以下内容为对《推荐系统》这本书的整理,在此感谢作者。
推荐系统
一、推荐系统概述
1.1 什么是推荐系统
推荐系统的作用:i)用于解决当信息过载的时候,用户不能准确、高效的找到自己所需要的信息。ii)用于引导新用户或对目标不明确的用户发觉所需要的信息。
推荐系统的任务:通过发掘用户的行为,找到用户的个性化需求,从而将长尾商品准确地推荐给需要的用户,帮助用户发现那些他们感兴趣但很难发现的商品。
1.2 推荐系统有哪些应用
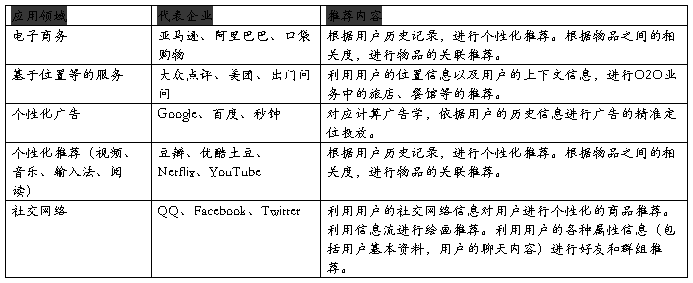
1.3 推荐系统评测
评价指标:用户满意度、准确度、覆盖度、新颖度、惊喜度、信任度、实时性、健壮性
1.4 推荐系统和搜索引擎、分类目录的区别及发展
推荐系统和搜索引擎、分类目录的目标一致,都是一种用来帮助用户快速的发现有用信息的工具。但推荐系统和搜索引擎、分类目录也具有如下的不同点。

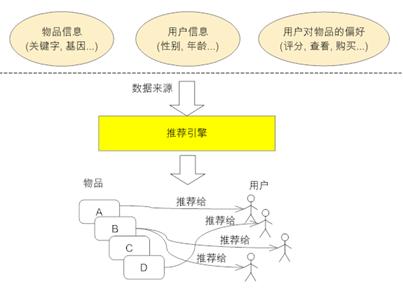
目前,信息的极度爆炸使得人们找到他们需要的信息将变得越来越难。传统的搜索技术是一个相对简单的帮助人们找到信息的工具,也广泛的被人们所使用,但搜索引擎并不能完全满足用户对信息发现的需求,原因一是用户很难用恰当的关键词描述自己的需求,二是基于关键词的信息检索在很多情况下是不够的。而推荐引擎的出现,使用户获取信息的方式从简单的目标明确的数据的搜索转换到更高级更符合人们使用习惯的上下文信息更丰富的信息发现。如下图,是推荐引擎的工作原理图。
二、推荐系统的冷启动问题
2.1 冷启动分类
i)用户冷启动。如何给新用户做个性化推荐的问题。
ii)物品冷启动。如何将新的物品推荐给可能对它感兴趣的用户。
2.2 解决方法
2.2.1 利用用户属性信息(对应i)
1)用户注册提供的年龄、性别等信息。
2)用户社交网络中,进行用户的社交网络计算,比如通过好友信息,将好友喜欢的物品推荐给用户。比如通过位置信息,将周边朋友喜欢的物品推荐给用户。
2.2.2 引导式启动(对应i)
1)提供非个性化的推荐。比如热门排行榜、周边排行榜等。然后等到用户数据收集到一定的时候,在切换为个性化推荐。
2)对话式推荐。将搜索引擎技术和推荐技术进行融合,通过问答式交互,一步步引导用户发现自己的需求。
2.2.3 利用物品内容信息(对应ii)
1)通过物品之间的相似度计算,推荐给喜欢过和它们相似的物品。
2)其中,相似度计算过程中,VSM(向量空间模型)是最常用的内容数据相似度计算模型。但是,对于语言中的歧义现象(一词多义,一义多词),VSM效果不好,LDA(潜在语义分析)技术很好的解决了这个问题。LDA的基本思想大体如下:首先确定内容的话题分布,然后在话题分布的基础上计算关键词的相关性。
2.2.4 引入专家知识(对应ii)
引入专家只是,通过一定的高效方式迅速建立起物品的相关度信息。比如个性化音乐电台应用Pandora公司,通过让音乐人对几万首歌曲进行400多个特征的标注,然后在此基础上进行歌曲之间的相似度计算。视频公司Jinni利用相似的想法设计了电影基因系统。
三、推荐系统中可利用的特征
3.1 利用用户行为信息
i)用户日志(用户ID,用户使用的设备,用户登录地点,用户输入内容……), ii)注册时的基本属性信息
iii)用户点击记录,购买记录,……
3.2 利用用户标签信息
3.2.1 标签的作用
i)打标签作为一种重要的用户行为,蕴含了很多用户兴趣信息。我们在进行用户的个性化推荐系统过程中,需要深入了解用户为什么标注、怎么标,只有这样才能发觉用户意图。同时,通过对整体用户行为标签的分析挖掘出重要信息。ii)标签形式简单,方便进行算法处理、方便用户快速、准确地了解内容。
3.2.2 标签的内容
