一、Kontagent
(一)简述:
Kontagent是个帮助社会化软件开发者分析用户行为的公司。其主要产品为K Suit平台。
(二)使用方法:
Kontagent工程已接入互联网的任何平台上,包括但不限于社区、手机和网络的应用程序。唯一的要求是应用具有独特的识别用户,并能够与我们的基于REST的API接口。
(三)统计指标:
K Suit平台为Facebook应用程序开发商、游戏工作室和内容发布商提供根据地理位置、年龄组、性别、用户参与时间、社交事件和其他变量分类的人口统计资料。使用K Suit的新版本,开发人员可以检查和优化广告效果、用户口碑增长、虚拟商品等等。主要分为社会分析和移动分析。
A、 社区分析:
可以更好地了解用户如何连接和您的应用程序或服务的互动,并使用这些见解,永远改善您的业务。
1、 用户行为分析:根据时间记录用户访问、保留、付费等数据
l 活跃用户数分析
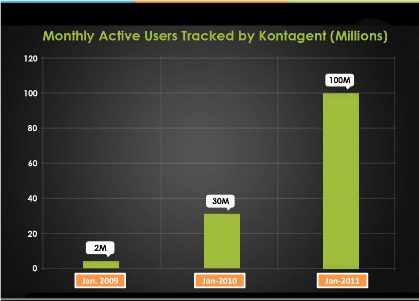
图1.
l 每日滞留
对于企业客户,除了每周和每月的保留数据,增加了每天的保留数据。选项卡下,可以发现每日滞留。请注意,对于大多数客户来说,每天的保留数据只是当天的,我们没有记录历史的每天保留数据。
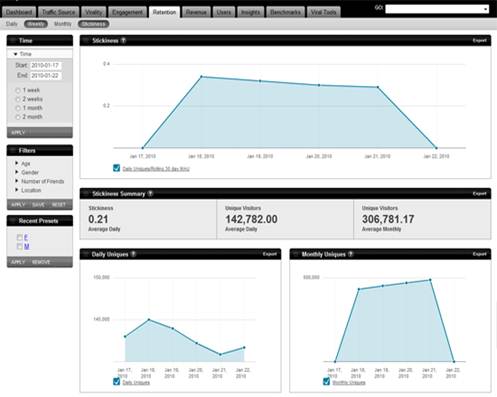
图2.
l 粘性
“粘性”指标是一个在过去几个月已经变得越来越流行的度量 。“粘性”度量DAU /滚动30天。我们已经加入此固定卡。
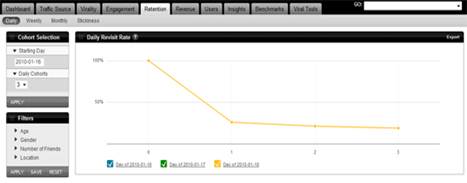
图3.
l 付费用户数、免费用户数
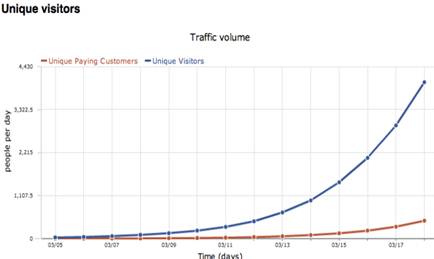
图4.
2、 自定义事件标记和时间轴分析:可以针对应用程序的任何时间定义可见度。
可看到新用户和老用户,可以在不同的时间段分析用户的行为。
l 比如事件捆绑:
可以通过在您选定的事件列表中选择一个或多个事件的事件束。一个弹出的windown会出现所有选定的事件,然后你可以选择哪些事件是包含在你的Bundle。

图5.
3、 渠道分析:分析用户来源,此项可分析用户是从哪个连接过来的,
可分析广告的投放效果。
4、 虚拟经济调整:分析消费的行为。
l 各种消费方式的消费数
图6.
l 随着时间和等级的不同,消费数额的趋势图

图7
l 每天花费不同数额购买同一物品的玩家数,分析应该如何标价、游戏应该如何优化。

图8
l 分析哪种虚拟物品更能驱动玩家去消费

图9
l 每天同一物品卖不同价钱的收入情况
图10.
