Mysql学习总结
一、 mysql数据库安装
1、 安装前的准备
Mysql安装文件包
2、 安装步骤
首先,解压 mysql-4.0.23-win-noinstall.zip 至c:\, 并将目录名改为 c:\mysql
然后,修改系统环境变量;在控制面板->系统->高级->环境变量->系统变量->Path, 编辑, 添加 ;c:\mysql\bin(注意前面的分号 C:为mysql安装盘符,如果mysql解压到D盘则为;d:\mysql\bin)
最后,进入命令行, 输入:
cd c:\mysql\bin 回车 (进入到mysql安装目录下)
mysqld-nt --install 回车 (安装数据库服务器)
3、 启动mysql服务
方法1;在命令行键入:net start mysql 回车
方法2:控制面板——管理工具——服务(在右边找到mysql服务,双击选择自动,然后启用服务)
方法3:运行 winmysqladmin.exe程序, 待c:\winnt目录中产生了my.ini文件后, 退出, 然后再重新启动一次服务.
二、 往数据库里装入数据
1、把update解压到mysql\bin,运行install.bat,site_base.bat,
2、进入mysql查询表结构是否正常
三、 mysql常用命令
1、登陆数据库
>mysql –h [主机ip] –u [用户名] –p[密码] 回车
例如:mysql –h localhost –u root –p
使用超管用户登陆,回车之后会让输入密码(初始为空)直接回车即可。
2、使用数据库
Mysql>use 数据库名;
注意别忘记最后的分号,在mysql里句语一般都以分号结束。
3、使用SHOW语句找出在服务器上当前存在什么数据库:
mysql> SHOW DATABASES;
4、 创建一个数据库
Mysql>create database 数据库名;
5、 查看数据库中存在的表
Mysql>show tables;
6、 显示表结构
Mysql>desc 表名;
7、 往表中加入记录
Mysql>insert into 表名 values (‘hyq’,’m’);
8、 查询表中数据
Mysql>select 字段1,字段2,…… from 表名 where 条件;
例如:要查询略阳站区的id,
Mysql>select site_id from site_base where site_name=”略阳站”;
注:site_id也可用*号代替,在mysql语句中*号表示全部匹配。另外工区名后别忘记有一个“站”字。
9、 修改表中的数据
Mysql>update 表名 set 字段=“修改后的值” where 指定条件;
10、删除表中的记录
Mysql>delete from 表名 where 限制条件;
四、 数据库备份与恢复
1、 把数据表中的数据导出成文本格式
Mysql>select * from 表名 into oufile “文件名”;
2、 把导出的文本文件导入到数据表中
Mysql>load data local infile “文件路径” into table 表名 (字段1,字段2,……);
例如:mysql>load data local infile “D:/base.txt” into site_base (site_id,site_name,qj,pws_name,lj_name,line_name,telno,install_date,seq,dev_id,server_ip);
3、导出数据库
进入到mysql目录下的bin文件夹;cd mysql中到bin文件夹的目录
如:cd c:\mysql\bin
然后导出数据库:mysqldump –u 用户名 –p 数据库名 > 导出文件名
如:mysqldump –u root –p raindb > rain.sql (输入后会让你输入进入数据库的密码)
如果导出单张表的话,在数据库名后面输入表名即可。
会看到文件rain.sql会在bin 文件夹下生成。
4、导入sql文件到数据库
连接到你要导入的数据库服务器
Mysql –u root –p
输入密码
Mysql>use 数据库名; 选择数据库
Mysql>source 导入文件名; 导入文件
五、 用户权管理
1、 新建用户
Mysql>grant 用户权限1,用户权限2…… on 数据库 to 用户名@主机名 identified by “密码”;
权限可以用all表示所有权限,数据库可以用*.*表示所用数据库,主机名用%号表示所有主机。若要给此用户赋予他在相应对象上的权限的管理能力,可在GRANT后面添加WITH GRANT OPTION选项
全局管理权限:
FILE: 在MySQL服务器上读写文件。
PROCESS: 显示或杀死属于其它用户的服务线程。
RELOAD: 重载访问控制表,刷新日志等。
SHUTDOWN: 关闭MySQL服务。
数据库/数据表/数据列权限:
ALTER: 修改已存在的数据表(例如增加/删除列)和索引。
CREATE: 建立新的数据库或数据表。
DELETE: 删除表的记录。
