华南师范大学实验报告
学生姓名 学 号
专 业 计算机科学与技术 年级、班级
课程名称 并行计算 实验项目 快速排序的并行算法

 实验类型
验证
设计
综合
实验时间
20## 年 5
月
10
日
实验类型
验证
设计
综合
实验时间
20## 年 5
月
10
日
实验指导老师 实验评分
3.1实验目的与要求
1、熟悉快速排序的串行算法
2、熟悉快速排序的并行算法
3、实现快速排序的并行算法
3.2 实验环境及软件
单台或联网的多台PC机,Linux操作系统,MPI系统。
3.3实验内容
1、快速排序的基本思想
2、单处理机上快速排序算法
3、快速排序算法的性能
4、快速排序算法并行化
5、描述了使用2m个处理器完成对n个输入数据排序的并行算法。
6、在最优的情况下并行算法形成一个高度为logn的排序树
7、完成快速排序的并行实现的流程图
8、完成快速排序的并行算法的实现
3.4实验步骤
3.4.1、快速排序(Quick Sort)是一种最基本的排序算法,它的基本思想是:在当前无序区R[1,n]中取一个记录作为比较的“基准”(一般取第一个、最后一个或中间位置的元素),用此基准将当前的无序区R[1,n]划分成左右两个无序的子区R[1,i-1]和R[i,n](1≤i≤n),且左边的无序子区中记录的所有关键字均小于等于基准的关键字,右边的无序子区中记录的所有关键字均大于等于基准的关键字;当R[1,i-1]和R[i,n]非空时,分别对它们重复上述的划分过程,直到所有的无序子区中的记录均排好序为止。
3.4.2、单处理机上快速排序算法
输入:无序数组data[1,n]
输出:有序数组data[1,n]
Begin
call procedure quicksort(data,1,n)
End
procedure quicksort(data,i,j)
Begin
(1) if (i<j) then
(1.1)r = partition(data,i,j)
(1.2)quicksort(data,i,r-1);
(1.3)quicksort(data,r+1,j);
end if
End
procedure partition(data,k,l)
Begin
(1) pivo=data[l]
(2) i=k-1
(3) for j=k tol-1 do
if data[j]≤pivo then
i=i+1
exchange data[i] and data[j]
end if
end for
(4) exchange data[i+1] and data[l]
(5) return i+1
End
3.4.3、快速排序算法的性能主要决定于输入数组的划分是否均衡,而这与基准元素的选择密切相关。在最坏的情况下,划分的结果是一边有n-1个元素,而另一边有0个元素(除去被选中的基准元素)。如果每次递归排序中的划分都产生这种极度的不平衡,那么整个算法的复杂度将是Θ(n2)。在最好的情况下,每次划分都使得输入数组平均分为两半,那么算法的复杂度为O(nlogn)。在一般的情况下该算法仍能保持O(nlogn)的复杂度,只不过其具有更高的常数因子。
3.4.4、快速排序算法并行化的一个简单思想是,对每次划分过后所得到的两个序列分别使用两个处理器完成递归排序。例如对一个长为n的序列,首先划分得到两个长为n/2的序列,将其交给两个处理器分别处理;而后进一步划分得到四个长为n/4的序列,再分别交给四个处理器处理;如此递归下去最终得到排序好的序列。当然这里举的是理想的划分情况,如果划分步骤不能达到平均分配的目的,那么排序的效率会相对较差。
3.4.5、描述了使用2m个处理器完成对n个输入数据排序的并行算法。
快速排序并行算法
输入:无序数组data[1,n],使用的处理器个数2m
输出:有序数组data[1,n]
Begin
para_quicksort(data,1,n,m,0)
End
procedure para_quicksort(data,i,j,m,id)
Begin
(1) if (j-i)≤k or m=0 then
(1.1) Pid call quicksort(data,i,j)
else
(1.2) Pid: r=patrition(data,i,j)
(1.3) P id send data[r+1,m-1] to Pid+2m-1
(1.4) para_quicksort(data,i,r-1,m-1,id)
(1.5) para_quicksort(data,r+1,j,m-1,id+2m-1)
(1.6) Pid+2m-1 send data[r+1,m-1] back to Pid
end if
End
3.4.6、在最优的情况下该并行算法形成一个高度为logn的排序树,其计算复杂度为O(n),通信复杂度也为O(n)。同串行算法一样,在最坏情况下其计算复杂度降为O(n2)。正常情况下该算法的计算复杂度也为O(n),只不过具有更高的常数因子。
3.4.7、完成快速排序的并行实现的流程图
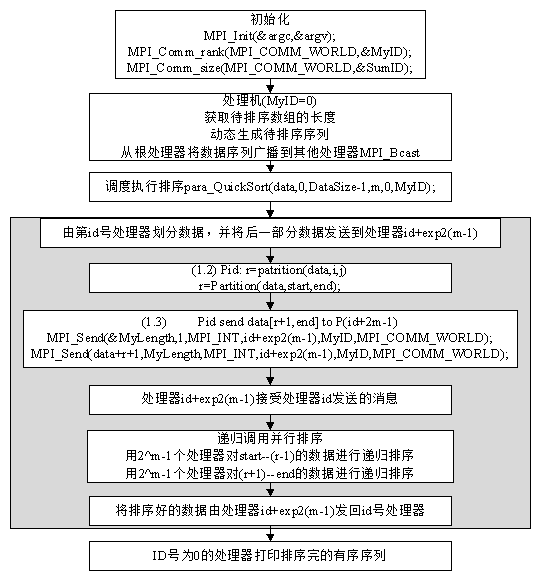
3.4.8、完成快速排序的并行算法的实现
#include <stdlib.h>
#include <mpi.h>
#define TRUE 1
/*
* 函数名: main
* 功能:实现快速排序的主程序
