
mysql> SELECT TO_DAYS(950501);
-> 728779
mysql> SELECT TO_DAYS(’1997-10-07′);
-> 729669
TO_DAYS() 无意于使用先于格里高里历法(即现行的阳历)(1582)出现的值,因为它不考虑当历法改变时所遗失的天数。
FROM_DAYS(N)
给出一个天数 N,返回一个 DATE 值:
mysql> SELECT FROM_DAYS(729669);
-> ‘1997-10-07′
FROM_DAYS() 无意于使用先于格里高里历法(1582)出现的值,因为它不考虑当历法改变时所遗失的天数。
DATE_FORMAT(date,format)
依照 format 字符串格式化 date 值。下面的修饰符可被用于 format 字符串中: 修饰符 含义
%M 月的名字 (January..December)
%W 星期的名字 (Sunday..Saturday)
%D 有英文后缀的某月的第几天 (0th, 1st, 2nd, 3rd, etc.)
%Y 年份,数字的,4 位
%y 年份,数字的,2 位
%X 周值的年份,星期日是一个星期的第一天,数字的,4 位,与 ‘%V’ 一同使用 %x 周值的年份,星期一是一个星期的第一天,数字的,4 位,与 ‘%v’ 一同使用 %a 缩写的星期名 (Sun..Sat)
%d 月份中的天数,数字的 (00..31)
%e 月份中的天数,数字的 (0..31)
%m 月,数字的 (00..12)
%c 月,数字的 (0..12)
%b 缩写的月份名 (Jan..Dec)
%j 一年中的天数 (001..366)
%H 小时 (00..23)
%k 小时 (0..23)
%h 小时 (01..12)
%I 小时 (01..12)
%l 小时 (1..12)
%i 分钟,数字的 (00..59)
%r 时间,12 小时 (hh:mm:ss [AP]M)
%T 时间,24 小时 (hh:mm:ss)
%S 秒 (00..59)
%s 秒 (00..59)
%p AM 或 PM
%w 一周中的天数 (0=Sunday..6=Saturday)
%U 星期 (00..53),星期日是一个星期的第一天
%u 星期 (00..53),星期一是一个星期的第一天
%V 星期 (01..53),星期日是一个星期的第一天。与 ‘%X’ 一起使用
%v 星期 (01..53),星期一是一个星期的第一天。与 ‘%x’ 一起使用
%% 一个字母 “%”
所有其它的字符不经过解释,直接复制到结果中:
mysql> SELECT DATE_FORMAT(’1997-10-04 22:23:00′, ‘%W %M %Y’);
-> ‘Saturday October 1997′
mysql> SELECT DATE_FORMAT(’1997-10-04 22:23:00′, ‘%H:%i:%s’);
-> ‘22:23:00′
mysql> SELECT DATE_FORMAT(’1997-10-04 22:23:00′,
‘%D %y %a %d %m %b %j?);
-> ‘4th 97 Sat 04 10 Oct 277′
mysql> SELECT DATE_FORMAT(’1997-10-04 22:23:00′,
‘%H %k %I %r %T %S %w?);
-> ‘22 22 10 10:23:00 PM 22:23:00 00 6′
mysql> SELECT DATE_FORMAT(’1999-01-01′, ‘%X %V’);
-> ‘1998 52′
在 MySQL 3.23 中,在格式修饰符前需要字符 `%’。在更早的 MySQL 版本中,`%’ 是可选的。 月份与天修饰符的范围从零开始的原因是,在 MySQL 3.23 中,它允许存储不完善的日期值(例如 ‘2004-00-00′)。
TIME_FORMAT(time,format)
它的使用方法与上面的 DATE_FORMAT() 函数相似,但是 format 字符串只包含处理小时、分和秒的那些格式修饰符。使用其它的修饰符会产生一个 NULL 值或 0。
CURDATE()
CURRENT_DATE
以 ‘YYYY-MM-DD’ 或 YYYYMMDD 格式返回当前的日期值,返回的格式取决于该函数是用于字符串还是数字语境中:
mysql> SELECT CURDATE();
-> ‘1997-12-15′
mysql> SELECT CURDATE() + 0;
-> 19971215
CURTIME()
CURRENT_TIME
以 ‘HH:MM:SS’ 或 HHMMSS 格式返回当前的时间值,返回的格式取决于该函数是用于字符串还是数字语境中:
mysql> SELECT CURTIME();
-> ‘23:50:26′
mysql> SELECT CURTIME() + 0;
-> 235026
NOW()
SYSDATE()
CURRENT_TIMESTAMP
以 ‘YYYY-MM-DD HH:MM:SS’ 或 YYYYMMDDHHMMSS 格式返回当前的日期时间值,返回的格式取决于该函数是用于字符串还是数字语境中:
mysql> SELECT NOW();
-> ‘1997-12-15 23:50:26′
mysql> SELECT NOW() + 0;
-> 19971215235026