DROP: 删除数据表或数据库。
INDEX: 建立或删除索引。
INSERT: 增加表的记录。
SELECT: 显示/搜索表的记录。
UPDATE: 修改表中已存在的记录。
特别的权限:
ALL: 允许做任何事(和root一样)。
USAGE: 只允许登录–其它什么也不允许做。
六、 常用的一些查询语句收集
1、 显示数据库版本
Mysql>select now();
2、 显示当前用户
Mysql>select user();
3、 显示所有用户
Mysql>select host,user,password from mysql.user;
七、 Mysql同步功能的实现
Posted 2012 年 5 月 25 日 by 刘 强
目前西局所有站区雨量数据都上传至路局Mysql数据库,各工务段通过Mysql主从备份实现数据同步。
简单的说,有两台服务器A和B,使A为主服务器,B为从服务器,初始状态时,A和B中的数据信息相同,当A中的数据发生变化时,B也跟着发生相应的变化,使得A和B的数据信息同步,达到备份的目的。
原理是负责在主、从服务器传输各种修改动作的媒介是主服务器的二进制变更日志,这个日志记载着需要传输给从服务器的各种数据库修改动作。因此,主服务器必须激活二进制日志功能。从服务器必须具备足以让它连接主服务器并请求主服务器把二进制变更日志传输给它的权限。
搭建案例:
西安铁路局(以下简称为A)、延安工务段(以下简称为B)的MySQL数据库版本同为4.0.23
A:master (主机)
操作系统:Windows 2003
IP地址:10.106.4.129
B:slave (从机)
操作系统:Windows 2003 server
的IP地址:10.110.33.10
配置过程:
1、在A的数据库中建立一个备份帐户,命令如下:
GRANT REPLICATION SLAVE,RELOAD,SUPER ON *.* TO yasync@’10.110.33.10’ IDENTIFIED BY ‘yasync’;
建立一个帐户yasync,并且只能允许从10.110.33.10这个地址上来登陆,密码是yasync
2、关停A服务器,将A中的数据拷贝到B服务器中,使得A和B中的数据同步,并且确保在全部设置操作结束前,禁止在A和B服务器中进行写操作,使得两数据库中的数据初始一致!
3、对A服务器的配置进行修改,打开mysql/my.ini文件,在[mysqld]下面添加如下内容:
server-id=1
log-bin=c:\log-bin.log
server-id:为主服务器A的ID值
log-bin:二进制变更日志,这个文件记录着数据库修改操作
4、重启A服务器,从现在起,它将把有关数据库的修改记载到二进制变更日志里去。
5、关停B服务器,对B服务器配置,以便让它知道自己的镜像ID、到哪里去找主服务器以及如何去连接服务器。最简单的情况是主、从服务器分别运行在不同的主机上并都使用着默认的TCP/IP端口,只要在从服务器启动时去读取的mysql/my.ini文件里添加以下几行指令就行了。
[mysqld]
server-id=2
master-host=10.106.4.129
master-user=yasync
master-password=yasync
slave-skip-errors=all
//以下内容为可选
replicate-do-db=backup
说明
server-id:从服务器B的ID值。注意不能和主服务器的ID值相同。
master-host:主服务器的IP地址。
master-user:从服务器连接主服务器的帐号。
master-password:从服务器连接主服务器的帐号密码。
eplicate-do-db:告诉主服务器只对指定的数据库进行同步镜像。
slave-skip-errors 忽略错误,避免mysql同步停止
6、重启从服务器B。至此所有设置全部完成。更新A中的数据,B中也会立刻进行同步更新。如果从服务器没有进行同步更新,你可以通过查看从服务器中的mysql_error.log日志文件进行排错。
7、查看日志一些命令
1, show master status;
在这里主要是看log-bin的文件是否相同。
show slave status;
在这里主要是看:
Slave_IO_Running=Yes
Slave_SQL_Running=Yes
如果都是Yes,则说明配置成功.
2,在master上输入show processlist;
mysql> SHOW PROCESSLIST
*************************** 1. row ***************************
Id: 2
User: root
Host: localhost:32931
db: NULL
Command: Binlog Dump
Time: 94
State: Has sent all binlog to slave; waiting for binlog to
be updated
Info: NULL
如果出现Command: Binlog Dump,则说明配置成功.