5、 收入跟踪:付款方式、交易金额。
l 分析玩家每天的充值数量
图11.
l 分析每天的充值收入以及每天的消费
图12.
l 分析每种渠道每天的收入
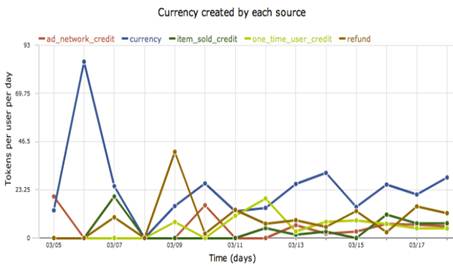
图13.
6、 实时应用监测:对应用程序进行实时监控,可以检测新版本的业务问题。
l 实时监控仪表板
选择的时间段刷新率。此前,仪表盘自动刷新10秒的增量。我们知道一些社会游戏和一些其他的用例更长的时间增量的更有意义,尤其是当用户量低。
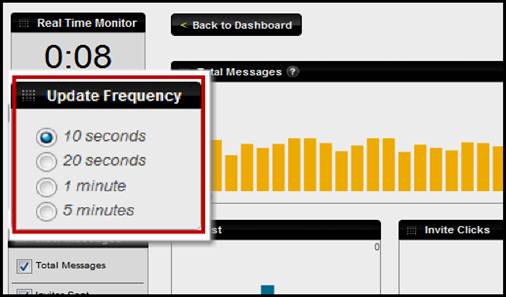
图14
l 最后更新交通源和见解时报
-几乎所有的Kontagent系列数据每小时更新一次,但像一些交通源和见解页每日更新。我们添加了一个“最近更新”字段流量来源和见解的网页,让你知道时,每天的数据更新。
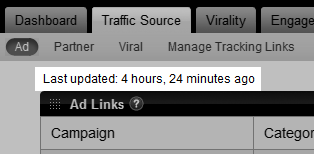
图15.
7、 专业服务器人员帮助客户调整和解释数据。
8、 发掘潜在的用户群。
B、 移动分析:
K suit移动是第一个纯企业级的分析解决方案,内置,可以帮助移动应用程序开发,比如访问需要提高你的用户货币化收购、参与、保留所有指标。
1、 查看设备、操作系统:可根据手机操作系统、位置、设备类型进行过滤。
2、 专业服务器人员帮助客户调整和解释数据。
3、 自定义事件标记和时间轴分析:可以针对应用程序的任何时间定义可见度。
可看到新用户和老用户,可以在不同的时间段分析用户的行为。
4、 虚拟经济调整:分析用户充值和消费的行为。
5、 收入跟踪:付款方式、交易金额。
6、 实时应用监测:对应用程序进行实时监控,可以检测新版本的业务问题。
(四)安全风险评估
A、 是否违反facebook服务?
不,你是通过我们的服务在不违反Facebook的服务条款的前提下收集数据。作为分析平台,我们已经开了绿灯处理FACEBOOK的UID。我们作为客户的代理行为,任何被传递给我们的数据是客户的服务器到Kontagent服务器的客户端。
B、 是否会出售或分享我的数据?
决不会出售任何数据,客户在使用期间平台期间对数据有充分的自主权。
C、 哪些平台支持Kontagent?
Kontagent目前支持Facebook和其他社交网络。也完全内置移动开发出Android和iOS SDK库。
D、 如果Kontagent方宕机了,有什么影响?
