操作系统实验三报告
实验题目:
进程管理及进程通信
实验环境:
虚拟机Linux操作系统
实验目的:
1.利用Linux提供的系统调用设计程序,加深对进程概念的理解。
2.体会系统进程调度的方法和效果。
3.了解进程之间的通信方式以及各种通信方式的使用。
实验内容:
例程1:
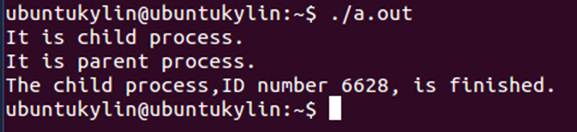
利用fork()创建子进程
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
main()
{
int i;
if (fork())
i=wait(0);
/*父进程执行的程序段*/
/* 等待子进程结束*/
printf("It is parent process.\n");
printf("The child process,ID number %d, is finished.\n",i);
}
else{
printf("It is child process.\n");
sleep(10);
/*子进程执行的程序段*/
exit(1);
/*向父进程发出结束信号*/
}
}
运行结果:
思考:子进程是如何产生的? 又是如何结束的?子进程被创建后它的运行环境是怎
样建立的?
答:子进程是通过函数fork()创建的,通过exit()函数自我结束的,子进程被创建后核心将为其分配一个进程表项和进程标识符,检查同时运行的进程数目,并且拷贝进程表项的数据,由子进程继承父进程的所有文件。
例程2:
循环调用fork()创建多个子进程
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
main()
{ int i,j;
printf(“My pid is %d, my father’s pid is %d\n”,getpid()
,getppid());
for(i=0; i<3; i++)
if(fork()==0)
printf(“%d pid=%d ppid=%d\n”, i,getpid(),getppid());
else
{ j=wait(0);
Printf(“ %d:The chile %d is finished.\n” ,getpid(),j);
}
}
运行结果:
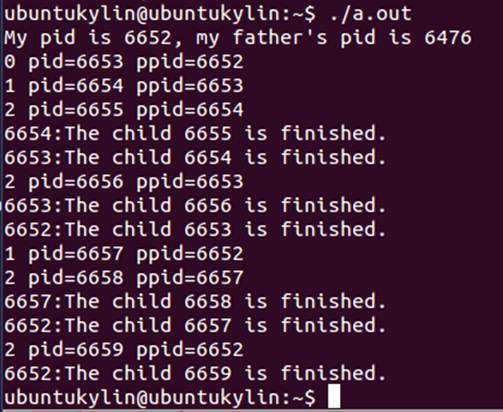
思考:画出进程的家族树。子进程的运行环境是怎样建立的?反复运行此程序
看会有什么情况?解释一下。
答: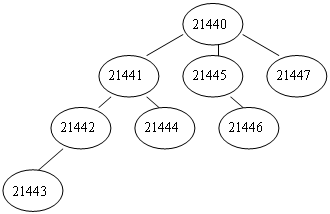
子进程的运行环境是由将其创建的父进程而建立的,反复运行程序会发现每个进程标识号在不断改变,这是因为同一时间有许多进程在被创建。
例程3:
创建子进程并用execlp()系统调用执行程序的实验
#include<stdio.h>
#include<unistd.h>
main()
{
int child_pid1,child_pid2,child_pid3;
int pid,status;
setbuf(stdout,NULL);
child_pid1=fork(); /*创建子进程1*/
if(child_pid1==0)
{ execlp("echo","echo","child process 1",(char *)0); /*子进程1 启动其它程序*/
perror("exec1 error.\n ");
exit(1);
}
child_pid2=fork(); /*创建子进程2*/
if(child_pid2==0)
{ execlp("date","date",(char *)0); /*子进程2 启动其它程序*/
perror("exec2 error.\n ");
exit(2);
}
child_pid3=fork(); /*创建子进程3*/
if(child_pid3==0)
{ execlp("ls","ls",(char *)0); /*子进程3 启动其它程序*/
perror("exec3 error.\n ");
exit(3);
}
puts("Parent process is waiting for chile process return!");
while((pid=wait(&status))!=-1) /*等待子进程结束*/
{ if(child_pid1==pid) /*若子进程1 结束*/
printf("child process 1 terminated with status %d\n",(status>>8));
else
{if(child_pid2==pid) /*若子进程2 结束*/
printf("child process 2 terminated with status %d\n",(status>>8));
else
{ if(child_pid3==pid) /*若子进程3 结束*/
printf("child process 3 terminated with status %d\n" ,(status>>8));
