如何寻求帮助
《Linux与UNIX_shell编程指南》
http://wenku.baidu.com/view/0da65ef5f61fb7360b4c6564.html
每天一个Linux命令:
http://www.cnblogs.com/peida/archive/2012/11/06/2756278.html
定制自己的.cshrc文件:
http://blog.csdn.net/wklken/article/details/7707357
正则表达式:
http://blog.csdn.net/ysdaniel/article/details/6959059
万事问百度:http://www.baidu.com
Linux自带的帮助
--help:大部分命令都有这个option,最常用
man:manual手册,貌似是目前的版本没有安装
info:linux自带的info文档,比manual手册更全面,查阅起来不方便
文件系统
文件
文件的类型:

文件的权限:
文件属主(owner)、同组用户(group)、其他用户(other);
可读(r)、可写(w)、可执行(x);
chmod:更改文件的权限
符号模式:chmod [who]<operator><perm> filename
who :u(user/owner)、g(group)、o(other)、a(all);
operator :+、-、=;
perm :r、w、x
chmod a+x o-w filename
绝对模式:chmod mode file_name
mode :三位8进制数;
r、w、x分别用数字4、2、1表示,rwxr-xr-x即为755;
chmod 744 filename
备注:递归地更改目录及其子目录的权限,添加option –R;
类似的有,chown和chgrp
chown option owner.group filename
chgrp option group filename
umask:设置创建文件时的缺省权限位
umask umask_mod
umask_mod = 777 - 文件缺省权限值;023 = 777 – 754;
备注:系统不允许在创建普通文件时就赋予执行权限,即使缺省权限值包含有执行权限,创建目录文件时不受此限制。
ln:建立快捷方式,分为软连接和硬连接两种方式
ln -s source dest
连接目录的权限为777,但实际的原有文件的权限并未改变。
举例:硬链接一个文件或软连接一个目录到当前目录,不允许硬链接一个目录
ln /home/users/pfzhang/wrk/2042/cells/icn2042/core.v test_icn2042_core.v
ln –s /home/users/pfzhang/wrk/2042/cells/icn2042 test_icn2042
类似 cp -l/-s source dest
Linux命令入门
cd:change directory 变更目录

/表示根目录,亦即最顶层目录
~表示自己的主目录,亦即/home/users/pfzhang
.表示当前目录,..表示上一级目录,../..表示上两级目录
ls:list列举文件的内容,默认为列举当前目录内容
ls option file

mkdir和rmdir:创建目录,删除空目录
mkdir/rmdir option directory

cp、mv和rm:复制、移动和删除目录或文件
cp option source directory:默认为复制到当前目录
mv option source directory:移动源文件或目录到新的目录
rm option file :删除一个或多个文件/目录

echo:将字符串显示到标准输出
echo option string
举例:
echo -n "this is a string" 不加双引号会忽略空格,-n表示不换行
read:从键盘或文件读入信息,并赋值给变量
read varibile1 varible2 …
备注:
如果仅指定了一个变量,则把输入行的所有内容赋给该变量;
如果指定了多个变量,则以空格作为分隔符,赋给各个变量;
如果分隔出的域数量超过了变量个数,则超长的部分赋给最后一个变量;
举例:
#!/bin/bash //赋予脚本语言执行权限
echo -n "Enter your name:"
read name //从键盘输入
echo "hello $name, welcome to my program" //显示信息
exit 0 //退出shell程序。
标准输入、标准输出和标准错误