不会有应用程序的性能的影响,如果我们的系统停机,Kontagent采用了连续可用性监测数据采集服务器的分布式设置。
第二篇:数据分析工具生成pmml调研报告_V1.0_20xx08
DW开源工具
调研
DW工具调研报告
目 录
第一章、概述 ................................................................................................................................... 3
1.1、PMML概述: ................................................................................................................. 3
1.2、支持PMML的收费工具: ............................................................................................ 4
1.3、支持PMML的开源工具: ............................................................................................ 4
1.4、目前不支持的PMML工具: ........................................................................................ 4
1.5、内容安排: ...................................................................................................................... 4
第二章、收费DM工具 .................................................................................................................. 5
2.1、SAS 公司的Enterprise Miner: .................................................................................... 5
2.1.1工具说明 .................................................................................................................. 5
2.1.2使用方式说明 .......................................................................................................... 5
2.2、IBM 公司的Intelligent Miner ........................................................................................ 8
2.2.1工具说明 .................................................................................................................. 8
2.2.2使用方式说明 .......................................................................................................... 9
2.3、IBM SPSS Modeler: .................................................................................................... 13
2.3.1工具说明 ................................................................................................................ 13
2.3.2使用方式 ................................................................................................................ 14
第三章、开源DM工具 ................................................................................................................ 14
3.1、Weka: ........................................................................................................................... 14
3.1.1 程序界面 ............................................................................................................... 14