}
}
}
puts("All child processes terminated.");
puts("Parent process terminated.");
exit(0);
}
运行结果:
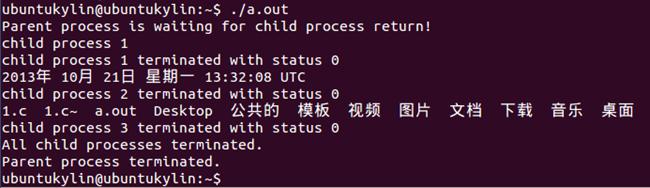
思考:子进程运行其他程序后,进程运行环境怎样变化的?反复运行此程序看会有什么情况?解释一下。
答:子进程运行其他程序后,这个进程就完全被新程序代替。由于并没有产生新进程所以进程标识号不改变,除此之外旧进程的其它信息,代码段,数据段,栈段等均被新程序的信息所代替。新程序从自己的main()函数开始运行。反复运行此程序发现结束的先后次序是不可预知的,每次运行结果都不一样。原因是当每个子进程运行其他程序时,他们的结束随着其他程序的结束而结束,所以结束的先后次序在改变。
例程4:
观察父、子进程对变量处理的影响
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int globa=4;
int main()
{
pid_t pid;
int vari=5;
printf("before fork.\n");
if ((pid=fork())<0)
{
}
printf("fork error.\n");
exit(0);
else
if(pid==0)
{
/*子进程执行*/
globa++;
vari--;
printf("Child %d changed the vari and globa.\n",getpid());
}
else
{
/*父进程执行*/
wait(0);
printf("Parent %d did not changed the vari and globa.\n",getpid());
}
printf("pid=%d, globa=%d, vari=%d\n",getpid(),globa,vari);
/*都执行*/
exit(0);
}
运行结果:

思考:子进程被创建后,对父进程的运行环境有影响吗?解释一下。
答:子进程被创建后,对父进程的运行环境无影响,因为当子进程在运行时,它有自己的代码段和数据段,这些都可以作修改,但是父进程的代码段和数据段是不会随着子进程数据段和代码段的改变而改变的。
例程5:
管道通信的实验
#include<stdlib.h>
#include<stdio.h>
main()
{
int i,r,j,k,l,p1,p2,fd[2];
char buf[50],s[50];
pipe(fd);
while((p1=fork())==-1);
if(p1==0)
lockf(fd[1],1,0);
/*子进程1 执行*/
/*管道写入端加锁*/
sprintf(buf,"Child process P1 is sending messages! \n");
printf("Child process P1! \n");
write(fd[1],buf,50);
lockf(fd[1],0,0);
/*信息写入管道*/
/*管道写入端解锁*/
sleep(5);
j=getpid();
k=getppid();
printf("P1 %d is weakup. My parent process ID is %d.\n",j,k);
exit(0);
}
else
{ while((p2=fork())==-1);
if(p2==0)
{
lockf(fd[1],1,0);
/*创建子进程2*/
/*子进程2 执行*/
/*管道写入端加锁*/
sprintf(buf,"Child process P2 is sending messages! \n");
printf("Child process P2! \n");
write(fd[1],buf,50);
lockf(fd[1],0,0);
/*信息写入管道*/
/*管道写入端解锁*/
sleep(5);
j=getpid();
k=getppid();
printf("P2 %d is weakup. My parent process ID is %d.\n",j,k);
exit(0);
}
else
{ l=getpid();
wait(0);
if(r=read(fd[0],s,50)==-1)
printf("Can't read pipe. \n");
else
printf("Parent %d: %s \n",l,s);
wait(0);
if(r=read(fd[0],s,50)==-1)
printf("Can't read pipe. \n");
else
printf("Parent %d: %s \n",l,s);
exit(0);
}
}
}
}
运行结果:
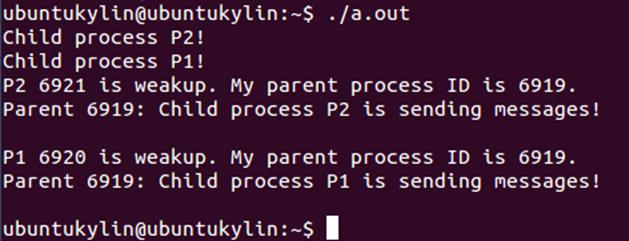
思考:(1)什么是管道?进程如何利用它进行通信的?解释一下实现方法。
(2)修改睡眠时机、睡眠长度,看看会有什么变化。解释。
(3)加锁、解锁起什么作用?不用它行吗?
