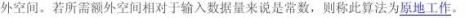数据结构复习重点归纳
一、数据结构的章节结构及重点构成
数据结构学科的章节划分基本上为:概论,线性表,栈和队列,串,多维数组和广义表,树和二叉树,图,查找,内排,外排,文件,动态存储分配。
对于绝大多数的学校而言,“外排,文件,动态存储分配”三章基本上是不考的,在大多数高校的计算机本科教学过程中,这三章也是基本上不作讲授的。所以,大家在这三章上可以不必花费过多的精力,只要知道基本的概念即可。但是,对于报考名校特别是该校又有在试卷中对这三章进行过考核的历史,那么这部分朋友就要留意这三章了。 按照以上我们给出的章节以及对后三章的介绍,数据结构的章节比重大致为: 概论:内容很少,概念简单,分数大多只有几分,有的学校甚至不考。
线性表:基础章节,必考内容之一。考题多数为基本概念题,名校考题中,鲜有大型算法设计题。如果有,也是与其它章节内容相结合。
栈和队列:基础章节,容易出基本概念题,必考内容之一。而栈常与其它章节配合考查,也常与递归等概念相联系进行考查。
串 :基础章节,概念较为简单。专门针对于此章的大型算法设计题很少,较常见的是根据KMP进行算法分析。
多维数组及广义表 :基础章节,基于数组的算法题也是常见的,分数比例波动较大,是出题的“可选单元”或“侯补单元”。一般如果要出题,多数不会作为大题出。数组常与“查找,排序”等章节结合来作为大题考查。
树和二叉树 :重点难点章节,各校必考章节。各校在此章出题的不同之处在于,是否在本章中出一到两道大的算法设计题。通过对多所学校的试卷分析,绝大多数学校在本章都曾有过出大型算法设计题的历史。
图 :重点难点章节,名校尤爱考。如果作为重点来考,则多出现于分析与设计题型当中,可与树一章共同构成算法设计大题的题型设计。
查找 :重点难点章节,概念较多,联系较为紧密,容易混淆。出题时可以作为分析型题目给出,在基本概念型题目中也较为常见。算法设计型题中可以数组结合来考查,也可以与树一章结合来考查。
排序 :与查找一章类似,本章同属于重点难点章节,且概念更多,联系更为紧密,概念之间更容易混淆。在基本概念的考查中,尤爱考各种排序算法的优劣比较此类的题。算法设计大题中,如果作为出题,那么常与数组结合来考查。
二、数据结构各章节重点勾划:
第0章 概述
本章主要起到总领作用,为读者进行数据结构的学习进行了一些先期铺垫。大家主要注意以下几点:数据结构的基本概念,时间和空间复杂度的概念及度量方法,算法设计时的注意事项。本章考点不多,只要稍加注意理解即可。
第一章 线性表
作为线性结构的开篇章节,线性表一章在线性结构的学习乃至整个数据结构学科的学习中,其作用都是不可低估的。在这一章,第一次系统性地引入链式存储的概念,链式存储概念将是整个数据结构学科的重中之重,无论哪一章都涉及到了这个概念。
总体来说,线性表一章可供考查的重要考点有以下几个方面:
1.线性表的相关基本概念,如:前驱、后继、表长、空表、首元结点,头结点,头指针等概念。
2.线性表的结构特点,主要是指:除第一及最后一个元素外,每个结点都只有一个前趋和只有一个后继。
3.线性表的顺序存储方式及其在具体语言环境下的两种不同实现:表空间的静态分配和动态分配。静态链表与顺序表的相似及不同之处。
4.线性表的链式存储方式及以下几种常用链表的特点和运算:单链表、循环链表,双向链表,双向循环链表。其中,单链表的归并算法、循环链表的归并算法、双向链表及双向循环链表的插入和删除算法等都是较为常见的考查方式。此外,近年来在不少学校中还多次出现要求用递归算法实现单链表输出(可能是顺序也可能是倒序)的问题。
在链表的小题型中,经常考到一些诸如:判表空的题。在不同的链表中,其判表空的方式是不一样的,请大家注意。
5.线性表的顺序存储及链式存储情况下,其不同的优缺点比较,即其各自适用的场合。单链表中设置头指针、循环链表中设置尾指针而不设置头指针以及索引存储结构的各自好处。
第二章 栈与队列
栈与队列,是很多学习DS的同学遇到第一只拦路虎,很多人从这一章开始坐晕车,一直晕到现在。所以,理解栈与队列,是走向DS高手的一条必由之路,。