3.1.2 代码 ....................................................................................................................... 16
3.2、R: ................................................................................................................................. 18
3.3、knime: .......................................................................................................................... 19
3.1.2 程序界面 ............................................................................................................... 20
第四章、总结 ................................................................................................................................. 20
第2页 共 21页
DW工具调研报告
第一章、概述
1.1、PMML概述:
数据挖掘任务主要由以下步骤组成:
? 定义数据字典:定义对分析问题有价值的数据变量。
? 预处理数据:通过对现有变量的衍生、映射、合并等操作,产生适
合于建模的变量。
? 制定挖掘模式:指定数据挖掘建模过程处理异常值和缺失值的策略。
? 表示数据挖掘模型:记录模型的结构和参数等信息。
? 预测评价:将测试数据集应用于所获得的模型,以各种准则获得性
能评。
根据数据挖掘任务的需要,国际组织制定了数据挖掘的描述标准语言PMML。 PMML(Predictive Model Markup Language) 是一个开放的工业标准,它以 XML 为载体将上述数据挖掘任务标准化,可以把某一产品所创建的数据挖掘方案应用于任何其它遵从 PMML 标准的产品或平台中 , 而不需考虑分析和预测过程中的具体实现细节。使得模型的部署摆脱了模型开发和产品整合的束缚,为商业智能产品、数据仓库和云计算中的数据挖掘模型的应用环境开拓了新的篇章。
PMML 标准是数据挖掘过程的一个实例化标准,它按照数据挖掘任务执行过程,有序的定义了数据挖掘不同阶段的相关信息:
? 头信息
? 数据字典
? 数据转换
? 模型表示
? 预测评价
有关具体的PMML标准的描述参见“pmml详解.doc”,此次调研的工具都支持到pmml 3,不支持pmml4
第3页 共 21页
DW工具调研报告
1.2、支持PMML的收费工具:
? SAS 公司的Enterprise Miner,部分支持,支持预测评价的pmml生成 ? IBM 公司的Intelligent Miner,全部支持,支持pmml格式的生成和导入 ? SPSS 公司的Clementetine(已经被IBM公司收购),支持pmml格式的生
成和导入
1.3、支持PMML的开源工具:
? R,网上的信息说支持,但是实际没有找到支持方式,Version 15.1。 ? Weka,部分支持,在gui界面下不支持pmml文件,但是可以通过命令
行方式使用pmml。
? KNIME支持,可以使用weka的算法,在gui界面上提供了pmml的加
载插件,支持部分数据挖掘算法
1.4、目前不支持的PMML工具:
? RapidMiner 下载后没找到使用pmml的方式,正在查他的文档
? Orange 正在下载
? Sqlserver 数据挖掘工具,使用自身的数据挖掘模型,在192.168.7.181
上有安装
1.5、内容安排:
各个章节的描述内容:
? 第二章介绍收费工具对于PMML的支持。
? 第三章介绍开源工具对于PMML的支持。
? 第四章对于PMML的支持进行了总结。
第4页 共 21页
DW工具调研报告
第二章、收费DM工具
本章介绍SAS 公司的Enterprise Miner,IBM 公司的Intelligent Miner,SPSS 公司的Clementetine(已经被IBM公司收购),对于pmml的支持。
2.1、SAS 公司的Enterprise Miner:
SAS 的Enterprise Miner 支持PMML的模型Assess--评分,由于没有下载到SAS Enterprise Miner 因此以下信息取自网络。
SAS Enterprise Miner 支持对于以下算法的PMML模型评分
包括:1,关联分析算法
2,分类算法
3,聚类算法
SAS Enterprise Miner在 Assess模型的时候生成PMML文件,Assess也是SAS Enterprise Miner 的一个模块。可以拖到画布上。
2.1.1工具说明
SAS Enterprise Miner把统计分析系统和图形用户界面(GUI)集成在一起,并与SAS协会定义的数据挖掘方法——SEMMA方法,即抽样(Sample)、探索(Explore)、修改(Modify)建模(Model)、评价(Assess)紧密结合,其中评价(Assess)对于SAS 提供的所有数据挖掘算法都支持生成PMML。
SAS Enterprise Miner简称EM,它的运行方式是通过在一个工作空间(workspace)中按照一定的顺序添加各种可以实现不同功能的节点,然后对不同节点进行相应的设置,最后运行整个工作流程(workflow),便可以得到相应的结果。
2.1.2使用方式说明
EM中工具分为七类:
第5页 共 21页
DW工具调研报告