几个跟同步有关的mysql命令:(需要在mysql命令行界面运行)
stop slave #停止同步
start slave #开始同步,从日志终止的位置开始更新。
SET SQL_LOG_BIN=0|1 #主机端运行,需要super权限,用来开停日志,随意开停,会造成主机从机数据不一致,造成错误
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=n # 客户端运行,用来跳过几个事件,只有当同步进程出现错误而停止的时候才可以执行。
RESET SLAVE #从机运行,清除日志同步位置标志,并重新生成master.info
虽然重新生成了master.info,但是并不起用,必须将从机的mysql服务重启一下,
LOAD TABLE tblname FROM MASTER #从机运行,从主机端重读指定的表的数据,每次只能读取一个,受timeout时间限制,需要调整timeout时间。执行这个命令需要同步账号有 reload和super权限。以及对相应的库有select权限。如果表比较大,要增加net_read_timeout 和 net_write_timeout的值
LOAD DATA FROM MASTER #从机执行,从主机端重新读入所有的数据。执行这个命令需要同步账号有reload和super权限。以及对相应的库有select权限。如果表比较大,要增加net_read_timeout 和 net_write_timeout的值
第二篇:MySQL Cluster 概念 学习总结
Mysql Cluster 概念学习汇总
关于 mysql HA(谭俊青 - MySQL数据库集群高可用设计及应用) MySQL HA Solution
●MySQL + Shared-Storage
●MySQL + DRBD (CP)
●Master + Slave (AP)
●Master + Slave(SemiSyncReplication) (CP/AP)
●Multi-Master (AP)
●MySQL Cluster (CAP? CP/AP)
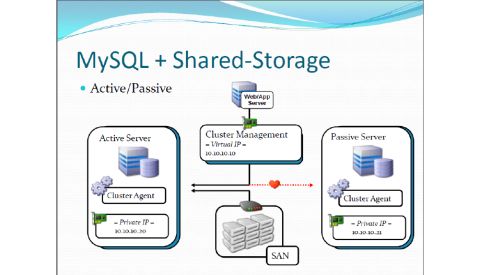
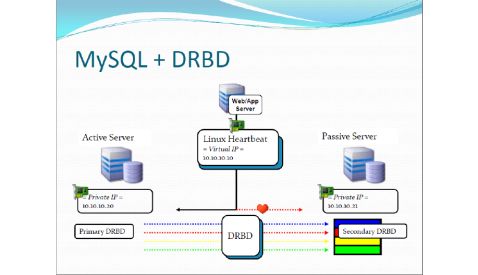
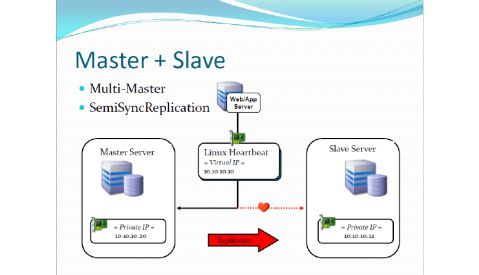
MySQL Cluster 概念(官方)
MySQL Cluster is a technology that enables clustering of in-memory databases in a shared-nothing system. The shared-nothing architecture enables the system to work with very inexpensive hardware, and with a minimum of specific requirements for hardware or software.
MySQL Cluster is designed not to have any single point of failure. In a shared-nothing system, each component is expected to have its own memory and disk, and the use of shared storage
mechanisms such as network shares, network file systems, and SANs is not recommended or supported.
Mysql cluster 是一种在无共享环境中具有内存数据库性质的集群技术。这种无共享架构使得系统能在不昂贵的设备上运行,对于软件和硬件的特定需求也是最小的。MySQL Cluster 设计避免了单点失败。 在一个无共享的环境里, 每个成员都会用友他们自己的内存和硬盘。共享磁盘机制诸如 网络分享,NFS,和SAN 是不推荐和不支持的。
MySQL Cluster integrates the standard MySQL server with an in-memory clustered storage engine called NDB(which stands for “Network DataBase”). In our documentation, the term NDB refers to the part of the setup that is specific to the storage engine, whereas “MySQL Cluster” refers to the combination of one or more MySQL servers with the NDB storage engine.
Mysql 进群 集成了标准的mysql 服务器。在这里,mysql server基于了一种内存集群存储引擎,叫做NDB(它是 Network DataBase 的缩写)。在我们的文献中,NDB特别指代存储引擎,而Mysql Cluster 指代的基于ndb引擎的数据服务器的组合
A MySQL Cluster consists of a set of computers, known as hosts, each running one or more processes. These processes, known as nodes, may include MySQL servers (for access to NDB data), data nodes (for storage of the data), one or more management servers, and possibly other specialized data access programs. The relationship of these components in a MySQL Cluster is shown here:
一个 mysql cluster 集群 由一套电脑构成,叫做 主机。每个主机跑一个或多个进程。这些进程,叫做结点。 这些结点也许包含着 mysql 服务器(获取NDB数据),数据结点(存储数据),一个或多个管理服务器和一些可能的其他特定数据获取程序。这些成员的关系在mysql 集群如图所示
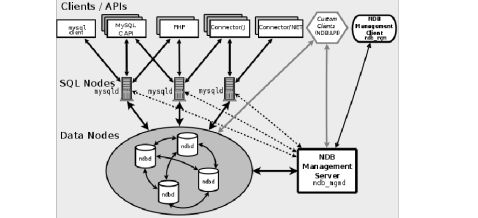
All these programs work together to form a MySQL Cluster (see . When data is stored by the NDB storage engine, the tables (and table data) are stored in the data nodes. Such tables are directly accessible from all other MySQL servers (SQL nodes) in the cluster. Thus, in a payroll application storing data in a cluster, if one application updates the salary of an employee, all other MySQL servers that query this data can see this change immediately. Although a MySQL Cluster SQL node uses the server daemon, it differs in a number of critical respects from the binary supplied with the MySQL 5.6 distributions, and the two versions of are not interchangeable.