学习此章前,你可以问一下自己是不是已经知道了以下几点:
1.栈、队列的定义及其相关数据结构的概念,包括:顺序栈,链栈,共享栈,循环队列,链队等。栈与队列存取数据(请注意包括:存和取两部分)的特点。
2.递归算法。栈与递归的关系,以及借助栈将递归转向于非递归的经典算法:n!阶乘问题,fib数列问题,hanoi问题,背包问题,二叉树的递归和非递归遍历问题,图的深度遍历与栈的关系等。其中,涉及到树与图的问题,多半会在树与图的相关章节中进行考查。
3.栈的应用:数值表达式的求解,括号的配对等的原理,只作原理性了解,具体要求考查此为题目的算法设计题不多。
4.循环队列中判队空、队满条件,循环队列中入队与出队算法。
如果你已经对上面的几点了如指掌,栈与队列一章可以不看书了。注意,我说的是可以不看书,并不是可以不作题哦。
第三章 串
经历了栈一章的痛苦煎熬后,终于迎来了串一章的柳暗花明。
串,在概念上是比较少的一个章节,也是最容易自学的章节之一,但正如每个过来人所了解的,KMP算法是这一章的重要关隘,突破此关隘后,走过去又是一马平川的大好DS山河了,呵呵。
串一章需要攻破的主要堡垒有:
1.串的基本概念,串与线性表的关系(串是其元素均为字符型数据的特殊线性表),空串与空格串的区别,串相等的条件
2.串的基本操作,以及这些基本函数的使用,包括:取子串,串连接,串替换,求串长等等。运用串的基本操作去完成特定的算法是很多学校在基本操作上的考查重点。
3.顺序串与链串及块链串的区别和联系,实现方式。
4.KMP算法思想。KMP中next数组以及nextval数组的求法。明确传统模式匹配算法的不足,明确next数组需要改进之外。其中,理解算法是核心,会求数组是得分点。不用我多说,这一节内容是本章的重中之重。可能进行的考查方式是:求next和nextval数组值,根据求得的next或nextval数组值给出运用KMP算法进行匹配的匹配过程。
第四章 数组与广义表
学过程序语言的朋友,数组的概念我们已经不是第一次见到了,应该已经“一回生,二回熟”了,所以,在概念上,不会存在太大障碍。但作为考研课程来说,本章的考查重点可能与大学里的程序语言所关注的不太一样,下面会作介绍。
广义表的概念,是数据结构里第一次出现的。它是线性表或表元素的有限序列,构成该结构的每个子表或元素也是线性结构的,所以,这一章也归入线性结构中。
本章的考查重点有:
1.多维数组中某数组元素的position求解。一般是给出数组元素的首元素地址和每个元素占用的地址空间并组给出多维数组的维数,然后要求你求出该数组中的某个元素所在的位置。
2.明确按行存储和按列存储的区别和联系,并能够按照这两种不同的存储方式求解1中类型的题。
3.将特殊矩阵中的元素按相应的换算方式存入数组中。这些矩阵包括:对称矩阵,三角矩阵,具有某种特点的稀疏矩阵等。熟悉稀疏矩阵的三种不同存储方式:三元组,带辅助行向量的二元组,十字链表存储。掌握将稀疏矩阵的三元组或二元组向十字链表进行转换的算法。
4.广义表的概念,特别应该明确表头与表尾的定义。这一点,是理解整个广义表一节算法的基础。近来,在一些学校中,出现了这样一种题目类型:给出对某个广义表L若干个求了若干次的取头和取尾操作后的串值,要求求出原广义表L。大家要留意。
5.与广义表有关的递归算法。由于广义表的定义就是递归的,所以,与广义表有关的算法也常是递归形式的。比如:求表深度,复制广义表等。这种题目,可以根据不同角度广义表的表现形式运用两种不同的方式解答:一是把一个广义表看作是表头和表尾两部分,分别对表头和表尾进行操作;二是把一个广义表看作是若干个子表,分别对每个子表进行操作。
第五章 树与二叉树
从对线性结构的研究过度到对树形结构的研究,是数据结构课程学习的一次跃变,此次跃变完成的好坏,将直接关系到你到实际的考试中是否可以拿到高分,而这所有的一切,将最终影响你的专业课总分。所以,树这一章的重要性,已经不说自明了。
总体来说,树一章的知识点包括:
二叉树的概念、性质和存储结构,二叉树遍历的三种算法(递归与非递归),在三种基本遍历算法的基础上实现二叉树的其它算法,线索二叉树的概念和线索化算法以及线索化后的查找算法,最优二叉树的概念、构成和应用,树的概念和存储形式,树与森林的遍历算法及其与二叉树遍历算法的联系,树与森林和二叉树的转换。
下面我们看一下图这一章的主要考点以及这些考点的考查方式:
1.考查有关图的基本概念问题:
这些概念是进行图一章学习的基础,这一章的概念包括:图的定义和特点,无向图,有向图,入度,出度,完全图,生成子图,路径长度,回路,(强)连通图,(强)连通分量等概念。与这些概念相联系的相关计算题也应该掌握。
2.考查图的几种存储形式:
图的存储形式包括:邻接矩阵,(逆)邻接表,十字链表及邻接多重表。在考查时,有的学校是给出一种存储形式,要求考生用算法或手写出与给定的结构相对应的该图的另一种存储形式。
3.考查图的两种遍历算法:深度遍历和广度遍历
深度遍历和广度遍历是图的两种基本的遍历算法,这两个算法对图一章的重要性等同于“先序、中序、后序遍历”对于二叉树一章的重要性。在考查时,图一章的算法设计题常常是基于这两种基本的遍历算法而设计的,比如:“求最长的最短路径问题”和“判断两顶点间是否存在长为K的简单路径问题”,就分别用到了广度遍历和深度遍历算法。
4.生成树、最小生成树的概念以及最小生成树的构造:PRIM算法和KRUSKAL算法。
考查时,一般不要求写出算法源码,而是要求根据这两种最小生成树的算法思想写出其构造过程及最终生成的最小生成树。
5.拓扑排序问题:
拓扑排序有两种方法,一是无前趋的顶点优先算法,二是无后继的顶点优先算法。换句话说,一种是“从前向后”的排序,一种是“从后向前”排。当然,后一种排序出来的结果是“逆拓扑有序”的。
6.关键路径问题:
这个问题是图一章的难点问题。理解关键路径的关键有三个方面:一是何谓关键路径,二是最早时间是什么意思、如何求,三是最晚时间是什么意思、如何求。简单地说,最早时间是通过“从前向后”的方法求的,而最晚时间是通过“从后向前”的方法求解的,并且,要想求最晚时间必须是在所有的最早时间都已经求出来之后才能进行。这个问题拿来直接考算法源码的不多,一般是要求按照书上的算法描述求解的过程和步骤。
在实际设计关键路径的算法时,还应该注意以下这一点:采用邻接表的存储结构,求最早时间和最晚时间要采用不同的处理方法,即:在算法初始时,应该首先将所有顶点的最早时间全部置为0。关键路径问题是工程进度控制的重要方法,具有很强的实用性。
7.最短路径问题: 与关键路径问题并称为图一章的两只拦路虎。概念理解是比较容易的,关键是算法的理解。最短路径问题分为两种:一是求从某一点出发到其余各点的最短路径;二是求图中每一对顶点之间的最短路径。这个问题也具有非常实用的背景特色,一个典型的应该就是旅游景点及旅游路线的选择问题。解决第一个问题用DIJSKTRA算法,解决第二个问题用FLOYD算法。注意区分。
第七章 查找
在不少数据结构的教材中,是把查找与排序放入高级数据结构中的。应该说,查找和排序两章是前面我们所学的知识的综合运用,用到了树、也用到了链表等知识,对这些数据结构某一方面的运用就构成了查找和排序。
现实生活中,search几乎无处不在,特别是现在的网络时代,万事离不开search,小到文档内文字的搜索,大到INTERNET上的搜索,search占据了我们上网的大部分时间。
在复习这一章的知识时,你需要先弄清楚以下几个概念: 关键字、主关键字、次关键字的含义;静态查找与动态查找的含义及区别;平均查找长度ASL的概念及在各种查找算法中的计算方法和计算结果,特别是一些典型结构的ASL值,应该记住。
在DS的教材中,一般将search分为三类:1st,在顺序表上的查找;2nd,在树表上的查找;3rd,在哈希表上的查找。下面详细介绍其考查知识点及考查方式:
1.线性表上的查找: 主要分为三种线性结构:顺序表,有序顺序表,索引顺序表。对于第一种,我们采用传统查找方法,逐个比较。对于及有序顺序表我们采用二分查找法。对于第三种索引结构,我们采用索引查找算法。考生需要注意这三种表下的ASL值以及三种算法的实现。其中,二分查找还要特别注意适用条件以及其递归实现方法。
2.树表上的查找:
这是本章的重点和难点。由于这一节介绍的内容是使用树表进行的查找,所以很容易与树一间的某些概念相混淆。本节内容与树一章的内容有联系,但也有很多不同,应注意规纳。树表主要分为以下几种:二叉排序树,平衡二叉树,B树,键树。其中,尤以前两种结构为重,也有部分名校偏爱考B树的。由于二叉排序树与平衡二叉树是一种特殊的二叉树,所以与二叉树的联系就更为紧密,二叉树一章学好了,这里也就不难了。
二叉排序树,简言之,就是“左小右大”,它的中序遍历结果是一个递增的有序序列。平衡二叉树是二叉排序树的优化,其本质也是一种二叉排序树,只不过,平衡二叉树对左右子树的深度有了限定:深度之差的绝对值不得大于1。对于二叉排序树,“判断某棵二叉树是否二叉排序树”这一算法经常被考到,可用递归,也可以用非递归。平衡二叉树的建立也是一个常考点,但该知识点归根结底还是关注的平衡二叉树的四种调整算法,所以应该掌握平衡二叉树的四种调整算法,调整的一个参照是:调整前后的中序遍历结果相同。
B树是二叉排序树的进一步改进,也可以把B树理解为三叉、四叉....排序树。除B树的查找算法外,应该特别注意一下B树的插入和删除算法。因为这两种算法涉及到B树结点的分裂和合并,是一个难点。B树是报考名校的同学应该关注的焦点之一。
键树也称字符树,特别适用于查找英文单词的场合。一般不要求能完整描述算法源码,多是根据算法思想建立键树及描述其大致查找过程。
3.基本哈希表的查找算法:
哈希一词,是外来词,译自“hash”一词,意为:散列或杂凑的意思。哈希表查找的基本思想是:根据当前待查找数据的特征,以记录关键字为自变量,设计一个function,该函数对关键字进行转换后,其解释结果为待查的地址。基于哈希表的考查点有:哈希函数的设计,冲突解决方法的选择及冲突处理过程的描述。
第八章 内部排序
内排是DS课程中最后一个重要的章节,建立在此章之上的考题可以有多种类型:填空,选择,判断乃至大型算法题。但是,归结到一点,就是考查你对书本上的各种排序算法及其思想以及其优缺点和性能指标(时间复杂度)能否了如指掌。
这一章,我们对重点的规纳将跟以上各章不同。我们将从以下几个侧面来对排序一章进行不同的规纳,以期能更全面的理解排序一章的总体结构及各种算法。 从排序算法的种类来分,本章主要阐述了以下几种排序方法:插入、选择、交换、归并、计数等五种排序方法。
其中,在插入排序中又可分为:直接插入、折半插入、2路插入、希尔排序。这几种插入排序算法的最根本的不同点,说到底就是根据什么规则寻找新元素的插入点。直接插入是依次
寻找,折半插入是折半寻找。希尔排序,是通过控制每次参与排序的数的总范围“由小到大”的增量来实现排序效率提高的目的。
交换排序,又称冒泡排序,在交换排序的基础上改进又可以得到快速排序。快速排序的思想,一语以敝之:用中间数将待排数据组一分为二。快速排序,在处理的“问题规模”这个概念上,与希尔有点相反,快速排序,是先处理一个较大规模,然后逐渐把处理的规模降低,最终达到排序的目的。
选择排序,相对于前面几种排序算法来说,难度大一点。具体来说,它可以分为:简单选择、树选择、堆排。这三种方法的不同点是,根据什么规则选取最小的数。简单选择,是通过简单的数组遍历方案确定最小数;树选择,是通过“锦标赛”类似的思想,让两数相比,不断淘汰较大(小)者,最终选出最小(大)数;而堆排序,是利用堆这种数据结构的性质,通过堆元素的删除、调整等一系列操作将最小数选出放在堆顶。堆排序中的堆建立、堆调整是重要考点。树选择排序,也曾经在一些学校中的大型算法题中出现,请大家注意。
归并排序,故名思义,是通过“归并”这种操作完成排序的目的,既然是归并就必须是两者以上的数据集合才可能实现归并。所以,在归并排序中,关注最多的就是2路归并。算法思想比较简单,有一点,要铭记在心:归并排序是稳定排序。
基数排序,是一种很特别的排序方法,也正是由于它的特殊,所以,基数排序就比较适合于一些特别的场合,比如#9@k牌排序问题等。基数排序,又分为两种:多关键字的排序(#9@k牌排序),链式排序(整数排序)。基数排序的核心思想也是利用“基数空间”这个概念将问题规模规范、变小,并且,在排序的过程中,只要按照基排的思想,是不用进行关键字比较的,这样得出的最终序列就是一个有序序列。
