
信息论与编码上机实习
学生姓名: XX
班 级: XXXXX
学 号: XXXXXXXX
指导老师: XX
实验一 字典编码
一、实验题目
1、输入:
①The Lempel Ziv algorithm can compress the English text by about fifty five percent.
②The cat cannot sit on the canopy of the car.
2、输出:经过字典编码后生成的码字。
二、实验目的
1、理解和掌握字典编码的原理;
2、理解和掌握字典译码的原理。
三、算法设计

四、程序分析
1.用结构体存储字符串及其对应的字典编码;
2.用链表存储整个字典;
3.dictionary()子函数的作用是将当前字符同链表中的字典相比较,若存在与字典中,则向结构体的数组里存放发送信息的下一位,直到当前数组中的字符串和链表字典不相等则将该字符串存储到链表中,并将标号存储到加最后一位字符之前的字符串对应的结构体的code,更新字典。
4.main()函数主要是实现初始字典的构建,即’a’-’z’和’A’-’Z’的存储。
五、程序代码
子函数:
#ifndef DICTIONARY_H_INCLUDED
#define DICTIONARY_H_INCLUDED
void dictionary(SLNode *head,int x1,char c1[],int num)
{
char c3[5];
DataType C2;
int i;
int flag=1,flag1=0,flag2=0,k=1;
SLNode *p;
printf("The message is:\n %s\n",c1);
printf("The codeword is:\n");
for(i=0;i<x1;i=i+flag2)
{
c3[0]=c1[i];
c3[1]='\0';
p=head;
while(p->next!=NULL)
{
if(strcmp(c3,p->data.lable)) //c3与链表中的值不相等
{
p=p->next;
flag1=0;
}
else //c3与链表中的值相等
{
c3[flag++]=c1[i+k];
k++;
c3[flag]='\0';
flag2=flag-1;
flag1=1;
printf("%d ",p->data.code);
if(i+k>=x1) break;
continue;
}
}
if(flag1==0) //插入新元素
{
strcpy(C2.lable,c3);
C2.code=num++;
ListInsert(head,ListLength(head),C2);
flag=1;
flag1=1;
k=1;
memset(c3,0,5);
}
}
printf("\n");
p=head;
printf("The dictionary is:\n");
while(p->next!=NULL)
{
printf(" %d -- 【%s】\n",p->next->data.code,p->next->data.lable);
p=p->next;
}
}
#endif // DICTIONARY_H_INCLUDED
主函数:
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
typedef struct
{
char lable[5];
int code;
}DataType;
#include "list.h"
#include "dictionary.h"
int main()
{
SLNode *head,*head1;
DataType C2;
int x1,x2,num=0;
char c1[]="The Lempel Ziv algorithm can compress the English text by about fifty five percent.";
char c2[]="The cat cannot sit on the canopy of the car.";
char s1[]="\0",s2[]="\0";
ListInitiate(&head);
x1=strlen(c1);
ListInitiate(&head1);
x2=strlen(c2);
for(s2[0]='A';s2[0]>='A'&&s2[0]<='Z';s2[0]++,num++)
{
strcpy(C2.lable,s2);
C2.code=num;
ListInsert(head,ListLength(head),C2);
ListInsert(head1,ListLength(head1),C2);
}
for(s1[0]='a';s1[0]>='a'&&s1[0]<='z';s1[0]++,num++)
{
strcpy(C2.lable,s1);
C2.code=num;
ListInsert(head,ListLength(head),C2);
ListInsert(head1,ListLength(head1),C2);
}
s1[0]='.';
strcpy(C2.lable,s1);C2.code=num++;
ListInsert(head,ListLength(head1),C2);
dictionary(head,x1,c1,num);
dictionary(head1,x2,c2,num);
return 0;
}
六、程序运行结果





七、心得体会