文件重定向
重定向标准输入:
CMD < filename:把filename文件作为CMD命令的标准输入
CMD << DELIMITER:从标准输入读取输入至遇到DELIMITER分界符
重定向标准输出:
CMD > filename:重定向标准输出到filename,覆盖原有内容
CMD >> filename:重定向标准输出追加到filename文件末尾
> myfile:创建一个长度为0的空文件,如果文件存在则清空该文件
重定向标准错误:
CMD 2 > filename:重定向标准错误到filename,覆盖原有内容
CMD 2 >> filename:重定向标准错误追加到filename文件末尾
合并标准输出和标准错误
CMD > filename 2 > &1:重定向标准输出和标准错误到filename
CMD >> filename 2 > &1:重定向标准输出和标准错误追加到文件末尾
结合使用标准输入、标准输出和标准错误
CMD 1 > file1 2 > file2;CMD < file1 1 > file2;
举例:
who > who.out;
tee:输出到标准输出并拷贝到相应的文件
tee –a filename
-a:追加到文件末尾,而不是覆盖
举例:
who | tee who.out 这条命令与who > who.out的区别???
&和&&、|和||

ls -l | grep ‘^d’
rmdir test_dir || echo “test_dir is not empty” && cd test_dir
cat:连接文件或标准输入并打印
cat option file

-s :超过两行的空行替换成一行空行
-n :给所有行添加行号
-b :给所有非空行加上行号
cat –s test1.txt test2.txt > test.txt && rm –rf test1.txt test2.txt && echo “sucessed” || echo “failed”
more和less、head和tail:浏览文件内容
more [-dflpcsu] [+linenum] [-num] [+/pattern] file
+linenum :从第linenum行开始显示
-num:一次显示num行
+/pattern:查找pattern字符,并从该行的前两行开始显示
-d:提示“Press space to continue, 'q' to quit”
-s:连续两行空行替换为一行空行
空格键:向下翻页;
Ctrl+shift+B:向上翻页
q:退出,文档结束自动退出
less:比more功能更强大,less和more都没有--help的选项
less option file
?、/:搜索字符串
pageup、pagedown(空格):向上向下翻一页
u、d:向上向下翻半页
j(Enter)、k(y):向下向上滚动一行
q:退出
head:默认打印文件的开头10行
head option file
tail:默认打印文件的最后10行
tail option file

文本编辑命令
sort:对文本文件数据内容排序、合并和检查是否排序
排序:sort option [input_file…],默认使用第一个字段(域)排序
合并:sort -m option [input_file…],只合并文件,不进行排序
检查:sort -c input_file;只能检查一个文件
option:
常用数据排序选项:
-n :指定位置为数字时,按数值大小排序,而不是逐字符比较
如27、1、135:1、27、135;1、135、27;
-b :忽略前置空白
-r :逆序输出
-d :排序时忽略除英文字母、数字及空白之外的字符
-f :排序时忽略大小写
-i :排序时忽略超过ASCII码打印范围的字符
-M:对表示月份的三个字母进行比较,无效名称<JAN<FEB<…<DEC
常用字段设定与输出选项:
-o output_file:指定排序结果的输出文件,默认输出到标准输出
-t char:指定char为字段分隔符,默认为tab;
-u:检查指定域的唯一性,剔除重复的行,输出结果每行的内容都不同
-k pos1[,pos2]:把pos1到pos2之间的内容当成一个字段来进行排序
???先根据字段1排序,再根据字段3进行排序
举例:
sort -o file1.txt file2.txt;把file2.txt的内容排序之后赋给file1.txt
uniq:去除文本文件中的连续重复行
uniq option input_file
option:
-u :只显示没有重复的行
-d :只显示重复的行,每个重复的行显示一次
-c :打印每一重复行出现次数
-i :忽略字母的大小写
-fx :跳过x个域再开始比较
-sx :跳过x个字符再开始比较
举例:
uniq -f2 -s4 parts.txt;从文件的第三个字段第5个字符开始执行
与sort –u 命令的区别???
join:使用共同的字段连接两个文件
join option file1 file2
option:
-o x.y[x.y,…]:在输出中只打印文件x的第y个字段
-j m:指定两个文件都用第m个字段作为join字段
-1 m -2 n:文件1、2分别使用第m和第n个字段作为join字段
-t char:指定char为输入输出字段的分隔符,默认使用tab
-ax:打印匹配连接的行及文件x中未被匹配连接的行
-vx :只打印文件x中未被匹配连接的行
举例:

join file1.txt file2.txt
join –j 1 file1.txt file2.txt
join -1 2 -2 3 file1.txt file2.txt
join file1 file2 | join - file3 | join - file4
cut:选择性打印输入文件的内容
cut option input_file
没有指定输入文件或设置为“-”,使用标准输入作为输入源
option :
-d char :指定char为分隔符,默认使用tab键作为分隔符
-f :只打印字段列表中的字段
-c :只打印字符列表中的字符
列表可以使用“-”和“,”表示,如“1-3”表示第一个到第三个,“3,6”表示第三个和第6个,“3-”表示第三个到最后一个,“-4”表示第一个到第四个;
举例:
cut -d: -f1,6 /etc/passwd ;打印系统中的用户名及其目录
who -u | cut -c1-8;列出当前在线用户
paste:以行为单位,合并文件内容
paste option file1 file2 …
各个文件的行数不一致:以行数最长的文件为基准,补空格;
没有指定输入文件而使用“-”替代时,使用标准输入作为输入源;
ls | paste –d “ ” - - - - - ;以每5个文件名为一行显示文件或目录
option :
-d char :指定char为分隔符,默认使用tab键作为分隔符
-s :将每个文件的内容作为一行输出,类似矩阵转置
举例:
已知file1内容为1;2; file2内容为a;b;