* 输入:argc为命令行参数个数;
* argv为每个命令行参数组成的字符串数组。
* 输出:返回0代表程序正常结束
*/
int GetDataSize();
para_QuickSort(int *data,int start,int end,int m,int id,int MyID);
QuickSort(int *data,int start,int end);
int Partition(int *data,int start,int end);
int exp2(int num);
int log2(int num);
ErrMsg(char *msg);
main(int argc,char *argv[])
{
int DataSize;
int *data;
/*MyID表示进程标志符;SumID表示组内进程数*/
int MyID, SumID;
int i, j;
int m, r;
MPI_Status status;
/*启动MPI计算*/
MPI_Init(&argc,&argv);
/*MPI_COMM_WORLD是通信子*/
/*确定自己的进程标志符MyID*/
MPI_Comm_rank(MPI_COMM_WORLD,&MyID);
/*组内进程数是SumID*/
MPI_Comm_size(MPI_COMM_WORLD,&SumID);
/*根处理机(MyID=0)获取必要信息,并分配各处理机进行工作*/
if(MyID==0)
{
/*获取待排序数组的长度*/
DataSize=GetDataSize();
data=(int *)malloc(DataSize*sizeof(int));
/*内存分配错误*/
if(data==0)
ErrMsg("Malloc memory error!");
/*动态生成待排序序列*/
srand(396);
for(i=0;i<DataSize;i++)
{
data[i]=(int)rand();
printf("%10d",data[i]);
}
printf("\n");
}
m=log2(SumID); //调用函数:求以2为底的SumID的对数
/* 从根处理器将数据序列广播到其他处理器*/
/*{"1"表示传送的输入缓冲中的元素的个数, */
/* "MPI_INT"表示输入元素的类型, */
/* "0"表示root processor的ID } */
MPI_Bcast(&DataSize,1,MPI_INT,0,MPI_COMM_WORLD);
/*ID号为0的处理器调度执行排序*/
para_QuickSort(data,0,DataSize-1,m,0,MyID);
/*ID号为0的处理器打印排序完的有序序列*/
if(MyID==0)
{
printf("实际应用处理器数:%d\n ",exp2(m-1));
for(i=0;i<DataSize;i++)
{
printf("%10d",data[i]);
}
printf("\n");
}
MPI_Finalize(); //结束计算
return 0;
}/*
* 函数名: para_QuickSort
* 功能:并行快速排序,对起止位置为start和end的序列,使用2的m次幂个处理器进行排序
* 输入:无序数组data[1,n],使用的处理器个数2^m
* 输出:有序数组data[1,n]
*/
para_QuickSort(int *data,int start,int end,int m,int id,int MyID)
{
int i, j;
int r;
int MyLength;
int *tmp;
MPI_Status status;
MyLength=-1;
/*如果可供选择的处理器只有一个,那么由处理器id调用串行排序,对应于算法步骤(1.1)*/
/*(1.1) Pid call quicksort(data,i,j) */
if(m==0)
{
if(MyID==id)
QuickSort(data,start,end);
return;
}
/*由第id号处理器划分数据,并将后一部分数据发送到处理器id+exp2(m-1),对应于算法步骤(1.2,1.3)*/
/*(1.2) Pid: r=patrition(data,i,j)*/
if(MyID==id)
{
/*将当前的无序区R[1,n]划分成左右两个无序的子区R[1,i-1]和R[i,n](1≤i≤n)*/
r=Partition(data,start,end);
MyLength=end-r;
/*(1.3) Pid send data[r+1,m-1] to P(id+2m-1) */
/* {MyLength表示发送缓冲区地址;*/
/* 发送元素数目为1; */
/* MyID是消息标签 } */
/* 在下面添加一条语句 发送长度 */
MPI_Send(&MyLength,1,MPI_INT,id+exp2(m-1),MyID,MPI_COMM_WORLD);
/*若缓冲区不空,则第id+2m-1号处理器取数据的首址是data[r+1]*/
if(MyLength!=0)
/* 在下面添加一条语句 */
MPI_Send(data+r+1,MyLength ,MPI_INT,id+exp2(m-1),MyID,MPI_COMM_WORLD);