? Sample类 包含Input Data Source、Sampling、Data Partition ? Explore类 包含Distribution Explorer、Multiplot、Insight、
Association、Variable Selection、Link Analysis
(Exp.)
? Modify类 包含Data Set Attribute、Transform Variable、Filter
Outliers、Replacement、Clustering、SOM/Kohonen、
Time Series(Exp.)
? Model类 包括Regression、Tree、Neural Network、
Princomp/Dmneural、User Defined Model、Ensemble、
Memory-Based Reasoning、Two Stage Model
? Assess类 包括Assessment、Reporter
? Scoring类 包括Score、C*Score
? Utility类 包括Group Processing、Data Mining Database、SAS
Code、Control point、Subdiagram
其中的Assess 类支持生成PMML。
使用方式为:EM用来评估模型的工具是Assessment节点,Assessment节点通过运行Test数据可以对所有模型的精确性进行检验。
(1) 将Assessment节点拖到工作区中,放到Regression节点的下面,分
别连接Regression和Tree节点到Assessment节点。
第6页 共 21页
DW工具调研报告
(2) 右键单击Assessment节点,选择Run,运行过程中从Replacement
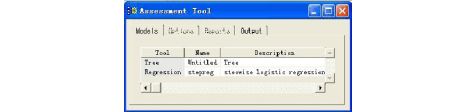
到Assessment节点四周会出现绿色方框,运行结束在弹出对话框中选择“是”,会出现Assessment Tool窗口
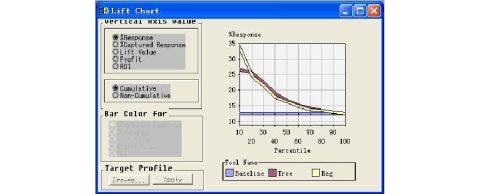
(3) 按住Shift键,选择Tree和Regression两个模型,单击SAS主菜单
中的“工具”选择“升降图”出现Lift Chart窗口
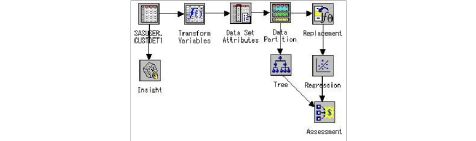
第7页 共 21页
DW工具调研报告
2.2、IBM 公司的Intelligent Miner
DB2 数据挖掘方法使用 Intelligent Miner,后者是 InfoSphere? Warehouse 的一部分。Intelligent Miner? 将这些结果存储为预测模型标记语言(Predictive Model Markup Language,PMML)格式,这种格式基于 XML。自 DB2 9 发布以来,存储为 XML 格式的信息就可以使用 XQuery 进行有效处理。了解如何轻松使用 DB2 XQuery,根据您的数据挖掘结果创建您自己的访问方法。
数据挖掘任务的结果称为数据挖掘模型,它们存储在使用 PMML 标准的表中。这个标准基于 XML,允许在不同数据挖掘提供者之间轻松交换数据。这样一个模型然后可以应用到新数据上,这称为记分(scoring)。
2.2.1工具说明
Intelligent Miner 通过 UDF 和 STP 集成到 DB2 中。您可以使用一组 SQL 语句或 InfoSphere Warehouse DesignStudio
图形界面来创建一个数据挖掘模型。 第8页 共 21页
DW工具调研报告
图形界面是一种更加方便的方法。PMML 模型存储在 DB2 表中,这些表既可用于记录新数据,也可用于提取信息。
创建模型之后,可以使用 Intelligent Miner Visualizer 以图形方式查看模型,也可以使用现有的 Intelligent Miner 提取功能来通过 SQL 获得一些信息。例如,您可以提取集群模型的一个概述,其中显示集群数量、使用的字段和模型质量。Eg:
SELECT
"ID" AS "CLUSTERID", CAST ("NAME" AS CHAR(20)) AS "CLUSTERNAME", "SIZE", CAST ("HOMOGENEITY" AS DEC(5,2)) AS "HOMOGENEITY"
FROM TABLE
(IDMMX.DM_getClusters((
SELECT "MODEL"
FROM IDMMX."CLUSTERMODELS"
WHERE
"MODELNAME"='BANK.CUSTOMERS_SEGMENTS')))
AS "CLUSTERS" ORDER BY SIZE DESC;
2.2.2使用方式说明
结合使用 XQuery 和 Intelligent Miner
大多数信息都可以使用可用的数据挖掘函数提取,但是还有一些信息无法提取。您可以结合使用 XQuery 函数和 Intelligent Miner 函数来直接从 PMML 模型读取这些隐藏的部分。
Intelligent Miner 目前不允许提取集群附加字段的细节。一个字段可以是活动的,也可以是附加的,具体取决于它对于计算集群的价值。例如,充当 DB2 中的主键且始终具有不同值的字段会自动移动到附加字段,因为它们无法提供有助于了解集群的信息。
第9页 共 21页
DW工具调研报告
您可以在 PMML 模型的 XML 节点 MiningField 中找到隐藏的信息。如果属性 usageType 具有值 Supplementary,那么它表示一个附加字段。活动字段是默认的使用类型,因此它不会在 PMML 文件中表示出来。
一个 PMML MiningSchema 示例。
<MiningSchema>
<MiningField name="AGE"/>
<MiningField name="AVERAGE_BALANCE"/>
...