答:(1)管道是指能够连接一个写进程和一个读进程、并允许他们以生产者—消费者方式进行通信的一个共享文件,又称pipe文件。由写进程从管道的入端将数据写入管道,而读进程则从管道的出端读出数据来进行通信。
(2)修改睡眠时机和睡眠长度都会引起进程被唤醒的时间不一,因为睡眠时机决定进程在何时睡眠,睡眠长度决定进程何时被唤醒。
(3)加锁、解锁是为了解决临界资源的共享问题。不用它将会引起无法有效的管理数据,即数据会被修改导致读错了数据。
例程7:
软中断信号实验
#include<stdlib.h>
#include<stdio.h>
main()
{
int i,j,k;
int func();
signal(18,func());
if(i=fork())
{
j=kill(i,18);
/*创建子进程*/
/*父进程执行*/
/*向子进程发送信号*/
printf("Parent: signal 18 has been sent to child %d,returned %d.\n",i,j);
k=wait();
/*父进程被唤醒*/
printf("After wait %d,Parent %d: finished.\n",k,getpid());
}
else
{
/*子进程执行*/
sleep(10);
printf("Child %d: A signal from my parent is recived.\n",getpid());
} /*子进程结束,向父进程发子进程结束信号*/
}
func()
/*处理程序*/
{ int m;
m=getpid();
printf("I am Process %d: It is signal 18 processing function.\n",m);
}
运行结果:

思考:讨论一下它与硬中断有什么区别?
答:硬中断是由外部硬件产生的,而软中断是CPU根据软件的某条指令或者软件对标志寄存器的某个标志位的设置而产生的。
研究:
什么是进程?如何产生的?
答:进程是进程实体的运行过程,是系统进行资源分配和调度的一个独立单位。
一旦操作系统发现了要求创建新进程的事件后,便调用进程创建原语Creat()按下述步骤创建一个新进程:
(1)申请空白PCB。为新进程申请获得惟一的数字标识符,并从PCB集合中索取一个空白PCB。
(2)为新进程分配资源。为新进程的程序和数据以及用户栈分配必要的内存空间。显然此时操作系统必须知道新进程所需内存的大小。对于批处理作业,其大小可在用户提出创建进程要求时提供。若是为应用进程创建子进程,也应是在该进程提出创建进程的请求中给出所需内存的大小。对于交互型作业,用户可以不给出内存要求而由系统分配一定的空间。如果新进程要共享某个已在内在的地址空间(即已装入内存的共享段),则必须建立相应的链接。(3)初始化进程控件块。PCB的初始化包括:1.初始化标识信息,将系统分配的标识符和父进程标识符填入新PCB中;2.初始化处理机状态信息,使程序计数器指向程序的入口地址,使栈指针指向栈顶;3.初始化处理机控制信息,将进程的状态设置为就绪状态或静止就绪状态,对于优先级,通常是将它设置为最低优先级,除非用户以显式方式提出高优先级要求。
(4)将新进程插入就绪队列,如果进程就绪队列能够接纳新进程,便将新进程插入就绪队列。
进程控制如何实现的?
答:为了描述和控制进程的运行,系统为每个进程定义了一个数据结构——进程控制块PCB,它是进程实体的一部分,是操作系统中最重要的记录型数据结构。PCB中记录了操作系统所需的、用于描述进程的当前情况以及控制进程运行的全部信息。当系统创建一个新进程时,就为它建立了一个PCB;进程结束时又回收其PCB,进程于是也随之消亡。
进程通信方式各有什么特点?
答:高级通信机制可归结为三大类:共享存储器系统、消息传递系统以及管道通信系统。
在共享存储器系统中,相互通信的进程共享某些数据结构或共享存储区,进程之间能够通过这些空间进行通信。
消息传递系统中,进程间的数据交换是以格式化的消息为单位的。
管道通信系统能有效地传送大量数据,因而又被引入到许多其它操作系统中。
管道通信如何实现?该通信方式可以用在何处?
答:向管道提供输入的发送进程,以字符流形式将大量的数据送入管道;而接受管道输出的接收进程,则从管道中接收数据。由于发送进程和接收进程是利用管道进行通信的,故又称为管道通信。由于它能有效地传送大量数据,因而又被引入到许多其它操作系统中。
什么是软中断?软中断信号通信如何实现?