}
/*处理器id+exp2(m-1)接受处理器id发送的消息*/
if(MyID==id+exp2(m-1))
{ /* 在下面添加一条语句 */
MPI_Recv(&MyLength,1,MPI_INT,id,id,MPI_COMM_WORLD,&status);
if(MyLength!=0)
{
tmp=(int *)malloc(MyLength*sizeof(int));
if(tmp==0) ErrMsg("Malloc memory error!");
/* 在下面添加一条语句 */
MPI_Recv(tmp,MyLength,MPI_INT,id,id,MPI_COMM_WORLD,&status);
}
}
/*递归调用并行排序,对应于算法步骤(1.4,1.5)*/
/*用2^m-1个处理器对start--(r-1)的数据进行递归排序*/
j=r-1-start;
MPI_Bcast(&j,1,MPI_INT,id,MPI_COMM_WORLD);
/*(1.4) para_quicksort(data,i,r-1,m-1,id)*/
if(j>0)
/* 在下面添加一条语句 */
para_QuickSort(data,start,r-1,m-1,id,MyID);
/*用2^m-1个处理器对(r+1)--end的数据进行递归排序*/
j=MyLength;
MPI_Bcast(&j,1,MPI_INT,id,MPI_COMM_WORLD);
/*(1.5) para_quicksort(data,r+1,j,m-1,id+2m-1)*/
if(j>0)
/* 在下面添加一条语句 */
para_QuickSort(tmp,0,MyLength-1,m-1,id+exp2(m-1),MyID);
/*将排序好的数据由处理器id+exp2(m-1)发回id号处理器,对应于算法步骤(1.6)*/
/*(1.6) P(id+2m-1) send data[r+1,m-1] back to Pid */
if((MyID==id+exp2(m-1)) && (MyLength!=0))
MPI_Send(tmp,MyLength,MPI_INT,id,id+exp2(m-1),MPI_COMM_WORLD);
if((MyID==id) && (MyLength!=0))
MPI_Recv(data+r+1,MyLength,MPI_INT,id+exp2(m-1),id+exp2(m-1),MPI_COMM_WORLD,&status);
}
/*
* 函数名: QuickSort
* 功能:对起止位置为start和end的数组序列,进行串行快速排序。
* 输入:无序数组data[1,n]
* 返回:有序数组data[1,n]
*/
QuickSort(int *data,int start,int end)
{
int r;
int i;
if(start<end)
{
r=Partition(data,start,end);
QuickSort(data,start,r-1);
QuickSort(data,r+1,end);
}
return 0;
}
/*
* 函数名: Partition
* 功能:对起止位置为start和end的数组序列,将其分成两个非空子序列,
* 其中前一个子序列中的任意元素小于后个子序列的元素。
* 输入:无序数组data[1,n]
* 返回: 两个非空子序列的分界下标
*/
int Partition(int *data,int start,int end)
{
int pivo;
int i, j;
int tmp;
pivo=data[end];
i=start-1; /*i(活动指针)*/
for(j=start;j<end;j++)
if(data[j]<=pivo)
{
i++; /*i表示比pivo小的元素的个数*/
tmp=data[i];
data[i]=data[j];
data[j]=tmp;
}
tmp=data[i+1];
data[i+1]=data[end];
data[end]=tmp; /*以pivo为分界,data[i+1]=pivo*/
return i+1;
}
/*
* 函数名: exp2
* 功能:求2的num次幂
* 输入:int型数据num
* 返回: 2的num次幂
*/
int exp2(int num)
{
int i;
i=1;
while(num>0)
{
num--;
i=i*2;
}
return i;
}
/*
* 函数名: log2
* 功能:求以2为底的num的对数
* 输入:int型数据num
* 返回: 以2为底的num的对数
*/
int log2(int num)
{
int i, j;
i=1;
j=2;
while(j<num)
{
j=j*2;
i++;
}
if(j>num)
i--;
return i;
}
/*
* 函数名: GetDataSize
* 功能:读入待排序序列长度
*/
int GetDataSize()
{
int i;
while(TRUE)
{
printf("Input the Data Size :");
scanf("%d",&i);
/*读出正确的i,返回;否则,继续要求输入*/