<MiningField name="SAVING_ACCOUNT"/>
<MiningField name="ID" usageType="supplementary"/>
</MiningSchema>
下面的例子展示了如何在 DB2 中实现一个 UDF 来提取所有集群字段,以及显示这些字段的使用类型。
CREATE FUNCTION getClusterMiningFields (mname varchar(128))
RETURNS TABLE (name varchar(20),
usagetype varchar(20))
LANGUAGE SQL
BEGIN ATOMIC RETURN
select X.name,
CASE WHEN X.usageType IS NULL THEN 'active'
ELSE X.usageType END
from XMLTable('$DATA//*:MiningField' PASSING
XMLPARSE(document (
select
IDMMX.DM_expClusModel(cm.MODEL)
from IDMMX.CLUSTERMODELS cm
where MODELNAME=mname)) as "DATA" columns
name varchar(20) path '@name',
usageType varchar(20) path '@usageType') as X;
END@
UDF 被声明为一个表函数,这意味着它返回一个临时表,而不是一个值。因为它是使用 SQL 编写的,所以 LANGUAGE 属于 SQL。
UDF 的主体在 BEGIN 与 END 标记之间实现。所有结果列都在 SQL/XQuery 第10页 共 21页
DW工具调研报告
语句的选择部分中指定。在示例中,这些列是 X.name 和 X.usageType,它们是 XMLTABLE 表达式的输出列。X.usageType 的 case 语句表示活动的 XML 属性没有写入 PMML 文档。
XMLPARSE 是必需的,因为 PMML 文档本身没有直接存储在一个 XML 列中。该文档需要使用 IDMMX.DM_expClusModel 函数从一个 BLOB 列中导出,然后应该使用 XMLPARSE 函数将其复制到一个 XML 值中。
一旦文档可以作为 XML 值使用,您就可以使用 XQuery 来处理它, XQuery 示例所示。
要调用创建函数语句,将这些语句放入一个文件中,并使用清单 16 中所示语法调用这个文件。注意,没有使用传统的语句结束字符,因为在 UDF 中需要使用该字符。
调用包含创建函数语句的文件
db2 -td@ -vf createClusterFieldUDF.db2
当在一个 select 语句中调用 UDF 时,您将获得字段的信息,包括哪些字段是活动的,哪些是附加的,如清单 17 所示。
清单 . 读取字段信息
db2 select t1.name, t1.usagetype from table
(getClusterMiningFields('BankCustomerSegments')) t1
NAME USAGETYPE
-------------------- --------------------
AGE active
NBR_YEARS_CLI active
GENDER active
MARITAL_STATUS active
PROFESSION active
SAVINGS_ACCOUNT active
HAS_LIFE_INSURANCE active
INT_CREDITCARD active
ONLINE_ACCESS active
JOINED_ACCOUNTS active
BANKCARD active
第11页 共 21页
DW工具调研报告
CLIENT_ID supplementary
AVERAGE_BALANCE active
NO_CRED_TRANS active
NO_DEBIT_TRANS active
15 record(s) selected.
相同的功能也可以添加到一个 STP 中。创建 STP 的语法看起来稍有不同,但代码本身完全一样,如清单 18 所示。
清单 . 使用一个 STP
CREATE PROCEDURE getClusterMiningFields
(
in mname varchar(128)
)
LANGUAGE SQL
RESULT SETS 1
BEGIN
DECLARE cursor1 CURSOR WITH RETURN FOR
select X.name,
CASE WHEN X.usageType IS NULL THEN 'active'
ELSE X.usageType END
from XMLTable('$DATA//*:MiningField' PASSING
XMLPARSE(document (
select
IDMMX.DM_expClusModel(cm.MODEL)
from IDMMX.CLUSTERMODELS cm
where MODELNAME=mname)) as "DATA" columns
name varchar(20) path '@name',
usageType varchar(20) path '@usageType') as X;
OPEN cursor1;
END@
您可以使用 call 语句从 DB2 命令行窗口调用 STP。输出(如清单 19 所示)与您在 UDF 实现中看到的结果完全一样。
清单 . 从 DB2 命令行窗口调用 STP 的结果
第12页 共 21页
DW工具调研报告
db2 call getClusterMiningFields('BankCustomerSegments')
Result set 1
--------------
NAME 2
-------------------- --------------------
AGE active
NBR_YEARS_CLI active
GENDER active
MARITAL_STATUS active
PROFESSION active
SAVINGS_ACCOUNT active
HAS_LIFE_INSURANCE active
INT_CREDITCARD active
ONLINE_ACCESS active
JOINED_ACCOUNTS active
BANKCARD active
CLIENT_ID supplementary
AVERAGE_BALANCE active
NO_CRED_TRANS active
NO_DEBIT_TRANS active
15 record(s) selected.