注意,函数 NOW() 在每个查询中只计算一次,也就是在查询开始执行时。这就是说,如果在一个单独的查询中多次引用了 NOW(),它只会给出值都是一个相同的时间。 UNIX_TIMESTAMP()
UNIX_TIMESTAMP(date)
如果调用时没有参数,以无符号的整数形式返回一个 Unix 时间戳(从 ‘1970-01-01 00:00:00′ GMT 开始的秒数)。如果以一个参数 date 调用 UNIX_TIMESTAMP(),它将返回该参数值从 ‘1970-01-01 00:00:00′ GMT 开始经过的秒数值。date 可以是一个 DATE 字符串,一个 DATETIME 字符串,一个 TIMESTAMP,或者以一个 YYMMDD 或 YYYYMMDD 显示的本地时间:
mysql> SELECT UNIX_TIMESTAMP();
-> 882226357
mysql> SELECT UNIX_TIMESTAMP(’1997-10-04 22:23:00′);
-> 875996580
当 UNIX_TIMESTAMP 被用于一个 TIMESTAMP 列时,函数直接返回一个内部的时间戳值,而不进行一个隐含地 “string-to-unix-timestamp” 转换。如果你传递一个超出范围的日期参数给 UNIX_TIMESTAMP() ,它将返回 0,但是请注意,MySQL 对其仅仅进行基本的检验(年范围 1970-2037,月份 01-12,日期 01-31)。 如果你希望减去 UNIX_TIMESTAMP() 列,你应该需要将结果强制转换为一有符号整数。查看章节 6.3.5 Cast 函数。
FROM_UNIXTIME(unix_timestamp [,format])
以 ‘YYYY-MM-DD HH:MM:SS’ 或 YYYYMMDDHHMMSS 格式返回一个 unix_timestamp 参数值,返回值的形式取决于该函数使用于字符串还是数字语境。 如果 format 给出,返回值依 format 字符串被格式。format 可以包含与 DATE_FORMAT() 函数同样的修饰符。
mysql> SELECT FROM_UNIXTIME(875996580);
-> ‘1997-10-04 22:23:00′
mysql> SELECT FROM_UNIXTIME(875996580) + 0;
-> 19971004222300
mysql> SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),
‘%Y %D %M %h:%i:%s %x?);
-> ‘1997 23rd December 03:43:30 1997′
SEC_TO_TIME(seconds)
以 ‘HH:MM:SS’ 或 HHMMSS 格式返回参数 seconds 被转换到时分秒后的值,返回值的形式取决于该函数使用于字符串还是数字语境:
mysql> SELECT SEC_TO_TIME(2378);
-> ‘00:39:38′
mysql> SELECT SEC_TO_TIME(2378) + 0;
-> 3938
TIME_TO_SEC(time)
将参数 time 转换为秒数后返回:
mysql> SELECT TIME_TO_SEC(’22:23:00′);
-> 80580
mysql> SELECT TIME_TO_SEC(’00:39:38′);
-> 2378
如何解决MYSQL数据库中文乱码问题?
在数据库安的时候指定字符集
如果在安完了以后可以更改以下文件:
C:\Program Files\MySQL\MySQL Server 5.0\my.ini
里的所有的 default-character-set=gbk
C:\Program Files\MySQL\MySQL Server 5.0\data\depot_development\db.opt
default-character-set=gbk
default-collation=gbk_chinese_ci
建立数据库时候:指定字符集类型
CREATE DATABASE haichen
CHARACTER SET ?gbk?
COLLATE ?gbk_chinese_ci?;
2.建表的时候 也指定字符集
CREATE TABLE student (
ID varchar(40) NOT NULL default ”,
UserID varchar(40) NOT NULL default ”,
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
————————————————————————————————————-
1。创建数据库的时候:CREATE DATABASE `database`
CHARACTER SET ‘utf8′
COLLATE ?utf8_general_ci?;
2.建表的时候 CREATE TABLE `database_user` (
`ID` varchar(40) NOT NULL default ”,
`UserID` varchar(40) NOT NULL default ”,
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.设置URL的时候
jdbc:mysql://localhost:3306/database?useUnicode=true&characterEncoding=UTF-8
如何提高MySql的安全性?