这是上机实习的第一个程序,感觉要把学到的知识融会贯通运用到程序里,没有想象中的简单,光是刚开始想用什么样的数据类型存储字典就花费了好长的时间,第一节课并没有成功完成整个程序,但好在大体的概况已经出来了,课后又花了一点时间,终于编码成功。
实验二 计算信道容量
一、实验题目
1、已知:信源符号个数r、信宿符号个数s 、信道转移概率矩阵P。
2、输入:任意的一个信道转移概率矩阵。信源符号个数、信宿符号个数和每个具体的转移概率在运行时从键盘输入。
3、输出:信道容量C。
二、实验目的
1、理解和掌握信道容量的概念和物理意义;
2、理解计算离散信道容量的迭代算法。
三、算法设计

四、程序分析
1、信道容量:
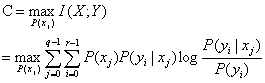
2、当正向传输的信道容量和反向传输的信道容量在误差范围内时表示此时信道稳定,该信道容量即为所求。
3、计算正、反向传输的信道容量的迭代算法公式如下:
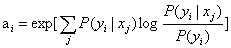
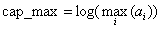
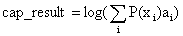
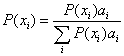
五、程序代码
/**********************************************************************************************
【名称】:信道容量迭代法
【函数】:计算a[i]函数、计算cap_result函数、计算cap_max函数、主函数
【思路】:利用迭代法,使cap_result初步逼近cap_max,当误差小于e时,cap_result即为信道容量
**********************************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int X_num,Y_num; // X_num为信源个数,Y_num为信宿个数
int n=1;
double e; // 迭代法精度误差
double PXi[50]; // 输入符号的概率P(xi)数组
double P[50][50]; // 信道转移概率矩阵
double a[50];
double cap_result;
double cap_max;
// 迭代法参数a[i]、C、CC
double result; // 信道容量
/**************************************************************************
函数名:double Calculate_a(int k,double PXi[])
功能:计算并输出迭代法所需的参数a[k]
参数:
返回值:a[k],也就是P(yi|xj)*log(P(yi|xj)/P(yi))/log2对i从0到Y_num-1求和
**************************************************************************/
double Calculate_a(int k,double PXi[])
{
int i,j;
double sum1 = 0;
for(j=0;j<Y_num;j++)
{
double sum = 0; // 必须在此处令sum置0
for(i=0;i<X_num;i++) // 求和PXi[i] * P[i][j]得到P(yj)
{
sum += PXi[i] * P[i][j];//P[i][j]表示P(yj|xi);
}
sum1 += P[k][j] * log(P[k][j] / sum); //求和得到a[k]
}
printf("a[%d] = %f\t",k,sum1); // 输出a[k]
return exp(sum1);
}
/**************************************************************************
函数名:double Calculate_cap_result(double PXi[],double a[])
功能:计算并输出迭代法所需的参数cap_result
参数:
返回值:cap_result,也即是用来逼近最值的参数
**************************************************************************/
double Calculate_cap_result(double PXi[],double a[])
{
int i;
double sum=0;
for(i=0;i<X_num;i++)
{
sum += (PXi[i] * a[i]);
}
printf("较小值 =%f \n",log(sum)); // 输出迭代法所需的参数cap_result
return log(sum);
}
/**************************************************************************
函数名:double Calculate_cap_max(double a[])
功能:计算并输出迭代法所需的参数cap_max
参数:
返回值:cap_max,也即a[k]的最大值 */
/**************************************************************************/
double Calculate_cap_max(double a[])