Return Status = 0
结合使用 XQuery 和 Intelligent Miner 轻松编写您自己的 PMML 提取函数,以及将结果作为关系数据传入您的 SQL。所有操作无需编程语言,并且创建 UDF 的过程更加简单,因为它受图形工具支持。
2.3、IBM SPSS Modeler:
IBM SPSS Modeler工具完全支持pmml模型,用户生成的数据挖掘的配置文件可以直接保存为pmml文件。同时他支持pmml文件的导入。
2.3.1工具说明
IBM SPSS Modeler工具使用数据流方式进行数据挖掘,通过将可视化的模块 第13页 共 21页
DW工具调研报告
串联进行数据挖掘的配置。由于IBM SPSS Modeler完全支持pmml因此具体的使用方式就不列出,具体请参考使用手册。
2.3.2使用方式
完全支持,配置完成后,可以直接保存为pmml格式的xml文件。具体使用方式参考用户手册。
第三章、开源DM工具
3.1、Weka:
Weka代码中支持从pmml文件导入模型,和导出pmml模型,但是gui目前的配置文件保存方式是kfml文件,因此gui方式下无法对pmml格式的文件进行操作。但是在命令行方式下可以进行pmml的操作。
3.1.1 程序界面
Weka中对于数据做分析的界面有两个一个是explorer,一个是knowledgeflow,其中knowledgeflow 可以完全包含 explorer中的功能。
Explorer界面:
第14页 共 21页
DW工具调研报告
Explorer中不支持导出pmml功能
Knowledgeflow界面如下:
第15页 共 21页
DW工具调研报告
加载配置的文件时只能是weka自定义的配置文件,不支持导出pmml功能
3.1.2 代码
1,工厂方法:weka使用工厂方式根据pmml文件生成挖掘模型。类名为PMMLFactory.java
工厂类中支持加载,并导出pmml文件。
2,pmml实现类,在pmml包中,目前支持的算法为
REGRESSION_MODEL ("Regression"),
GENERAL_REGRESSION_MODEL ("GeneralRegression"),
NEURAL_NETWORK_MODEL ("NeuralNetwork"),
TREE_MODEL ("TreeModel"),
RULESET_MODEL("RuleSetModel"),
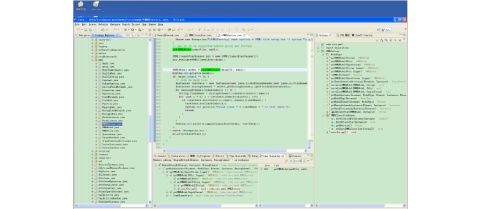
SVM_MODEL ("SupportVectorMachineModel");
第16页 共 21页
DW工具调研报告
3,测试类的测试方法如下:
PMMLModel model = getPMMLModel(args[0], null);
System.out.println(model);
if (args.length == 2) {
// load an arff file
Instances testData = new Instances(new java.io.BufferedReader(new java.io.FileReader(args[1])));
Instances miningSchemaI = model.getMiningSchema().getFieldsAsInstances();
if (miningSchemaI.classIndex() >= 0) {
String className = miningSchemaI.classAttribute().name();
for (int i = 0; i < testData.numAttributes(); i++) {
if (testData.attribute(i).name().equals(className)) {
testData.setClassIndex(i);
System.out.println("Found class " + className + " in test data.");
break;
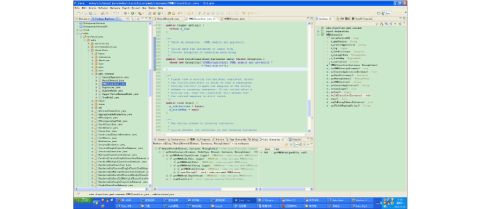
}
第17页 共 21页
DW工具调研报告
}
}
System.out.println(applyClassifier(model, testData));
3.2、R:
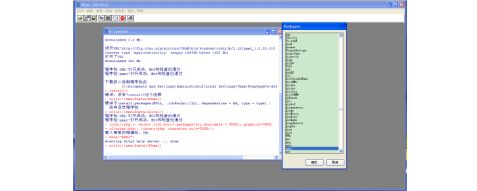
R主要使用命令行方式,使用数据包中提供的函数集,进行数据处理,和数据挖掘。在R的样例代码中没有找到和pmml相关的内容,在R的使用手册中也没有找到相关内容。经过调研,R需要手动下载支持pmml的包,并安装pmml包后可以有函数支持pmml。
选择安装程序包后,弹出下图
选择pmml,确定后zip包开始下载。
下载完毕后选择安装zip包,选定刚才下载的2个包,即可。
第18页 共 21页
DW工具调研报告
提供的方法为pmml(),程序帮助如下:
pmml(model, model.name="Rattle_Model", app.name="Rattle/PMML",
description=NULL, copyright=NULL, transforms=NULL, dataset=NULL, ...)