本章各种排序算法的思想以及伪代码实现,及其时间复杂度都是必须掌握的,学习时要多注
意规纳、总结、对比。此外,对于教材中的10.7节,要求必须熟记,在理解的基础上记忆,
这一节几乎成为很多学校每年的必考点。
数据结构复习重点归纳
数据结构大学教程
The Complete Data Structure Training Course
第一章 数据结构及其基本概念
Chapter 1 Data Structure and It’s Basic Concepts
1.1什么是数据结构(What is Data Structure)
如果你问一个木匠学徒:你工作的工具要用什么,他可能会回答你:“我只要一把锤子和一个锯他会告诉你“我需要一些精确的工具”。由于计算机所解决的问题都是从生活中抽象出来的问题,其复杂性不言
中的复杂问题。算法、数据结构、程序设计语言都是这样的工具。数据结构是信息的组织方式。对于相同的算法的执行效率。这就有必要研究各种抽象数据类型用不同的数据结构表示的效率差异,以及其适用场合。
[一]何谓数据结构(What is Data Structure)
数据结构是在整个计算机科学与技术领域上广泛被使用的术语。它用来反映一个数据的内部构成,即一个数据由结构有逻辑上的数据结构和物理上的数据结构之分。逻辑上的数据结构反映成分数据之间的逻辑关系,而物理上结构是信息的一种组织方式,好的数据结构可以提高算法的效率,它通常与一组算法的集合相对应,通过这组算度来讲,数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等等的
[二]数据结构学科的研究对象 (The Object of Data Structure Research)
数据结构作为一门学科,主要研究数据的各种逻辑结构和存储结构,以及对数据的各种操作。因理存储结构;对数据的操作(即算法)。通常,算法的设计取决于数据的逻辑结构,算法的实现取决于数据的物究,比如存储装置和存取方法,而且解决编译原理、操作系统、数据库系统的数据元素在存储器中的分配问题的
1.2 基本概念与学科术语(Basic Concepts and Terminologies)
数据(Data):是一个集合的概念,是对客观事物的符号表示,在计算机科学中是指所有能被输入到计算机中,种特定的符号表示形式。
数据元素(Data Element):是数据的基本单位,数据中的一个“个体”。又称为“记录”或者“表目”。
数据项(Data Item):数据的不可分割的最小单位。数据元素是数据项的集合。
数据对象(Data Object):是性质相同的数据元素的集合,是数据的一个子集。
[总结]
数据项组成数据元素,数据元素组成数据对象,数据对象组成数据
数据结构(Data Structure):是相互之间存在一种或多种特定关系的数据元素的集合。它包括三个方面:数据
数据元素之间的逻辑关系被称为数据元素的逻辑结构,可以用一个二元组表示:
Data_Structure = (D, S) // Data_Structure= (Data-part, Logic-Structure-Part)
这里D是数据元素的集合,S是定义在D(或其他集合)上的关系的集合,
S = { R │ R : D×D×...}。
数据的逻辑结构可归结为以下四类:
(1)集合结构
结构中的数据元素之间除了同属于一个集合的关系外别无其他关系
(2)线性结构
结构中的数据元素之间存在一个对一个的前趋后继关系
在此种结构下:
有且仅有一个元素无前趋元素
有且仅有一个元素无后继元素
其余任何一个元素均有且仅有一个前趋有且仅有一个后继元素。
(3)树形结构
结构中的数据元素之间存在一个对多个的关系
任何一个节点最多有一个前趋,可以有多个后继,是一种典型的非线性结构
(4)图状结构(网状结构)
结构中的数据元素之间存在多个对多个的关系
这种结构的特征是任何一个元素可以有多个前趋,也可以有多个后继,是一种多对多的前趋后继关系