{
int i;
double max_a = a[0];
for(i=0;i<X_num;i++)
{
if(a[i] > max_a)
{
max_a = a[i];
}
}
printf("较大值 =%f",log(max_a));
return log(max_a);
}
int main()
{
int i,j,flag=1;
printf("\n请输入信源个数X_num= \n\t\t\t");
scanf("%d",&X_num);
printf("\n请输入信宿个数Y_num= \n\t\t\t");
scanf("%d",&Y_num);
printf("\n请输入信道转移概率矩阵【P(Yj|Xi)】\n\n");
for(i=0;i<X_num;i++)
{
for(j=0;j<Y_num;j++)
{
printf("P[%d][%d]=",i,j);
scanf("%lf",&P[i][j]);
}
}
printf("\n请输入迭代法精度误差(e):");
scanf("%lf",&e);
for(i=0;i<X_num;i++)
PXi[i] = 1 / ((double)X_num); // 初始化输入符号的概率P(xi),等概率预处理
do
{
printf("\n第%d次迭代参数\n",n);
for(i=0;i<X_num;i++)
a[i] = Calculate_a(i,PXi);
printf("\n");
cap_result= Calculate_cap_result(PXi,a);
cap_max= Calculate_cap_max(a);
printf("\n");
if(cap_max-cap_result>= e) // PXi[i]重新赋值
{
double sum = 0;
for(i=0;i<X_num;i++)
{
sum += (PXi[i] * a[i]);
}
for(i=0;i<X_num;i++)
{
PXi[i] = ((PXi[i] * a[i]) / sum);
}
n ++;
}
}while(cap_max-cap_result>= e);
printf("\n\n迭代次数为: %d\n" ,n);
for(i=0;i<X_num;i++)
{
printf("最佳信源概率:%f\n" ,PXi[i]);
}
result = (cap_result/ log(2));
printf("信道容量为: %f\n\n",result);
return 0;
}
六、程序运行结果

七、心得体会
在上机之前我对于老师讲解的信道容量的解释并不特别理解,至于在上机课上完全不知道如何设计程序算法,只能参照着老师PPT上的算法写程序;之后与同学进行了讨论,也把算法算了两遍,对信道容量的理解加深了一些,对算法流程也了解了些,虽然还是没有算出如算法所写的公式,但在计算过程中,对知识有了更深的理解。
实验三 汉明码编码与译码
一、实验题目
1、写一个错误生成器模块,在给定的一个比特流作输入时,它的输出流的每个比特流都以概率p发生了改变,即比特错误概率为p。
2、对m=3,将汉明码编码后的比特流输入到上述模块,然后对收到的字用译码器进行译码。
二、实验目的
1、理解和掌握汉明码编码与译码的原理;
三、算法设计

四、程序分析
1、错误生成模块:任一给以p,系统任意生成一数,若比p小则让其出错,否则不出错。
2、编码:首先随机生成H矩阵,由H矩阵生成G矩阵,利用C=mG编码。
3、解码:
若v*H’=0,则没有出错,直接输出v中前k位;
若v*H’!=0,列出所有的e和e*H’得到伴随阵s,若能在s中找到s=v*H
则c0=v-e,输出c0中前k位;若找不到s,则输出“错误位数大于纠错能力,无法解码”。
五、程序代码
#include <iostream>
#include <string> // 字符串处理头文件
#include <iomanip> // 输入输出控制头文件
#include <math.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
void Err_Pro();
void Hamming_Decode();
int m,n,k,t,err,r,R[100],N[100],COUNT[100],num[100][100],Th[100][100],PT_S[100][100],PT_D[100][100];
int H[100][100],HT[100][100],Ig[100][100],P[100][100],G[100][100],Ibit[100],Cbit[100],Err_Cbit[100],V[100];
/**************************************************************************/
/*函数名:void Binary_Conversion(int i) */
/*功能:十-二进制转换 */
/*说明:该函数输出二进制数为低位在前,高位在后 */
/**************************************************************************/
void Binary_Conversion(int i)
{
int j=0,temp=0;
do // 生成完整n个二进制
{
temp = i % 2; // 判断相应最低位为0或1(若为2的倍数则为0,否则为1)
i = i / 2; // 为考虑前一位为0或1做准备
if(j < m) // m确定二进制的位数
{