标签的内容种类繁多,比如图片标签,标签内容为:时间、人物、动作行为。书籍标签为:书籍的类别、书籍的核心关键词、作者等。餐馆标签为:餐馆环境等级、服务员服务态度、饭菜质量、价格等。
即依据不同的需求进行标签的标注。
3.3 利用上下文信息
在不同的场景下,不同的上下文信息对推荐系统的影响很大。时间信息,比如在冬天网购,根据历史记录给推荐出来T恤等夏季衣服就是错误的。地点信息,比如你现在居住在北京寻找餐馆,依据历史记录给你推荐出来的是河南地区的餐馆等。
3.3.1 时间信息
3.3.2 地点信息
3.4 利用社交网络信息
3.4.1社交网络的优点
i)解决冷启动问题;ii)好友推荐可以增加推荐的信任度。
3.4.2社交网络的类型
i)双向确认的社交网络数据
代表企业:QQ,人人网,Facebook,
特点:熟人网络
ii)单向关注的社交网络数据
代表企业:微信,新浪微博,Twitter
特点:陌生人网络
iii)基于社区的社交网路数据
代表企业:豆瓣小组
特点:i)依据某一特点进行聚集(比如:共同兴趣,同一学校,同一公司等);ii)用户之间没有明确的关系
四、推荐系统的技术
4.1 基于关联规则
据
4.2 基于协同过滤的推荐
4.2.1基于用户的协同过滤算法(User-based collaborative filtering)
步骤:1)找到和目标用户兴趣相似的用户集合。采用用户对同一商品的正负反馈情况确定。2)找到这个集合用户喜欢,且没有被用户发现的物品推荐给目标用户。采用集合内用户投票的机制等确定。
4.2.2基于物品的协同过滤算法(Item-based collaborative filtering)
这种算法是目前业界应用最多的算法,亚马逊、YouTube、阿里巴巴等均采用此算法。
步骤:1)计算物品之间的相似度。若同一用户点击了物品A,同时也点击了物品B,则认为A和B之间存在联系,即通过同一用户的点击物品关联度来确定物品之间的相似度。2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
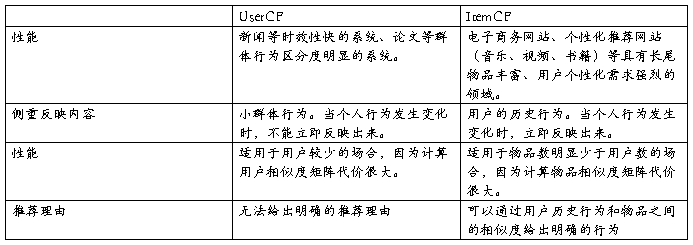
4.2.3两者的综合比较
4.3 基于内容的推荐
如何给用户推荐自己喜欢的物品,除了4.2提到的基于协同过滤的算法外,还可以按照如下这样的思路:首先,将用户按照兴趣进行划分;然后,基于不同的兴趣,推荐用户喜欢的物品。这就是隐语义模型的核心思想,即:通过隐含特征联系用户兴趣和物品。常见的名词包括:LFM、LDA、LSA、pLSA等。
基于兴趣的分类有如下三个问题:
1)如何给物品分类?采用基于用户行为统计的自动聚类方法。同4.2.2 ItemCF中计算物品之间的相似度类似。(通过同一用户的点击物品关联度来给物品分类)。
2)如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?通过用户对不同类别中物品的正负反馈来确定,并通过反馈的程度来确定对物品的感兴趣程度。
3)对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在类中的权重?利用用户的历史行为信息和物品之间的关联度进行确定。
备注:鉴于LDA技术内容繁多,在这里不做讲解。
五、推荐系统
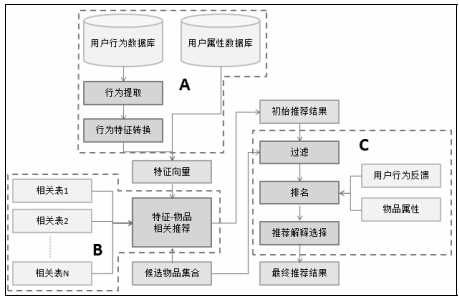
推荐引擎架构主要包括3部分,如下图。
i)该部分负责从数据库或者缓存中拿到用户行为数据,通过分析不同行为,生成当前用户的特征向量。不过如果是使用非行为特征,就不需要使用行为提取和分析模块了。该模块的输出是用户特征向量。
? ii)该部分负责将用户的特征向量通过特征-物品相关矩阵转化为初始推荐物品列表。
? iii)该部分负责对初始的推荐列表进行过滤、排名等处理,从而生成最终的推荐结果。
六、图示例



更新记录