表和树是最常用的两种高效数据结构,许多高效的算法可以用这两种数据结构来设计实现。表是线
有序(weak/local orders))是非线性结构。
数据结构在计算机中的表示(又称为映像)称为数据的存储结构(物理结构)
数据结构的物理结构是指逻辑结构的存储映像(image)。数据结构 DS 的物理结构 P 对应于从 DS 的数据元素到
PD,S) -- > M
存储器模型:一个存储器 M 是一系列固定大小的存储单元,每个单元 U 有一个唯一的地址 A(U),该地址被连续
P 的四种基本映射模型:顺序(sequential)、链接(linked)、索引(indexed)和散列(hashing)映射。因
sequential (sets)
linked lists
indexed trees
hashing
graphs
需要指出的是:并不是所有的可能组合都合理。
数据结构DS上的操作:所有的定义在DS上的操作在改变数据元素(节点)或节点的域时必须保持DS的逻辑和
DS上的基本操作:任何其他对DS的高级操作都可以用这些基本操作来实现。最好将DS和他的所有基本操作看该模块抽象为数据类型(其中DS的存储结构被表示为私有成员,基本操作被表示为公共方法),称之为ADT(以及定义在该模型上的一组操作)。
ADT按照其值的不同特性分为下列三种类型:
原子类型(Atomic Data Type):变量是不带结构的,不可分解的。
固定聚合类型(Fixed-aggregate Data Type):其值由确定数目的成分按照某种结构组成
可变聚合类型(Variable-Aggregate Data Type):值的成分的数目不确定
抽象数据类型的描述方法
抽象数据类型可用(D,S,P)三元组表示
其中,D是数据对象,S是D上的关系集,P是对D的基本操作集。
ADT 抽象数据类型名 {
数据对象:〈数据对象的定义〉
数据关系:〈数据关系的定义〉
基本操作:〈基本操作的定义〉
} ADT 抽象数据类型名
其中,数据对象和数据关系的定义用伪码描述,基本操作的定义格式为
基本操作名(参数表)
初始条件:〈初始条件描述〉
操作结果:〈操作结果描述〉
基本操作有两种参数:赋值参数只为操作提供输入值;引用参数以&打头, 除可提供输入值外,据结构和参数应满足的条件,若不满足,则操作失败,并返回相应出错信息。“操作结果”说明了操作正常完成为空,则将其省略。需要注意的是:抽象数据类型需要通过固有数据类型(高级编程语言中已实现的数据类型)来
顺便提一句,多形数据类型(Polymorphic Data Type)是指值的成分不确定的数据类型,不过这章节再论述。
好的和坏的DS:如果一个DS可以通过某种“线性规则”被转化为线性的DS(例如线性表),则这是由计算机的计算能力决定的,因为计算机本质上只能存取逻辑连续的内存单元,因此如何没有线性化的结构的所有结点,则必须按照某种顺序来依次访问所有节点(要形成一个偏序),必须通过某种方式将图固有的非线
树是好的DS——它有非常简单而高效的线性化规则,因此可以利用树设计出许多非常高效的算法问题,因此树是实际编程中最重要和最有用的一种数据结构。树的结构本质上有递归的性质——每一个叶节点可结构都可以被转化为(或等价于)树形结构。说到递归在北京大学的数据结构课程里面有个老师经常说“不懂递明书的结构的重要性。
1.3 算法和算法分析
Algorithms and Algorithm Analysis
1.3.1算法
所谓算法(Algorithm)是对问题求解步骤的一种描述,是指令的有限序列,
其中每一条指令表示一个或多个操作。在CLRS中是这样给出算法的定义的:Informally, an algorithm is any well-defined computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output. An algorithm is thus
a sequence of computational steps that transform the input into the output.