if((i>0) && (i<=65535))
break;
ErrMsg("Wrong Data Size, must between [1..65535]");
}
return i;
}
/*输出错误信息*/
ErrMsg(char *msg)
{
printf("Error: %s \n",msg);
}
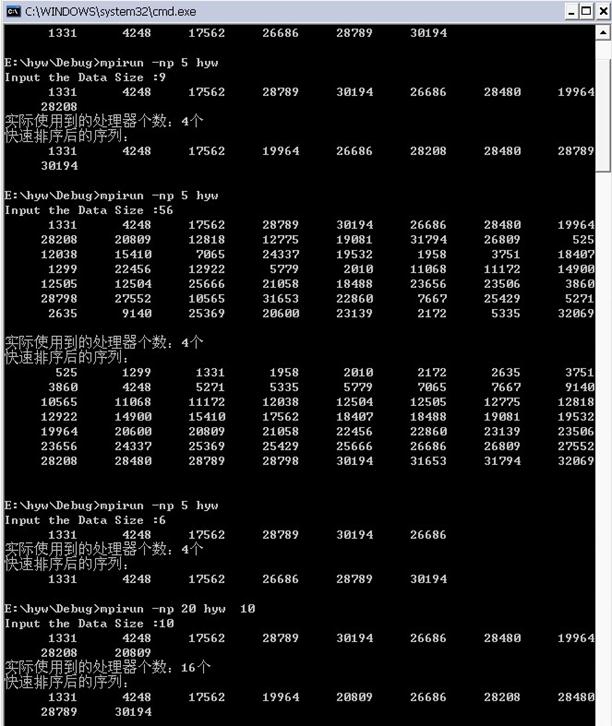
3.5 实验结果
3.6实验总结
通过这次实验,我熟悉快速排序的串行算法和并行算法 ,并了解了实现快速排序的并行流程图。但是在实际的操作过程中也遇到了不少问题。最后是在同学的帮助下完成的。
一、枚举排序算法说明:
枚举排序(Enumeration Sort)是一种最为简单的排序算法,通常也被叫做秩排序(Rank Sort)。
该算法的基本思想是:对每一个要排序的元素统计小于它的所有元素的个数,从而得到该元素在整个序列中的位置。其时间复杂度为o(n^2)。其伪代码为:
输入为:a[1], a[2] , ... , a[n]
输出为:b[1], b[2] , ..., b[n]
for i =1 to n do
1)k =1
2)for j = 1 to n do
if a > a[j] then
k= k + 1
endif
endfor
3)b[k] = a
endfor
算法思想很简单,现将其主要代码总结如下:
1、数组自动生成,随机生成长度为n的数组:
- 1: void array_builder(int *a, int n)
- 2: {
- 3: int i;
- 4:
- 5: srand((int)time(0));
- 6:
- 7: for(i = 0; i < n; i++)
- 8: a = (int)rand() % 100;
- 9:
- 10: return;
- 11: }
复制代码
2、取得每个元素在数组中的秩,即统计每个元素按小于它的其他所有元素的个数:
- 1: int *get_array_elem_position(int *init_array, int array_length, int start, int size){
- 2:
- 3: int i,j,k;
- 4: int *position;
- 5:
- 6: position = (int *)my_malloc(sizeof(int) * size);
- 7: for(i = start; i < start+size; i++){
- 8: k = 0;
- 9: for(j = 0; j < array_length; j++){
- 10: if(init_array < init_array[j])
- 11: k++;
- 12: if((init_array == init_array[j]) && i >j)
- 13: k++;
- 14: }
- 15:
- 16: position[i-start] = k;
- 17: }
- 18:
- 19: return position;
- 20: }
复制代码
其中my_malloc函数的作用为动态分配大小为size的空间,如分配失败,则终止程序:
- 1: void *my_malloc(int malloc_size){
- 2: void *buffer;
- 3:
- 4: if((buffer = (void *)malloc((size_t)malloc_size)) == NULL){
- 5: printf("malloc failure");
- 6: exit(EXIT_FAILURE);
- 7: }
- 8:
- 9: return buffer;
- 10: }
复制代码
3、 算法主函数:
- 1: void serial(){
- 2:
- 3: int i;
- 4: int array_length = ARRAY_LENGTH;
- 5:
- 6: int *init_array;
- 7: int *sort_array;
- 8: int *position;
- 9:
- 10: // array_length = get_array_length(4);
- 11:
- 12: sort_array = (int *)my_malloc(sizeof(int) * array_length);
- 13: init_array = (int *)my_malloc(sizeof(int) * array_length);
- 14:
- 15: array_builder(init_array, array_length);
- 16:
- 17: position = get_array_elem_position(init_array, array_length, 0, array_length);
- 18:
- 19: for(i = 0; i < array_length; i++)
- 20: sort_array[position] = init_array;
- 21:
- 22: printf("串行实行结果:\n");
- 23: init_sort_array_print(init_array, sort_array, array_length);
- 24: }