答:软中断是CPU根据软件的某条指令或者软件对标志寄存器的某个标志位的设置而产生的。
体会:
这次的实验主要涉及到进程管理及进程通信,目的是让我们利用Linux提供的系统调用设计程序,加深对进程管理及进程通信的理解。而通过此次实验,也让我更进一步的理解了进程管理及进程通信的相关概念机意义。
第二篇:北邮大三上-操作系统-进程同步实验报告

班级:2009211311
学号:
姓名: schnee
目 录
1. 实验目的... 1
2. 实验要求... 1
3. 环境说明... 1
4. 实验前期思考... 1
5. 实验知识点储备... 1
5.1. 进程... 1
5.2. 线程... 1
5.3. 同步和互斥... 1
5.4. 库函数和类型储备... 1
6. 编程实现:... 1
6.1. 调整和框架... 1
6.2. 源程序实现(详细框架见注释)... 1
6.3. 实现中遇到过的困难和解决方法... 1
6.4. 运行示例及结果截图... 1
7. 心得和优化... 1
1. 实验目的
1) 理解进程/线程同步的方法,学会运用进程/线程同步的方法解决实际问题;
2) 了解windows系统或unix/linux系统下中信号量的使用方法。
2. 实验要求
编写一个有关生产者和消费者的程序:每个生产者每次生产一个产品存入仓库,每个消费者每次从仓库中取出一个产品进行消费,仓库大小有限,每次只能有一个生产者或消费者访问仓库。要求:采用信号量机制。
3. 环境说明
此实验采用的是Win7下Code::blocks 10.05编译器,采用Win API的信号量机制编程。
此word实验文档中采用notepad++的语法高亮。
4. 实验前期思考
可能有多个生产者和消费者。可以假设输入P表示创建一个生产者线程,输入C表示创建一个消费者线程。
生产者线程等待仓库有空位并且占据此空位,,然后等待仓库的操作权,执行操作,最后释放仓库操作权。一开始以为是占位的操作在获得操作权后,疑惑:若是等待空位后在等待获得操作权时又没有空位了,岂不是又不能放入了?若是先获得操作权再等空位,则在无空位时会进入无穷等待状态,因为没有人来改变空位个数。
这两个问题如何克服呢?
其实第一个疑问是因为我对wait函数的具体操作还有点模糊,实际上wait操作便是一等到空位就顺便占了,而不是我想的等位和占位分离。而第二个问题自然是不行的,这种操作顺序应该抛弃。
还是第一个问题,由于我们无法在等操作权时判断是否被生产者占着,无法判断是否空位状态改变了,所以我想到可以在等到操作权时在判断一下是否现在还有空位,没有就从头开始等待空位。但是这可能又是无穷等待。等再细想wait()函数的操作,突然发现其实我们想到的先人早已都考虑到了。wait()函数一有空位就占了,这样我们只需再等操作权即可,相当于拿号等待,号完了就是没位了,所以现在的位置实际不只是当前仓库里的空位,还包括在它前面报名的生产者数目。顺序确定,问题解决。
消费者线程,最直接的想法是先等待仓库的操作权,然后释放一个空位,最后释放仓库的操作权。这里释放空位只要有仓库的操作权即可进行,没有冲突,所以位置和生产者有所不同。其实这还有个问题,因为仓库问题不同于图书馆问题,有读者必然有一个位置可以释放,但是有消费者却不一定有产品可供消费。居然一不小心把两者弄混了,第一想法果然还是不成熟。幸好很快想到。基本概念还待牢固掌握!于是消费者应该与生产者类似,先等待货物,就是先看是否还有货,有就预订了,然后等待仓库的操作权,再取走产品,最后释放仓库的操作权。
故定义两个信号量,seat,初始化为仓库的容量M;ban,初始化为1,表示仓库操作权是否被占用。
生产者 消费者
wait(seat); signal(seat);
wait(ban); wait(ban);
signal(ban); signal(ban);
上面两种进程里都分别有一对互斥信号量wait(ban)和signal(ban)。两进程间有一同步信号量wait(seat)和signal(seat)。
5. 实验知识点储备
5.1. 进程
进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
5.2. 线程
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。每一个程序都至少有一个线程,那就是程序本身。
线程是程序中一个单一的顺序控制流程。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
5.3. 同步和互斥