split:将大文件分割成小文件,便于编辑或传送
split option input_filename output_filename_prefix
option:
-x:每x行生成一个新的输出文件
-l m:每m行生成一个新的输出文件
-[bkm] n:每n字节、n KB、n MB生成一个新的输出文件
-d:使用数字做后缀,默认使用字母做后缀,aa、ab~az、ba、bb~zz
文件名后缀:
-a k:使用k个字目或数字做后缀,默认使用两个字母做后缀
举例:
split –b 20m gkdb.db gkdb_pack_
cat gkdb_pack_* > gkdb.tar.gz
tr:替换或删除标准输入中的字符串,打印到标准输出
option :
-c :对string1字符范围取反之后作为实际的string1
-d :删除string1中出现的字符
-t :在string1长度大于string2时使用System V方式
-s :压缩重复字符
字符范围的表示:
[a-d]:表示abcd,类似的有[a-z]、[A-Z]、[0-9];
[C*n]:表示n个C,如[F*3]表示FFF;
字符类别:
[:alnum:]字母和数字,a-z,A-Z,0-9;[:alpha:]字母a-z,A-Z;
[:digital:]数字,0-9;[:space:]空格;[:punct:]标点;
[:upper:]大写字母;[:lower:]小写字母;[:xdigital:]16进制数字
字符替换:tr string1 string2
echo “abcde” | tr abcde hijkl;hijkl
echo “abcde” | tr abc hijkl; hijde(忽略string2中多余的字符)
echo “abcde” | tr abcde hij; hijjj
echo “abcde” | tr -t abcde hij;hijde
GUN tr默认使用BSD方式(重复string2最后一个字符至补齐)
选项-t :使用System V方式(忽略string1中多余的字符)
删除字符:tr -d string1
echo “adcfghg” | tr -cd fgca;只保留string1字符范围内的字符
压缩重复字符串:tr -s string1 string2
tr -s string1;压缩string1字符范围内的重复字符
tr -s string1 string2;string1和string2替换之后利用string2进行压缩
tr -ds string1 string2;利用string1进行删除,利用string2进行压缩
Linux命令进阶
find:根据指定规则查找匹配项
find [path…] [expression]:默认path为当前目录;默认的expression是-print
expression:option / test / action /operator
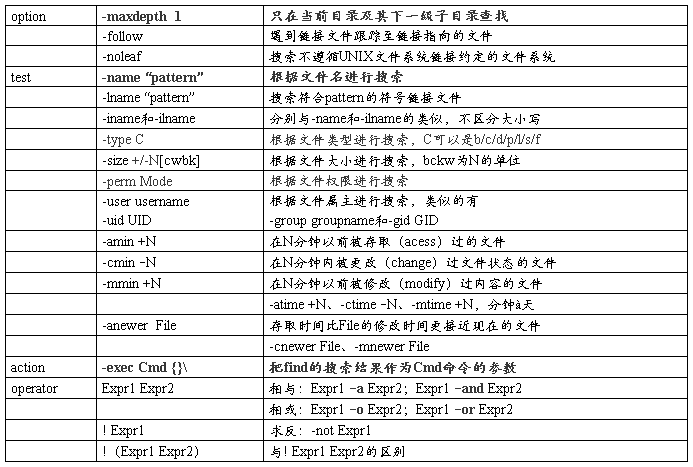
find / -name file1 从 '/' 开始进入根文件系统搜索文件和目录
find / -user user1 搜索属于用户 'user1' 的文件和目录
find /home/user1 -name \*.bin 在目录 '/ home/user1' 中搜索带有'.bin' 结尾的文件
find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
find / -name \*.rpm -exec chmod 755 '{}' \; 搜索以 '.rpm' 结尾的文件并修改权限
find / -name \*.rpm | xargs chmod 755 与上一条命令进行比较
grep:使用正则表达式搜索文本并打印匹配行
grep option patern file:在file中根据option选项搜索pattern字符
option:
-c:只输出匹配行的计数。
-i:不区分大小写(只适用于单字符)
-H、-h:在查询多个文件时,为匹配行显示或不显示文件名
-L、-l:在查询多个文件时,只输出不包含或包含匹配字符的文件名
-m:匹配Num次之后停止
-n:显示匹配行及行号
-w、-x:强制匹配整个word或者整行
-v:显示不包含匹配文本的所有行
pattern:使用单引号(正则表达式)或双引号(字符串),如‘\<output\>’和“test”
正则表达式包含字符集、锚、修饰符
字符集:0-9,A-Z,a-z,_;
锚:^、$:匹配行首和匹配行尾
修饰符:
():小括号内的字符集为一个整体
* :匹配0次或多次前一个字符集
+:匹配1次或多次前一个字符集
?:匹配0次或1次前一个字符集
[ ]、[ - ]:匹配单个字符,[A]即A符合要求,[A-C]即A、B、C符合要求
[^A-C]:匹配不属于A-C范围的字符
. :匹配任意单个字符
\:转义字符,忽略正则表达式中特殊字符的原有含义
\<、\>:匹配词首或匹配词尾
\{n\}:指示前面正则表达式匹配的次数
\{n,m\}:匹配n到m次,n<=m,n和m均为非负整数
\B、\b:匹配非单词边界和匹配单词边界
''er\b'' 可以匹配"never" 中的''er'',但不能匹配 "verb"中的 ''er''。
''er\B''能匹配"verb"中的''er'',但不能匹配"never"中的 ''er''
\W、\w:匹配任何非单词字符和匹配包括下划线的任何单词字符。
等价于''[^A-Za-z0-9_]''和''[A-Za-z0-9_]''。