第二篇:软件学习总结
CASTAP学习总结
1. CASTAP计算是要进行的三个任务中的一个,即单个点的能量计算,几何优化或分子动力学CASTAP计算是要进行的三个任务中的一个,即单个点的能量计算,几何优化或分子动力学.
2. CASTAP几何优化任务允许改善结构的几何,获得稳定结构或多晶型物.
3. CASTAP动力学任务允许模拟结构中原子在计算力的影响下将如何移动。
4. CASTAP性质任务允许在完成能量,几何优化或动力学运行之后求出电子和结构性质。
5. 不是很明白的地方:自洽计算与非自洽计算的定义域意义所在【好好看看CASTAP计算是要进行的三个任务中的一个,即单个点的能量计算,几何优化或分子动力学CASTAP计算是要进行的三个任务中的一个,即单个点的能量计算,几何优化或分子动力学.
6. CASTAP几何优化任务允许改善结构的几何,获得稳定结构或多晶型物.
7. CASTAP动力学任务允许模拟结构中原子在计算力的影响下将如何移动。
8. CASTAP性质任务允许在完成能量,几何优化或动力学运行之后求出电子和结构性质。
9. 不是很明白的地方:自洽计算与非自洽计算的定义域意义所在【好好看看DFT方面量子计算的知识】
10. 如果存在的话,CASTEP使用的则是格子的全部对称。既包含有两个原子的原胞和包含有8个原子的单胞是相对应的。不论单胞如何定义,电荷密度,键长,每一类原子的总体能量都是一样的,并且由于使用了较少的原子 ,使计算时间得以减少。(这句话没有理解,是什么意思?)
11. 有的不仅要优化几何结构有时还要优化晶格,在more的选项中有这个优化。
12. AlAs Trajectory.xtd——轨线文件,包含每一个优化步骤后的结构。(为什么没有这个文件)
13. 用castap可以进行计算态密度和能带结构,而且可以分别表示出来!
MS学习总结
1. LDA 适合的体系: (1) 密度变换比较缓慢的体系(例如金属体系)(2) 高密度体系(例如过渡金属) (3) 大多数结构优化过程
2. LDA 不适合的体系: (1) 对电子非常少的体系(例如化学反应中的过渡态)(2) 对于结合能的绝对值
3. GGA在结合能(粘附能)方面更具优势
4. CASTEP采用平面波的展开形式来描述电子
波函数。按照原子动能的类型来选择相关的平面波。CASTEP使用赝势来重置真实原子势能,能够有效减少平面波的数量
Doml3
1.请问过渡态虚频的物理意义该怎样理解?
答:其实,这个问题是个数学问题。要搞懂过渡态虚频的物理意义,首先要搞懂到底什么是频率。其实这一点经常有人忽视。 中学的时候我们学过简谐振动,对应的回复力是f=-kx,对应的能量曲线,是一个开口向上的二次函数E=(k/2)x^2. 这样的振动,对应的x=0的点是能量极小值点(简单情况下也就是最小值点)。这时的振动频率我们也会求ω=(2π)sqrt(k/m)。显然它是一个正的频率,也就是通常意义下的振动频率。
然后,从频率的概念引出虚频的概念。
一维情况下,如果能量曲线是一个开口向下的二次曲线呢?首先,从能量上看,这是个不稳定的点,中学的物理书上称为“不稳平衡”。用现在的观点看,就是这个点的一阶导数是零(受力为0),且是能量极大值。如果套用上面的公式,“回复力”f=-k'x(实际上已经不是回复,而是让x越来越远了),这里k'是个负数,ω=2π sqrt(k'/m)显然就是一个虚数了,即所谓的虚频。Gaussian里面给出一个负的频率,就是对应这个虚频的。
实际情况下,分子的能量是一个高维的势能面,构型优化的
时候,有时得到了极小值点,这样这个点的任意方向上,都可以近似为开口向上的二次函数,这样这里对应的振动频率就都是正的。对于极大值点,在每个方向都是开口向下的二次函数,那么频率就会都是负的——当然一般优化很少会遇到这样的情况。对于频率有正有负的情况,说明找到的点在某些方向上是极大值,有些方向上是极小值。如果要得到稳定的能量最低构型,显然需要通过微调分子的构型,消去所有的虚频。如何微调?要看虚频的振动方向。想象着虚频对应的就是开口向下的二次函数,显然,把分子坐标按照振动的方向移动一点点,分子应该就可以顺着势能面找到新的稳定点,但是也不能太小。而所谓的过渡态,则是连接反应物和产物之间的最低能量路径上的能量极大值。好比山谷中的A,B两点,它们之间的一个小土丘,就是过渡态,从A到B的反应,需要越过的是这个小土丘,而不是两边的高山。这样,过渡态就是在一个方向上是极大值,而在其它方向上都是极小值的点。因此,过渡态只有一个虚频。
2.