参数:
model an object to be converted to PMML.
model.name a name to give to the model in the PMML.
app.name the name of the application that generated the PMML. description a descriptive text for the header of the PMML.
copyright the copyright notice for the model.
transforms a coded list of transforms performed.
dataset
...
例子:
# Build a simple lm model
(iris.lm <- lm(Sepal.Length ~ ., data=iris))
# Convert to pmml
pmml(iris.lm)
the orginal training dataset, if available. further arguments passed to or from other methods.
3.3、knime:
从knime2.0开始,knime可以导入 (pmml3.0,3.1,3.2)版本的pmml
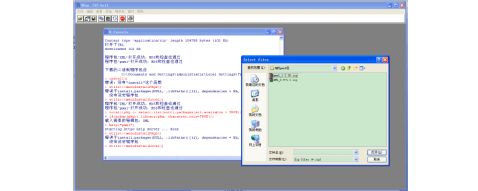
格式的文件, 第19页 共 21页
DW工具调研报告
和导出v3.1版本的pmml文件。Knime提供 pmml reader 插件读取pmml文件,并提供pmml writer 插件写出 pmml文件。
3.1.2 程序界面
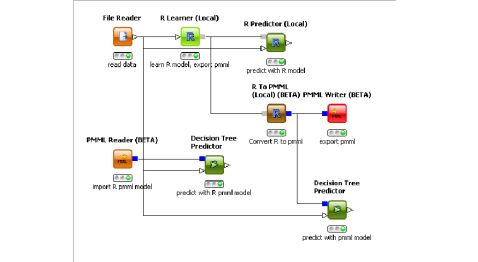
下图是使用pmml的工作流的流程,工作流从pmml reader读取 数据挖掘配置,并进行预测,
同时,调用R的数据挖掘函数,将预测模型导出为pmml格式。
第四章、总结
根据前3章节的叙述,总结如下:
1,在收费工具部分,业内领先的数据挖掘工具,基本支持PMML方式,同时,提供数据仓库产品的公司提供的数据挖掘工具基本都可以将数据挖掘模型保存为pmml格式。Sqlserver的 挖掘工具有自己的格式,目前没有找到支持
pmml 第20页 共 21页
DW工具调研报告
的依据。IBM公司的数据挖掘产品全部支持pmml的生成。
, 2,开源工具部分,R,weka,knime 都支持pmml方式,其中knime专门提供了生成pmml的插件,weka类中提供了读取和保存pmml格式的方法,并有测试类,但是界面上没有找到使用方法,只能通过命令行方式调用。R,的文档中没有找到pmml的方式,在他的第三方的包里有对pmml的支持,专门提供了生成pmml的函数。Rapid miner 在界面上没有找到pmml的使用方式,但是他的文档中描述了对于pmml的错误信息,需要继续验证下。
下一步操作,继续验证 rapid miner的 pmml支持程度,和R对于pmml的支持程度。
第21页 共 21页