N[j] = temp;
j++;
}
}while(i != 0); // 等待i等于0(即等待十进制数为0时不进行二进制转换)
}
/**************************************************************************/
/*函数名:void Random_Array() */
/*功能:将数组的列随机排放 */
/**************************************************************************/
void Random_Array()
{
srand(unsigned(time(NULL))); // 随机生成条件(抵消rand函数伪随机效果)
cout << endl << "产生随机数为:" << endl;
for(int j=0;j<n;j++)
{
loop:r= rand() % n; // 随机生成范围为0~n-1的正整数
for(int i=0;i<j;i++)
{
if(R[i] == r) // 如果随机产生的数与已产生的数相等,则重新随机产生数
{
goto loop;
}
}
R[j] = r; // 产生不重复的随机数
cout << setw(4) << r + 1;
for(int i=0;i<m;i++)
{
PT_D[i][j] = PT_S[i][r]; // 顺序转置系数矩阵->随机转置系数矩阵
}
}
}
/**************************************************************************/
/*函数名:void Creat_H() */
/*功能:创建系统型奇偶校验矩阵H */
/*说明:系统型奇偶校验矩阵H由转置负系数矩阵和单位矩阵组成 */
/**************************************************************************/
void Creat_H()
{
int i,j,count0=0,count1=0,count2=0,count3=0;
/*************生成单位矩阵Ih************/ //教材P101
for(i=0;i<m;i++) //i表示行 j表示列
{
for(j=0;j<n;j++)
{
if((j >= k) && (i+k == j))
Ih[i][j] = 1;
else
Ih[i][j] = 0;
}
}
/*********生成转置负系数矩阵PT**********/
for(i=0;i<m;i++) // 转置二进制转换数组到PT_S
{
for(j=0;j<n;j++)
{
PT_S[i][j] = num[j][i]; // 生成顺序转置系数矩阵
}
}
Random_Array();//将数组的列随机排放
for(j=0;j<n;j++)
{
for(i=0;i<m;i++)
{
if(PT_D[i][j] == 0)
count0 ++;
}
count1 = count0; // count1记录每一列1的个数
count0 = 0;
if(count1 == (m-1)) // 将只有一位为1其余位为0的列的所有位置0
{
for(i=0;i<m;i++)
{
PT_D[i][j] = 0;
}
}
else
// COUNT数组记录只有一位为1其余位为0的列为0,其余位的值为PT_D列的位置值+1
COUNT[count2] = j + 1;
count2 ++;
}
for(int q=0;q<n;q++) // 将PT_D的至少有两个1的列赋给PT
{
if(COUNT[q] > 0)
{
for(i=0;i<m;i++)
PT[i][count3] = PT_D[i][q];
count3 ++;
}
}
cout << endl;
/********生成系统型奇偶校验矩阵H********/
for(i=0;i<m;i++)
{
for(j=0;j<n;j++)
{
H[i][j] = PT[i][j] + Ih[i][j];
}
}
cout << endl << "系统型奇偶校验矩阵H为:" << endl;
for(i=0;i<m;i++) // 显示系统型奇偶校验矩阵H
{
for(j=0;j<n;j++)
{
cout << setw(2) << H[i][j] << setw(2);
}
cout << endl;
}
}
/**************************************************************************/
/*函数名:void Creat_G() */
/*功能:创建系统型生成矩阵G */
/*说明:系统型生成矩阵G由单位矩阵和系数矩阵组成 */
/**************************************************************************/
void Creat_G()
{
int i,j;
/*************生成单位矩阵Ig************/
for(i=0;i<k;i++)
{
for(j=0;j<n;j++)
{
if(i == j)
Ig[i][j] = 1;
else
Ig[i][j] = 0;
}
}
/*************生成系数矩阵P*************/
for(j=0;j<n;j++)
{
for(i=0;i<k;i++)
{
if(j>k-1)
P[i][j] = PT[j-k][i];
}