1.如果MYSQL客户端和服务器端的连接需要跨越并通过不可信任的网络,那么需要使用ssh隧道来加密该连接的通信。
2.使用set password语句来修改用户的密码,先“mysql -u root”登陆数据库系统,然后“mysql> update mysql.user set password=password(’newpwd’)”,最后执行“flush privileges”就可以了。
3.Mysql需要提防的攻击有,防偷听、篡改、回放、拒绝服务等,不涉及可用性和容错方面。对所有的连接、查询、其他操作使用基于acl即访问控制列表的安全措施来完成。也有一些对ssl连接的支持。
4.设置除了root用户外的其他任何用户不允许访问mysql主数据库中的user表;
加密后存放在user表中的加密后的用户密码一旦泄露,其他人可以随意用该用户名/密码相应的数据库;
5.使用grant和revoke语句来进行用户访问控制的工作;
6.不要使用明文密码,而是使用md5()和sha1()等单向的哈系函数来设置密码;
7.不要选用字典中的字来做密码;
8.采用防火墙可以去掉50%的外部危险,让数据库系统躲在防火墙后面工作,或放置在dmz区域中;
9.从因特网上用nmap来扫描3306端口,也可用telnet server_host 3306的方法测试,不允许从非信任网络中访问数据库服务器的3306号tcp端口,需要在防火墙或路由器上做设定;
10.为了防止被恶意传入非法参数,例如where id=234,别人却输入where id=234 or 1=1导致全部显示,所以在web的表单中使用”或”"来用字符串,在动态url中加入%22代表双引号、%23代表井号、%27代表单引号;传递未检查过的值给mysql数据库是非常危险的;
11.在传递数据给mysql时检查一下大小;
12.应用程序需要连接到数据库应该使用一般的用户帐号,开放少数必要的权限给该用户; $page_devide$
13.在各编程接口(c c++ php perl java jdbc等)中使用特定‘逃脱字符’函数;
在因特网上使用mysql数据库时一定少用传输明文的数据,而用ssl和ssh的加密方式数据来传输;
14.学会使用tcpdump和strings工具来查看传输数据的安全性,例如tcpdump -l -i eth0 -w -src or dst port 3306 strings。以普通用户来启动mysql数据库服务;
15.不使用到表的联结符号,选用的参数 –skip-symbolic-links;
16.确信在mysql目录中只有启动数据库服务的用户才可以对文件有读和写的权限;
MYSQL面试题:简单叙述一下MYSQL的优化
1.数据库的设计
尽量把数据库设计的更小的占磁盘空间.
1).尽可能使用更小的整数类型.(mediumint就比int更合适).
2).尽可能的定义字段为not null,除非这个字段需要null.
3).如果没有用到变长字段的话比如varchar,那就采用固定大小的纪录格式比如char.
4).表的主索引应该尽可能的短.这样的话每条纪录都有名字标志且更高效.
5).只创建确实需要的索引。索引有利于检索记录,但是不利于快速保存记录。如果总是要在表的组合字段上做搜索,那么就在这些字段上创建索引。索引的第一部分必须是最常使用的字段.如果总是需要用到很多字段,首先就应该多复制这些字段,使索引更好的压缩。
6).所有数据都得在保存到数据库前进行处理。
7).所有字段都得有默认值。
8).在某些情况下,把一个频繁扫描的表分成两个速度会快好多。在对动态格式表扫描以取得相关记录时,它可能使用更小的静态格式表的情况下更是如此。
2.系统的用途
1).尽量使用长连接.
2).explain 复杂的SQL语句。
3).如果两个关联表要做比较话,做比较的字段必须类型和长度都一致.
4).LIMIT语句尽量要跟order by或者 distinct.这样可以避免做一次full table scan.
5).如果想要清空表的所有纪录,建议用truncate table tablename而不是delete from tablename.
3.系统的瓶颈
1).磁盘搜索.
并行搜索,把数据分开存放到多个磁盘中,这样能加快搜索时间.
2).磁盘读写(IO)
可以从多个媒介中并行的读取数据。
3).CPU周期
数据存放在主内存中.这样就得增加CPU的个数来处理这些数据。
4).内存带宽
当CPU要将更多的数据存放到CPU的缓存中来的话,内存的带宽就成了瓶颈.