\D、\d:匹配一个非数字字符和匹配一个数字字符。
等价于[^0-9] 和[0-9]。
\f 匹配一个换页符。等价于\x0c和\cL。
\n 匹配一个换行符。等价于\x0a和\cJ。
\r 匹配一个回车符。等价于\x0d和\cM。
\t 匹配一个制表符。等价于\x09 和 \cI。
\v 匹配一个垂直制表符。等价于\x0b和\cK。
\S、\s:匹配任何非空白字符和匹配任何空白字符
awk:一种编程语言
最基本功能:在文件或字符串中基于指定规则来分解抽取信息或输出数据。
完整的awk脚本通常用来格式化文本文件中的信息。
调用awk的方式:
1) awk [option] ‘awk_script’ input_file1[inputfile2…];
2) 将awk_script放入脚本文件中;
以“#!/bin/awk -f”作为首行(赋予脚本可执行权限);
在shell下调用脚本名;
3) 将所有的awk_script插入一个单独脚本文件;
调用awk –f awk_script input_file;
awk 命令的一般形式:
awk ‘BEGIN{actions}
awk_pattern1{actions}
………
awk_patternN{actions }
END{actions }’inputfile
awk的内置函数:
内置数值函数:
向0取整int(x);求平方根sqrt(x);自然常数e的幂次exp(x);
求自然对数log(x);求三角函数等;
rand():得到一个0~1之间的随机数;
srand(x):产生一个seed为x的随机数,默认使用当前日期为seed;
内置字符串函数:
index(str1,str2):返回str1中str2首次出现的位置;
length(s):求出字符串s的个数;
内置系统函数:
close(filename):将输入或输出的文件filename关闭;
system(“command”):调用系统指令,执行完毕之后回到awk程序;
流程控制结构:
1、if(condition){then-body}else{else-body}
2、while(condition){body}
3、do{body}while(condition)
4、for(initialization;condition;increment){body}
5、break和continue;
sed:非交互性文本流编辑器
编辑文件或标准输入的文本拷贝;编辑副本,不修改原文件;使用行定位模式定位哪些文本需要编辑;逐行缓冲进行编辑。
调用sed的方式:
1)命令行输入:sed option ‘sed_cmd’ input_file;
2)将sed命令插入脚本文件中;
调用sed option -f sed_script_file input_file;
3)将sed_cmd放入脚本文件中;
以“#!/bin/sed -f”作为首行(赋予脚本可执行权限);
在shell下调用脚本名;
定位要编辑的行:
x:定位第x行;
x,y:定位第x行到第y行;
x,y!:定位除第x行到第y行之外的所有行
/pattern/:定位包含模式pattern的行;
x,/pattern/:定位第x行到第一次出现模式pattern的行;
option:
p:打印匹配行;
=:显示匹配行行号;
d:删除指定行;
w output_file:输出指定行到output_file中
r input_file:从input_file中读文本附加到指定行之后
s:用模式replacement替换指定行中的oldpattern
[address]s/oldpattern/replacement/[g]
g:替换指定行中所有oldpattern,缺省只替换第一次出现的oldpattern;
a\、i\:在指定的单行之后或之前附加并显示N行新文本
c\:用新文本替换指定文本行并显示新文本;
举例:
's/abcd/d' :删除包含abcd的行
's/^$/d' :删除空行
's/\.$//g' :替换以句点结尾的行为空
's/^.//g' :替换第一个字符为空,等效为删除
sed -e '6,10d' sedtest.txt
sed "1,/^$/d" sedtest.txt;删除第一行到第一次出现空行之间的内容
echo "but this is a test string" | sed "/but/s/is/are/g" sedtest.txt
sed "s/^$/(&)/" sedtest.txt
sed "s/is/(&)/g" sedtest.txt
sed "/is/s/.*/(&)/" sedtest.txt
linux常用软件、工具
top、ps
小技巧

alias 设置指令的别名
alias类型1:加入常用的选项,输入命令不变
alias grep="grep -rnE --color"
alias mkdir="mkdir -pv"
alias类型2-1:减短命令长度 - 跳转
alias c.="cd .." alias c..="cd ../.."
alias c...="cd ../../.." alias c-='cd -'
alias类型2-2:减短命令长度 - 其他
alias wl='wc -l' #统计行数
alias lsd='find . -maxdepth 1 -type d | sort' #列出所有目录
alias dfind='find -type d -name' #查找目录
alias类型3:常用命令的重命名
alias reloadb='source ~/.bashrc'
alias reloadc='source ~/.cshrc'