进程互斥是进程之间发生的一种间接性作用,一般是程序不希望的。通常的情况是两个或两个以上的进程需要同时访问某个共享变量。我们一般将发生能够问共享变量的程序段成为临界区。两个进程不能同时进入临界区,否则就会导致数据的不一致,产生与时间有关的错误。解决互斥问题应该满足互斥和公平两个原则,即任意时刻只能允许一个进程处于同一共享变量的临界区,而且不能让任一进程无限期地等待。互斥问题可以用硬件方法解决;也可以用软件方法。
同步是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
5.4. 库函数和类型储备
库函数
(1) CreateThread建立新的线程(Windows API)。
函数原型声明:
HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpThreadAttributes, DWORD dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress, LPVOID lpParameter,
DWORD dwCreationFlags, LPDWORD lpThreadId);
(2) CreateMutex创建一个互斥体
函数原型声明(VC)
HANDLE CreateMutex( LPSECURITY_ATTRIBUTES lpMutexAttributes, // 指向安全属性的指针
BOOL bInitialOwner, // 初始化互斥对象的所有者
LPCTSTR lpName // 指向互斥对象名的指针 );
(3) CreateSemaphore创建一个新的信号量
函数原型VC声明:
HANDLE CreateSemaphore (LPSECURITY_ATTRIBUTES ipSemaphoreAttributes, LONG initial_count,
LONG maximum_count, LPCTSTR lpName);
Semaphore是另一个同步问题机制,不论是Event或Mutex,其他Process在执WaitForSingleObject
时,就看当时的物件是Signal或UnSignal而决定是否等待,而Semaphore也相同,但是它要变成Signal /UnSignal的状态,却有些不同,它是提供一个计数值,它允许在这个计数值之内,任何执行到WaitForSingleObject的Thread都不会停下来,而且每执行WaitForSingleObject一次,计数值就减一,当计数值变成0时,该Semaphore才会处於UnSignal的状态,而某个Thread ReleaseSemaphore时,便会将计数值增加,以便其他的Thread或本身可得Signal的讯号,而使WaitForSingleObject停止等待。
函数原型声明:
(4) ReleaseMutex释放由线程拥有的一个互斥体
(5) ReleaseSemaphore对指定的信号量增加指定的值
原型:BOOL ReleaseSemaphore( HANDLE hSemaphore, LONG lReleaseCount, LPLONG lpPreviousCount );
参数:
hSemaphore要操作的信号量对象的句柄,这个句柄是CreateSemaphore或者OpenSemaphore函数的返回值。
lReleaseCount这个信号量对象在当前基础上所要增加的值,这个值必须大于0,如果信号量加上这个值会导致信号量的当前值大于信号量创建时指定的最大值,那么这个信号量的当前值不变,同时这个函数返回FALSE;
lpPreviousCount指向返回信号量上次值的变量的指针,如果不需要信号量上次的值,那么这个参数可以设置为NULL;返回值:如果成功返回TRUE,如果失败返回FALSE,可以调用GetLastError函数得到详细出错信息
(6) WaitForSingleObject
函数原型说明:DWORD WaitForSingleObject(HANDLE hHandle, DWORD dwMilliseconds)
WaitForSingleObject函数用来检测hHandle事件的信号状态,在某一线程中调用该函数时,线程暂时挂起,如果在挂起的dwMilliseconds毫秒内,线程所等待的对象变为有信号状态,则该函数立即返回;如果超时时间已经到达dwMilliseconds毫秒,但hHandle所指向的对象还没有变成有信号状态,函数照样返回。参数dwMilliseconds有两个具有特殊意义的值:0和INFINITE。若为0,则该函数立即返回;若为INFINITE,则线程一直被挂起,直到hHandle所指向的对象变为有信号状态时为止。