如何写出高质量、高性能的MySQL查询
下面就某些SQL语句的where子句编写中需要注意的问题作详细介绍。在这些where子句
中,即使某些列存在索引,但是由于编写了劣质的SQL,系统在运行该SQL语句时也不能使用该索引,而同样使用全表扫描,这就造成了响应速度的极大降低。
1. IS NULL 与 IS NOT NULL
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。
任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
2. 联接列
对于有联接的列,即使最后的联接值为一个静态值,优化器是不会使用索引的。我们一起 来看一个例子,假定有一个职工表(employee),对于一个职工的姓和名分成两列存放(FIRST_NAME和LAST_NAME),现在要查询一个 叫比尔.克林顿(Bill Cliton)的职工。

对基于last_name创建的索引没有使用。
当采用下面这种SQL语句的编写,Oracle

系统就可以采用基于last_name创建的索引。 遇到下面这种情况又如何处理呢?如果一个变量(name)中存放着Bill Cliton这个员工的姓名,对于这种情况我们又如何避免全程遍历,使用索引呢?可以使用一个函数,将变量name中的姓和名分开就可以了,但是有一点需 要注意,这个函数是不能作用在索引列上。下面是SQL查询脚本:
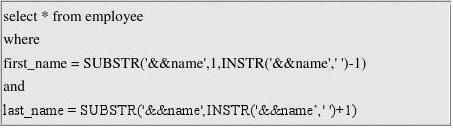

同样以上面的例子来看这种情况。目前的需求是这样的,要求在职工表中查询名字中包含这里由于通配符(%)在搜寻词首出现,所以Oracle系统不使用last_name的索 引。在很多

情况下可能无法避免这种情况,但是一定要心中有底,通配符如此使用会降低查询速度。然而当通配符出现在字符串其他位置时,优化器就能利用索引。 在下面的查询中索引得到了使用:
4. Order by语句
ORDER BY语句决定了Oracle如何将返回的查询结果排序。Order by语句对要排序的列没有什么特别的限制,也可以将函数加入列中(象联接或者附加等)。任何在Order by语句的
非索引项或者有计算表达式都将降低查询速度。
仔细检查order by语句以找出非索引项或者表达式,它们会降低性能。解决这个问题的办法就是重写order by语句以使用索引,也可以为所使用的列建立另外一个索引,同时应绝对避免在order by子句中使用表达式。
5. NOT
我们在查询时经常在where子句使用一些逻辑表达式,如大于、小于、等于以及不等于等等,也可以使用and(与)、or(或)以及not(非)。NOT可用来对任何逻辑运算符号取反。下面是一个NOT子句的例子:
… where not (status =?VALID?)
如果要使用NOT,则应在取反的短语前面加上括号,并在短语前面加上NOT运算符。NOT运算符包含在另外一个逻辑运算符中,这就是不等于(<>)运算符。换句话说,即使不在查询where子句中显式地加入NOT词,NOT仍在运算符中,见下例:
… where status <>?INVALID?
再看下面这个例子:
select * from employee where salary<>3000;
对这个查询,可以改写为不使用NOT:
select * from employee where salary<3000 or salary>3000;
虽然这两种查询的结果一样,但是第二种查询方案会比第一种查询方案更快些。第二种查询允许Oracle对salary列使用索引,而第一种查询则不能使用索引。
6. IN和EXISTS
有时候会将一列和一系列值相比较。最简单的办法就是在where子句中使用子查询。在where子句中可以使用两种格式的子查询。
第一种格式是使用IN操作符:
… where column in(select * from … where …);
第二种格式是使用EXIST操作符:
… where exists (select ?X? from …where …);
我相信绝大多数人会使用第一种格式,因为它比较容易编写,而实际上第二种格式要远比第一种格式的效率高。在Oracle中可以几乎将所有的IN操作符子查询改写为使用EXISTS的子查询。
第二种格式中,子查询以?select ?X?开始。运用EXISTS子句不管子查询从表中抽取什么数据它只查看where子句。这样优化器就不必遍历整个表而仅根据索引就可完成工作(这里假定在where语句中使用的列存在索引)。相对于IN子句来说,EXISTS使用相连子查询,构造起来要比IN子查询困难一些。
通过使用EXIST,Oracle系统会首先检查主查询,然后运行子查询直到它找到第一个匹配项,这就节省了时间。Oracle系统在执行IN子查询时,首先执行子查询,并将获得的结果列表存放在在一个加了索引的临时表中。在执行子查询之前,系统先将主查询挂起,待子查询执行完毕,存放在临时表中以后再执行主查询。这也就是使用EXISTS比使用IN通常查询速度快的原因。
同时应尽可能使用NOT EXISTS来代替NOT IN,尽管二者都使用了NOT(不能使用索引而降低速度),NOT EXISTS要比NOT IN查询效率更高。