}
/**********生成系统型生成矩阵G**********/
for(i=0;i<k;i++)
{
for(j=0;j<n;j++)
{
G[i][j] = P[i][j] + Ig[i][j];
}
}
cout << endl << "系统型生成矩阵G为:" << endl;
for(i=0;i<k;i++) // 显示系统型奇偶校验矩阵H
{
for(j=0;j<n;j++)
{
cout << setw(2) << G[i][j] << setw(2);
}
cout << endl;
}
}
/*******************************主函数*************************************/
int main()
{
int i,j;
cout << setw(30) << "汉明码" << endl;
cout << "请输入校验元位数m = ";
cin >> m;
n = pow(2,m) - 1; //码长
k = pow(2,m) - 1 -m; //信息源位数
cout << "提示:" << setw(10) << "您输入的为(" <<n<< "," <<k<< ")汉明码,可纠正" << t << "个错误" << endl;
cout << endl;
for(i=0;i<n;i++) // 将n个转换二进制数组存入二维数组
{
Binary_Conversion(i+1);
for(j=0;j<m;j++)
{
num[i][j] = N[j];
//num[i][m-j-1] = N[j]; // m-j-1意义在于将二进制高位在前,低位在后
}
}
cout << "n个二进制转换表为:" << endl;
for(i=0;i<n;i++) // 输出二进制转换对应表 低位在前高位在后
{
for(j=0;j<m;j++)
{
cout << num[i][j] << setw(2);
}
cout << setw(4);
}
cout << endl;
Creat_H();
Creat_G();
cout << endl << "请输入" << k << "位信息比特流:" << endl;
for(i=0;i<k;i++)
cin >> Ibit[i];
for(i=0;i<n;i++)
{
for(j=0;j<k;j++)
{
Cbit[i] += (Ibit[j] * G[j][i]); // 十进制加法
Cbit[i] = Cbit[i] % 2; // 将十进制转换二进制
}
}
cout << endl << "输出" << n << "位码字比特流:" << endl;
for(i=0;i<n;i++) //输出编码后的码字
cout << setw(3) << Cbit[i];
cout << endl;
Err_Pro(); //错误概率函数
Hamming_Decode(); //汉明译码
return 0;
}
/**************************************************************************/
/*函数名:void Err_Pro() */
/*功能:产生错误概率函数 */
/**************************************************************************/
void Err_Pro()
{
float p;
cout << endl << "请输入错误概率p = ";
cin >> p;
for(int x=0;x<n;x++)
{
if((float)((rand() % 1001) * 0.001) < p) // 如果小于概率,则原码0与1互换
{
err ++;
Err_Cbit[x] = (Cbit[x] + 1) % 2;
}
else
Err_Cbit[x] = Cbit[x]; // 如果大于错误概率,则赋值原码
}
cout << endl << "输出" << n << "位码字比特流(每位等概出错):" << endl;
for(int y=0;y<n;y++)
cout << setw(3) << Err_Cbit[y];
cout << endl;
}
/**************************************************************************/
/*函数名:void Hamming_Decode() */
/*功能:汉明译码函数 */
/**************************************************************************/
void Hamming_Decode()
{
int i,j,flag=0,d;
for(i=0;i<n;i++) // 得到H的转置矩阵HT
{
for(j=0;j<m;j++)
{
HT[i][j] = H[j][i];
}
}
cout << endl << "输出转置奇偶校验矩阵HT为:" << endl;
for(i=0;i<n;i++)
{
for(j=0;j<m;j++)
{
cout << setw(3) << HT[i][j] << setw(3);
}
cout << endl;
}
for(i=0;i<m;i++) // 计算伴随矩阵
{
for(j=0;j<n;j++)
{
V[i] += Err_Cbit[j] * HT[j][i];
}
if(V[i] % 2 == 0) // 将十进制转换二进制
V[i] = 0;