(7) WaitForMultipleObjects
函数原型说明:
DWORD WaitForMultipleObjects(DWORD nCount,const HANDLE* lpHandles,BOOL bWaitAll,DWORD dwmseconds)
nCount 句柄的数量 最大值为MAXIMUM_WAIT_OBJECTS(64)
HANDLE 句柄数组的指针
HANDLE 类型可以为(Event,Mutex,Process,Thread,Semaphore )数组
BOOL bWaitAll 等待类型,TRUE 等待所有信号量有效再往下执行,FALSE当其中一个信号量有效时向下执行
DWORD dwMilliseconds 超时时间 超时后向执行
(8) CloseHandle
函数原型声明:Bool CloseHandle(HANDLE hObject)
关闭一个内核对象。若在线程执行完之后,没有调用CloseHandle,在进程执行期间,将会造成内核对象的泄露,相当于句柄泄露,但不同于内存泄露,这势必会对系统的效率带来一定程度上的负面影响。但当进程结束退出后,系统会自动清理这些资源。
类型
(1) LPVOID
LPVOID是一个没有类型的指针,也就是说你可以将任意类型的指针赋值给LPVOID类型的变量(一般作为参数传递),然后在使用的时候再转换回来。
(2) HANDLE
HANDLE(句柄)是windows操作系统中的一个概念。在window程序中,有各种各样的资源(窗口、图标、光标等),系统在创建这些资源时会为它们分配内存,并返回标示这些资源的标示号,即句柄。句柄指的是一个核心对象在某一个进程中的唯一索引,而不是指针。由于地址空间的限制,句柄所标识的内容对进程是不可见的,只能由操作系统通过进程句柄列表来进行维护。句柄列表: 每个进程都要创建一个句柄列表,这些句柄指向各种系统资源,比如信号量,线程和文件等,进程中的所有线程都可以访问这些资源
(3) DWORD注册表的键值
6. 编程实现:
6.1. 调整和框架
调整:实际编程时,学习了Windows API里的信号量后才知道其实还需要第三个信号量,该把前期思考中的seat分为full和empty两个信号量来实现。
框架:在主进程里输入参数设置仓库大小,请求个数及各自类型和时间。
读入参数后,完成仓库等的初始化,之后从0开始计时按时间顺序启动线程。
对于每个线程,输出相应的信息告知我们他开始提出请求,他获得允许开始执行相应操作,他结束操作释放相应使用权,线程结束。
6.2. 源程序实现(详细框架见注释)
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <windows.h>
usingnamespace std;
const int MAX_BUF = 1024; //最大缓冲区大小
const int MAX_REQ = 20; //最大请求数
const int P = 1; //生产者
const int C = 0; //消费者
int BUF_SIZE; //缓冲区大小,即用户设定的仓库容量
int Pro_no; //生产的产品号,从1开始
int in; //缓冲区里产品的下界
int out; //缓冲区里产品的上界
int buffer[MAX_BUF]; //用数组模拟循环队列的缓冲区
int req_num; //对仓库的操作请求数
struct request
{
int p_c; //请求者类型
int ti; //请求时间,1为1ms
} req[MAX_REQ]; //请求序列
//定义三个信号量
HANDLE mutex; //用于进程对仓库的互斥操作
HANDLE full_sema; //当仓库满时生产者必须等待
HANDLE empty_sema; //当仓库空时消费者必须等待
HANDLE thread[MAX_REQ]; //各线程的handle
DWORD pro_id[MAX_REQ]; //生产者线程的标识符
DWORD con_id[MAX_REQ]; //消费者线程的标识符
//对请求按时间排序的比较函数
bool cmp(request a, request b){ return a.ti<b.ti;}
/*****初始化函数*****/
void initial()
{
Pro_no = 1;
