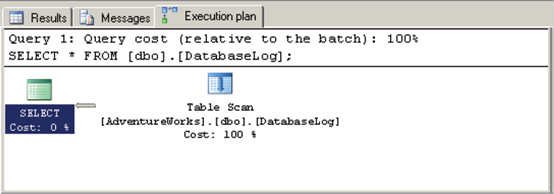
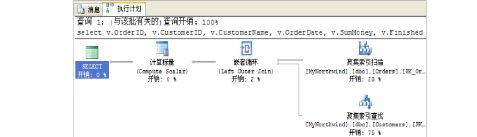
执行计划的查看和分析
1. 如何获得执行计划
要为一个语句生成执行计划,可以有3种方法:
1.1. autotrace
Sql> set autotrace on
Sql> select * from dual;
执行完语句后,会显示explain plan 与 统计信息。
这个语句的优点就是它的缺点,这样在用该方法查看执行时间较长的sql语句时,需要等待该语句执行成功后,才返回执行计划,使优化的周期大大增长。
如果不想执行语句而只是想得到执行计划可以采用:
Sql> set autotrace traceonly
这样,就只会列出执行计划,而不会真正的执行语句,大大减少了优化时间。虽然也列出了统计信息,但是因为没有执行语句,所以该统计信息没有用处,
如果执行该语句时遇到错误,解决方法为:
(1)在要分析的用户下:
Sqlplus > @ ?\rdbms\admin\utlxplan.sql
(2) 用sys用户登陆
Sqlplus > @ ?\sqlplus\admin\plustrce.sql
Sqlplus > grant plustrace to user_name; - - user_name是上面所说的分析用户
1.2. explain plan
(1) sqlplus > @ ?\rdbms\admin\utlxplan.sql
(2) sqlplus > explain plan set statement_id =’???’ for select ………………
注意,用此方法时,并不执行sql语句,所以只会列出执行计划,不会列出统计信息,并且执行计划只存在plan_table中。所以该语句比起set autotrace traceonly可用性要差。需要用下面的命令格式化输出,所以这种方式我用的不多:
…… …… 余下全文