else
V[i] = 1;
}
cout << endl << "输出伴随矩阵为:" << endl;
for(i=0;i<m;i++)
cout << V[i] << setw(2);
cout << endl;
for(i=0;i<m;i++)
{
if(V[i] == 0) // 如果伴随矩阵为零矩阵,则直接输出原码流
{
if(i == m-1)
{
cout << endl << "<译码正确!>输出码流为:" << endl;
for(j=0;j<n;j++)
cout << Err_Cbit[j] << setw(3);
cout << endl;
}
}
else
{
flag ++; // 如果伴随矩阵为非零矩阵,则标志位自加1
break;
}
}
if(flag != 0)
{
if(err == 1) // 伴随矩阵为非零矩阵时执行
{
for(i=0;i<n;i++)
{
for(j=0;j<m;j++)
{
if(V[j] == HT[i][j])
{
if(j == (m-1)) d = i;//d记录行
}
else
break;
}
}
cout << endl << "<译码正确!>输出码流为:"<< endl;
Err_Cbit[d] = (Err_Cbit[d] + 1) % 2;
for(i=0;i<n;i++)
cout << setw(3) << Err_Cbit[i] << setw(3);
cout << endl;
}
else
cout << endl << "由于本次编码有" << err << "个错误位,大于纠错能力" << t << ",故<译码错误!>" << endl;
}
}
六、程序运行结果
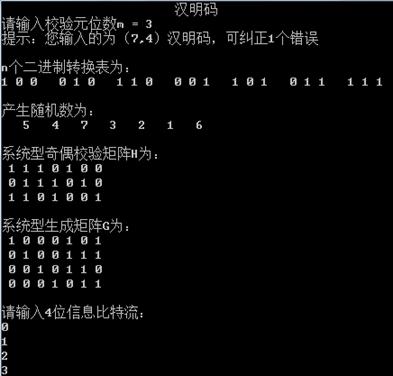

七、心得体会
经过对程序的理解和掌握,我更加清楚的掌握了汉明编码与译码的方法,这是我感觉收获最大的地方。对伴随式也有了比较深刻的理解,之后做题目和看书对这块的知识也有了更透彻的理解,掌握也更加轻松一些。
实验四 求循环码的最小汉明距离
一、实验题目
1、输入码的生成多项式;
2、输出码的最小汉明距离。
二、实验目的
1、理解和掌握循环码的概念以及生成方法;
2、求出循环码的最小距离。
三、算法设计
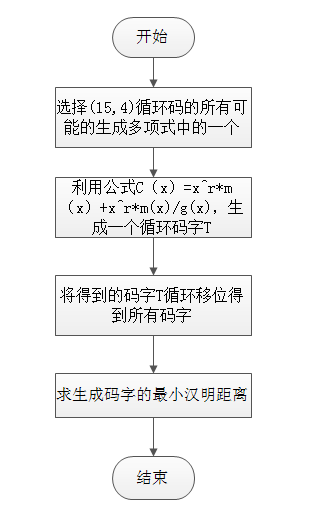
四、程序分析
1.采用Matlab编程;
2.cyclpoly(15, 4,'all')函数用来产生(15,4)循环码的所有生成多项式;
3.circshift()函数是进行移位操作函数;
4.sym2poly()函数是将多项式转化为矩阵表示形式;
5.expand(x^r*m)函数是对m进行左移r位的操作;
五、程序代码
syms x ;
G=cyclpoly(15, 4,'all');%求出所有的生成多项式 功能:产生循环码的生成多项式
g=G(2,:);%选择所有生成多项式中的第二个作为(15,4)循环码的生成多项式
r=15-4 ; %监督位数
m=x^3+x^2+1; %信息码元
m1=expand(x^r*m); %用x^r乘以m,相当于对m进行左移r位的操作
m2=sym2poly(m1); %将多项式转化为矩阵表示形式
[Q,R] = DECONV(m2,g); %求m2除以g所得的余数
%由于在求解余数时是按照一般的算术运算计算的,
%而实际要求的为模2运算,转化为模2运算
R=abs(R);
for i=1:length(R)
R(i)=mod( R(i),2);
end
%C(X)=x^r*m(x)+x^r*m(x)/g(x)
T=R+m2 ;%T为生成的一个循环码字
T2(1,:)=T;
[W,L]=size(T);
%将T2循环移位,得到其他的码字
for i=1:L-1
T2(i+1,:)=circshift(T2(i,:),[0,1]);
end
Y=[zeros(1,L);T2]; %Y矩阵为生成的全部码字
%求最小汉明距离
t=1;
for i=1:15
for j=i+1:16
M(t,:)=(Y(i,:)~=Y(j,:));
t=t+1;
end
end %分别比较两行中不同的元素
S=(sum(M,2))'; %将M矩阵的每一行求和,得出任意两个码字之间的距离
d=min(S); %最小汉明距离
display(d);
六、程序运行结果
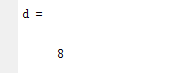
七、心得体会
刚刚接触Matlab不久,对于Matlab里的函数不是十分了解,在解读程序时需要将函数一个个打开,解读它的注释,了解函数的算法;经过对程序细致的解读,不但对求循环码的最小汉明距离有了更深的了解,对Matlab的软件也有了更多的掌握,可谓收获颇丰。只是可惜的是自己的编程能力不好,时间不允许我慢慢磨蹭着自己写程序,所以只好看成熟的程序,看会了、了解了,这些知识也是我的。
实验五 维特比译码
一、实验题目
写一个维特比译码器软件,它接受下列输入:
1、以八进制形式给出的码的参数,以及
2、接收到的比特流。
二、实验目的
1、理解和掌握卷积码的概念;
2、掌握维特比译码的方法;
三、算法设计

四、程序分析
min_dist(a,b)函数计算两个码字的汉明重量;
num_jinzhi(num,jinzhi,wei)函数将十进制的 num转换为进制为jinzhi的wei位数;
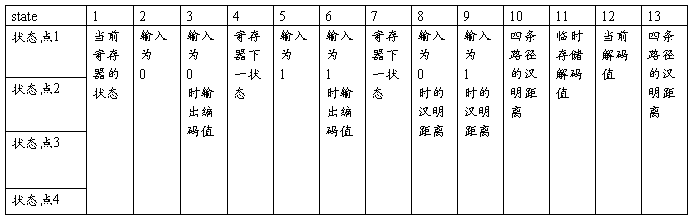
init_state()函数是对state[ ]
矩阵进行初始化操作;
G矩阵存储码的参数的二进制形式;
xinxi[ ]矩阵存储输入比特流;