in=out=0;
memset(buffer, 0,sizeof(buffer));
printf("Please input the storage size: ");//读入仓库大小,即缓冲区大小
scanf("%d",&BUF_SIZE);
printf("Please input the request number: ");//读入仓库操作请求个数
scanf("%d",&req_num);
printf("Please input the request type(P or C) and occur time(eg:P 4):\n");
//读入各个请求的类型和时间
int i;
char ch[3];
for(i=0; i<req_num; i++)
{
printf("The No.%2d request: ", i);
scanf("%s %d", ch,&req[i].ti);
if(ch[0]=='P')req[i].p_c=P;
else req[i].p_c=C;
}
//将请求按时间轴排序
sort(req, req+req_num, cmp);
}
/*****生产者线程****/
DWORD WINAPI producer(LPVOID lpPara)
{
WaitForSingleObject(full_sema, INFINITE); //等待空位
WaitForSingleObject(mutex, INFINITE); //对仓库的操作权
//?跳过生产过程
//开始放产品进入仓库
printf("\nProducer %d put product %d in now...\n",(int)lpPara, Pro_no);
buffer[in]=Pro_no++;
in=(in+1)%BUF_SIZE;
Sleep(5);
printf("Producer %d put product success...\n\n",(int)lpPara);
ReleaseMutex(mutex); //释放仓库操作权
ReleaseSemaphore(empty_sema, 1,NULL); //非空位加一
return 0;
}
/****消费者线程****/
DWORD WINAPI consumer(LPVOID lpPara)
{
WaitForSingleObject(empty_sema, INFINITE);//等待非空位
WaitForSingleObject(mutex, INFINITE); //对仓库的操作权
//开始从仓库取出产品
printf("\nConsumer %d take product %d out now...\n",(int)lpPara, buffer[out]);
buffer[out]=0;
out=(out+1)%BUF_SIZE;
Sleep(5);
printf("Consumer %d take product success...\n\n",(int)lpPara);
//跳过消费过程
ReleaseMutex(mutex); //释放对仓库的操作权
ReleaseSemaphore(full_sema, 1,NULL); //空位加一
return 0;
}
int main()
{
initial(); //初始化各变量
//创建各个互斥信号
mutex=CreateMutex(NULL,false,NULL);
full_sema=CreateSemaphore(NULL, BUF_SIZE, BUF_SIZE,NULL);
empty_sema=CreateSemaphore(NULL, 0, BUF_SIZE,NULL);
int pre=0; //上一个请求的时间
for(int i=0; i<req_num; i++)
{
if(req[i].p_c==P) //创建生产者线程
{
thread[i]=CreateThread(NULL, 0, producer,(LPVOID)i, 0,&pro_id[i]);
if(thread[i]==NULL)return-1;
printf("\n*******Request at %d: Producer %d want to put a product in storage.\n", req[i].ti, i);
}
else //创建消费者线程
{
thread[i]=CreateThread(NULL, 0, consumer,(LPVOID)i, 0,&con_id[i]);