一个算法必须满足以下五个重要特性:
1.有穷性 对于任意一组合法输入值,在执行有穷步骤之后一定能结束,即:算法中的每个步骤都能在有限时间内完成;
2.确定性 对于每种情况下所应执行的操作,在算法中都有确切的规定,使算法的执行者或阅读者都能明确其含义及如何执行。并且在任何条件下,算法都只有一条执行路径;
3.可行性 算法中描述的操作都可以通过已经实现的基本操作运算有限次实现之;
4.有输入 作为算法加工对象的量值,通常体现为算法中的一组变量。有些输入量需要在算法执行过程中输入,而有的算法表面上可以没有输入,实际上已被嵌入算法之中;
5.有输出 它是一组与输入有确定关系的量值,是算法进行信息加工后得到的结果。
1.3.2算法设计的原则
设计算法时我们应当严格考虑:
1.正确性(Correctness)
首先,算法应当满足以特定的“规格说明”方式给出的需求。对算法是否“正确”的理解可以有以下四个层次:
a.程序中不含语法错误;
b.程序对于几组输入数据能够得出满足要求的输出结果;
c.程序对于精心选择的、典型、苛刻的几组输入数据能够得出满足要求的结果;
d.程序对于一切合法的输入数据都能得出满足要求的结果;
通常以第c层意义的正确性作为衡量一个算法是否合格的标准。因为作为输入,我们有时候不可能提前做出所有的预期。
2. 可读性(Readability)
算法主要是为了人的阅读与交流,其次才是为计算机执行。因此算法应该易于人的理解;另一方面,晦涩难读的程序易于隐藏较多错误而难以调试;有些程序设计者总是把自己设计的算法写的只有自己才能看懂,这样的算法反而没有太大的价值。
3.健壮性(Rubustness)
当输入的数据非法时,算法应当恰当地作出反映或进行相应处理,而不是产生莫名奇妙的输出结果。这就需要我们一定要充分的考虑异常情况(Unexpected Exceptions)并且,处理出错的方法不应是中断程序的执行,而应是返回一个表示错误或错误性质的值,以便在更高的抽象层次上进行处理。
4.高效率与低存储量需求
通常,效率指的是算法执行时间;存储量指的是算法执行过程中所需的最大存储空间。两者都与问题的规模有关。
1.3.3算法效率的衡量方法与准则
通常有两种衡量算法效率的方法:
1.事后统计法
缺点:
(1)必须执行程序才能进行判断
(2)其它因素(如硬件、软件环境)掩盖算法本质
2.事前分析估算法
主要是看消耗的时间。和算法执行时间相关的因素:
1.算法选用的策略
2.问题的规模
3.编写程序的语言
4.编译程序产生的机器代码的质量
5.计算机执行指令的速度
一个特定算法的“运行工作量”的大小,只依赖于问题的规模(通常用整数量n表示),或者说,它是问题规模的函数。假如,随着问题规模n的增长,算法执行时间的增长率和f(n)的增长率相同,则可记作:
T (n) = O(f(n))
称T (n) 为算法的渐近时间复杂度(Asymptotic Time Complexity),简称时间复杂度。O是数量级的符号。
下面我们探讨一下如何估算算法的时间复杂度
算法 = 控制结构 + 原操作(固有数据类型的操作)
算法的执行时间=原操作(i)的执行次数×原操作(i)的执行时间
算法的执行时间与原操作执行次数之和成正比
我们先介绍一个概念:
for(j=1;j <=n;++j)
for(k=1;k <=n;++k){++x;x+=x;}
语句重复执行的次数被称为语句的频度(Frequency Count)上程序段中++x的语句频度就是n2。
我们经常采用:从算法中选取一种对于所研究的问题来说是基本操作的原操作,以该基本操作在算法中重复执行的次数作为算法运行时间的衡量准则。这个原操作多数情况下是最深层次循环内的语句中的原操作。
例如:
for (i=1; i <=n; ++i)
for (j=1; j <=n; ++j) {
c[i,j] = 0;
for (k=1; k <=n; ++k)
c[i,j] += a[i,k]*b[k,j];
}
该算法的基本操作是乘法操作。时间复杂度为 O(n3)
1.3.4算法的存储空间(Memory Space for Algorithms)
算法的空间复杂度S(n) = O(g(n))
表示随着问题规模n的增大,算法运行所需存储量的增长率与g(n)的增长率相同。
算法的存储量包括:
1.输入数据所占空间;
2.程序本身所占空间;
3.辅助变量所占空间。
若输入数据所占空间只取决与问题本身,和算法无关,则只需要分析除输入和程序之外的额