state[ ]矩阵存储如下表的状态;
五、程序代码
主函数:
display('编码序列:');
xinxi=[1 0 1 0 0 1 1 0 1]
% in=0;
input_g= '75';
str_length=length(input_g);
%-----------将输入的char型数字转换成二进制数------------------------%
for i=1:str_length
g_dec=base2dec(input_g,8);%将'75'这个8进制数转换成10进制
g=num_jinzhi(g_dec,2,3*str_length);%将10进制数转换成2进制
end
g; %测试g
global G;
for i=1:str_length
G_yuanshi(i,1:3)=g(3*i-2:3*i);%将得到的二进制数 每三个分成一行
end
G=G_yuanshi';
% ------------------------生成查询表格-----------------------------%
state=init_state;
% ---------------------以下为编码算法------------------------------ %
xinxi_bu0=[xinxi 0 0];
xinxi_length=length(xinxi_bu0); %这里的长度实际为补0后的长度
state_temp=[0 0]; %初始的状态寄存器里面为00
for i=1:xinxi_length
for j=1:4 %对应四种状态
if isequal(state_temp,state{j,1})
if xinxi_bu0(i)==0 %若输入为0
code(2*i-1:2*i)=state{j,3};%输出码字
state_temp=state{j,4}; %下一状态
else if xinxi_bu0(i)==1 %若输入为1
code(2*i-1:2*i)=state{j,6};%输出码字
state_temp=state{j,7}; %下一状态
end
end
break;
end
end
end
display('信息编码如下:');
code
%---------------加入错误编码 (这里仅将第三位出错)---------------------- %
code(3)=~code(3);
display('出错后的编码:');
code
%---------------------以下为解码算法--------------------------------- %
code_length=length(code); %这里的长度实际为补0后的长度
state_temp=[0 0]; %初始的状态寄存器里面为00
%计算最初始两个码字 四条路径的汉明距离
state{1,10}=min_dist(state{1,3},[code(1) code(2)])+min_dist(state{1,3},[code(3) code(4)]);%第一条路径的汉明距离
state{2,10}=min_dist(state{1,3},[code(1) code(2)])+min_dist(state{1,6},[code(3) code(4)]);%第二条路径的汉明距离
state{3,10}=min_dist(state{1,6},[code(1) code(2)])+min_dist(state{2,3},[code(3) code(4)]);%第三条路径的汉明距离
state{4,10}=min_dist(state{1,6},[code(1) code(2)])+min_dist(state{2,6},[code(3) code(4)]);%第四条路径的汉明距离
state{1,11}=[0 0];%存放第一条路径的前两个码字
state{2,11}=[0 1];%存放第二条路径的前两个码字
state{3,11}=[1 0];%存放第三条路径的前两个码字
state{4,11}=[1 1];%存放第四条路径的前两个码字
for i=1:4
state{i,12}=state{i,11};
end
% for i=3:code_length/2;
i=3;
while i<=code_length/2
temp=[code(2*i-1) code(2*i)]; %下一个码字(2位)
%------------四种状态分别输入0/1后得到八种状态,每种可能的距离-----------%
for j=1:4
state{j,8}=min_dist(temp,state{j,3});%输入0的可能最小距离
state{j,9}=min_dist(temp,state{j,6});%输入1的可能最小距离
end
%--------------------------每种状态所对应的下一编码---------------------%
if (state{1,8}+state{1,10})<(state{3,8}+state{3,10}) %第一个状态点的路径选取
state{1,12}=[state{1,11} 0];%获得下一个解码
else state{1,12}=[state{3,11} 0];
end
if (state{1,9}+state{1,10})<(state{3,9}+state{3,10})%第二个状态点的路径选取
state{2,12}=[state{1,11} 1];
else state{2,12}=[state{3,11} 1];
end