if(thread[i]==NULL)return-1;
printf("\n*******Request at %d: Consumer %d want to get a product out storage.\n", req[i].ti, i);
}
Sleep(req[i].ti-pre); //模拟时间
pre=req[i].ti;
}
//等待所有线程结束或超时,返回请求答复结果
int nIndex = WaitForMultipleObjects(req_num, thread, TRUE, 500);
if(nIndex == WAIT_TIMEOUT) //超时500毫秒
printf("\nSome request can't be satisfied !!!\n");
else
printf("\nAll request are satisfied !!!\n");
//销毁线程和信号量,防止线程的内存泄露
for(int i=0; i<req_num; i++)
CloseHandle(thread[i]);
CloseHandle(mutex);
CloseHandle(full_sema);
CloseHandle(empty_sema);
system("pause");
return 0;
}
6.3. 实现中遇到过的困难和解决方法
(1) 传递线程标号到线程里的时候,一开始,我用的是直接&i,然后在线程里再用(int)lpPara把i转换过来,结果打印出来的标号都是一个很大的数。后来细查了LPVOID的类型才知道,在传参时也要用(LPVOID)i再传进去。
比如:
thread[i]=CreateThread(NULL, 0, producer,(LPVOID)i, 0,&pro_id[i]);
(2) 编程时一时受C/C++常用编程习惯影响,在定义信号量时BUF_SIZE都加了-1,结果在调试时定义仓库大小为1时,信号量跟不起作用一样。
full_sema=CreateSemaphore(NULL, BUF_SIZE, BUF_SIZE,NULL);
empty_sema=CreateSemaphore(NULL, 0, BUF_SIZE,NULL);
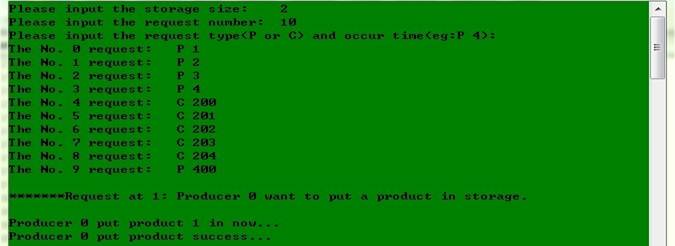
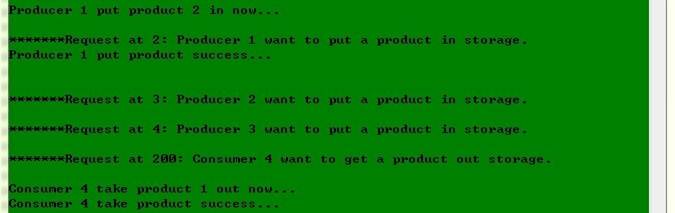
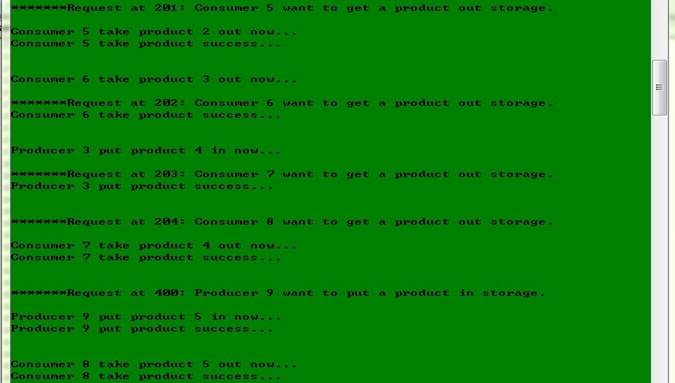
6.4. 运行示例及结果截图
(1) 全是生产者的情况

具体情况:3个生产者没有消费者,且生产者个数大于仓库个数
运行结果分析:只有一个生产者能成功地把产品放进仓库,而另外两个则没法完成任务。
(2) 全是消费者的情况
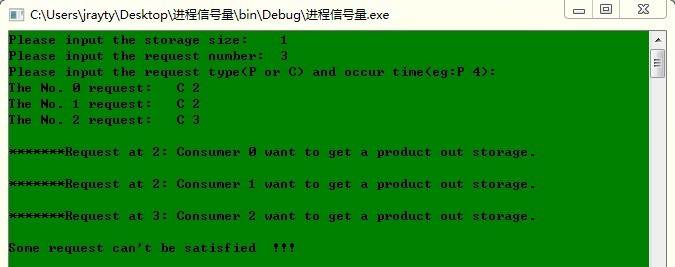
具体情况:3个消费者却没有生产者,仓库里原来没有任何产品
运行结果分析:虽然三个消费者都提出请求,但是由于信号量empty处始为0,故都没法得到满足。
(3) 生产者少于消费者且请求较慢的情况
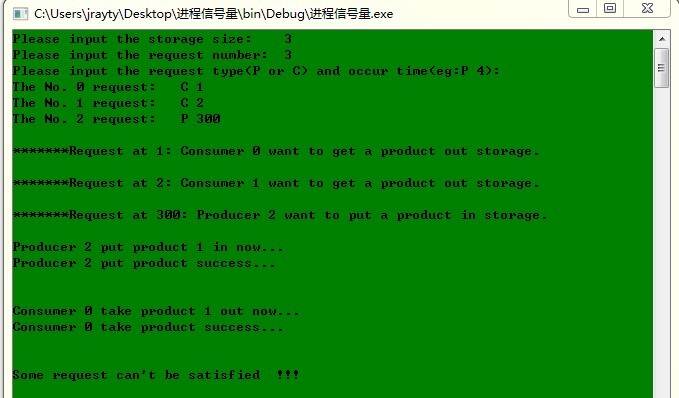
具体情况:2个消费者,一个生产者,但是生产者的请求远慢于消费者
运行结果分析:两个消费者很快提出请求,但是只有等到生产者提出请求并生产后才有一个消费者能被满足。而另外一个消费者还是无法得到满足。
(4) 综合情况
(截图见最后一页,终于挤到一页了。。。裁掉了某些空行。。。)
具体情况:仓库容量为2,先有4个生产者,后有5个消费者,最后还有1个生产者
运行结果分析:4个生产者提出请求后由于仓库大小只有2故只有2个能放进去(生产者等待空位),之后消费者消费产品,同时腾出空位,于是原来等待的生产者被调度,放产品进去。之后仓库为空,还有1个消费者没有产品可以消费,即消费者等待产品。最后来的生产者放产品后它才得以消费。最后所有要求都得到了满足。整个过程中没有子线程对仓库操作的冲突,即满足对仓库的互斥操作。
7. 心得和优化
看到很多同学用的是两个线程,一个不停生产,一个不停消费,但是个人觉得那样比较不容易反映出信号量的作用。而我这样人为设定一下,方便了学习者自己设定比如上面运行示例中的各种情况,从而更好地体会信号量实现的两进程/线程间的同步和互斥。
优化:
其实还可以增加一个参数,表示生产的或消费的产品的个数,从而更模拟实际生活。
不过我还没想好怎么改写WaitForSingleObject函数,ReleaseSemaphore函数倒是只要改写增加的个数即可。。