if (state{2,8}+state{2,10})<(state{4,8}+state{4,10})%第三个状态点的路径选取
state{3,12}=[state{2,11} 0];
else state{3,12}=[state{4,11} 0];
end
if (state{2,9}+state{2,10})<(state{4,9}+state{4,10})%第四个状态点的路径选取
state{4,12}=[state{2,11} 1];
else state{4,12}=[state{4,11} 1];
end
%-------------state{:,13}用来临时存放每条路径的汉明重---------------%
state{1,13}=min((state{1,8}+state{1,10}),(state{3,8}+state{3,10}));%第一个状态点在取汉明重量较小的那条路径
state{2,13}=min((state{1,9}+state{1,10}),(state{3,9}+state{3,10}));%第二个状态点在取汉明重量较小的那条路径
state{3,13}=min((state{2,8}+state{2,10}),(state{4,8}+state{4,10}));%第三个状态点在取汉明重量较小的那条路径
state{4,13}=min((state{2,9}+state{2,10}),(state{4,9}+state{4,10}));%第四个状态点在取汉明重量较小的那条路径
i=i+1;
for j=1:4
state{j,10}=state{j,13};%更新state{:,10}
state{j,11}=state{j,12};%更新state{:,11}
end
end
%-----------------------判断四组码中的最小距---------------------------%
dis_temp=[state{1,10} state{2,10} state{3,10} state{4,10}];
index=find(min(dis_temp) == dis_temp);
if length(index)>1 %有多条最小路径时的处理方式
index=index(1);
end
decode_length=length(state{index,12});
display('解码如下:')
decode=state{index,12}(1:decode_length-2) %%去掉最后面的两个0
%-------------------测试解码和原码是否完全相同------------------------%
for i=1:decode_length-2
test(i)=decode(i) - xinxi(i);
end
display('检测解码是否正确码字如下'); test
子函数:
%----------------将十进制的 num转换为进制为jinzhi的wei位数--------------%
function out=num_jinzhi(num,jinzhi,wei)
% yushu=zeros(1,wei);%为了提高计算速度,提前申请输出数据的内存
i=1;
shang_pre=num;
shang_back=num;
while shang_back>=jinzhi
yushu(i)=mod(shang_pre,jinzhi);%将10进制数变成二进制数
i=i+1;
shang_back=fix(shang_pre/jinzhi);
shang_pre=shang_back;
end
yushu(i)=shang_back;
for i=1:wei
out_yushu(i)=yushu(wei-i+1);%将转换后的结果调整 高位在前,低位在后
end
out=out_yushu;
function out=init_state()
global G;
state=cell(4,7); %创建4*7的数组 可以存储不同类型的数据
state(:)={[0]};
state{1,1}=[0 0];%见教材P164 生成初始状态
state{2,1}=[1 0];
state{3,1}=[0 1];
state{4,1}=[1 1];
for i=1:4
state{i,2}=0;
in=0;
% % % 输入0
temp=[in state{i,1}];
state{i,3}=mod(temp*G,2); %输出值
state{i,4}=[in state{i,1}(1)];%下一状态
% % % 输入1
in=1;
state{i,5}=1;
temp=[in state{i,1}];
state{i,6}=mod(temp*G,2); %输出值
state{i,7}=[in state{i,1}(1)];%下一状态
end
out=state;
%--------------------------求两个码字的汉明重量------------------------%
function out=min_dist(a,b)
min_length=length(a);
cnt=0;
for i=1:min_length
if a(i)~=b(i);
cnt=cnt+1;
end
end
out=cnt;
六、程序运行结果

七、心得体会
维特比译码在学习上比较轻松,理解起来也比较容易,但程序的编写就比较复杂一点,再加上用Matlab编程,对我而言难度就增加了;但是将主要流程理解清楚后,搞懂主要变量的变化之后,程序也就变得清晰了;理解了这个程序,让我对Matlab编程的掌握进一步加深了,希望以后能够自己独立编写程序。