所有的程序工作在一起构成了mysql cluster. 当数据被储存在NDB引擎中时,表和它的数据被储存在数据结点。这样 表能够直接被其他在集群中的mysql 服务器获取到。因此,在一个储存数据在集群的交费应用中,如果一个应用更新了一个职员的工资,所有其他mysql 服务器能马上看到这条数据的变化。尽管一个mysql cluster 的sql节点使用了mysqld 的服务器守护集成。但它还是与mysql 5.6 发布的2进制 mysqld 程序有很多关键的不同。因此,这两个不可互换的。
In addition, a MySQL server that is not connected to a MySQL Cluster cannot use the NDB storage engine and cannot access any MySQL Cluster data.
除此之外,一个没有连接到mysql cluster 的mysql 服务器是不能用ndb存储引擎 也不能获取mysql cluster的数据
The data stored in the data nodes for MySQL Cluster can be mirrored; the cluster can handle failures of individual data nodes with no other impact than that a small number of transactions are aborted due to losing the transaction state. Because transactional applications are expected to handle transaction failure, this should not be a source of problems.
为MySQL Cluster存放数据的数据节点的数据是可以被镜像的。集群能够处理个别数据节点的失败而没有其他影响除了少量的会话被放弃了因为失去了会话状态。这是因为会话应用 是被用来控制会话失败的。数据库集群不是问题的源泉。
Individual nodes can be stopped and restarted, and can then rejoin the system (cluster). Rolling restarts (in which all nodes are restarted in turn) are used in making configuration changes and software upgrades (see ). Rolling restarts are also used as part of the process of adding new data nodes online (see ). For more information about data nodes, how they are organized in a MySQL Cluster, and how they handle and store MySQL Cluster data,
see .
Backing up and restoring MySQL Cluster databases can be done using the NDB-native functionality found in the MySQL Cluster management client and the program included in the MySQL Cluster distribution. For more information, see , and . You can also use the standard MySQL functionality provided for this purpose in and the MySQL server. See , for more information. MySQL Cluster nodes can use a number of different transport mechanisms for inter-node
communications, including TCP/IP using standard 100 Mbps or faster Ethernet hardware. It is also possible to use the high-speed Scalable Coherent Interface (SCI) protocol with MySQL Cluster, although this is not required to use MySQL Cluster. SCI requires special hardware and software; see , for more about SCI and using it with MySQL Cluster.
个别节点能够被停止和重启,然后重新联入系统。滚动重启被用来变更配置文件和软件更新。滚动重启也被用来在线添加新的数据节点。通过mysql cluster 基于ndb的管理客户端或ndb_restore 实现备份恢复。当然您也可以使用 标准mysql的msyqldump 来完成这一目的。Mysql cluster 节点之间可以使用不同的协议。它门包含了tcpip,快速以太网以及SCI(Scalable Coherent Interface)
MySQL Cluster Core Concepts
核心概念:
Management node: The role of this type of node is to manage the other nodes within the MySQL Cluster, performing such functions as providing configuration data, starting and stopping nodes,
running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd.
管理节点: 主要用来管理集群和其它节点的,还有备份集群等功能,每次得先启动 管理节点再启动其它,它是用ndb_mgmd启动的
Data node: This type of node stores cluster data. There are as many data nodes as there are
replicas, times the number of fragments (see Section 17.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”). For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to have 2 (or more) replicas to provide redundancy, and thus high availability. A data node is started with the command ndbd (see Section 17.4.1, “ndbd — The MySQL Cluster Data Node Daemon”). In MySQL Cluster NDB 7.0 and later, ndbmtd can also be used for the data node process; see Section 17.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”, for more information.
MySQL Cluster tables are normally stored completely in memory rather than on disk (this is why we refer to MySQL Cluster as an in-memory database). In MySQL 5.1, MySQL Cluster NDB 6.X, and later, some MySQL Cluster data can be stored on disk; see Section 17.5.12, “MySQL Cluster Disk Data Tables”, for more information.
数据节点: 这种节点储存数据。有多少数据节点,就有多少复制进程乘以分段量。举个例子,两个复制进程,每个有两段,那么你就要有4个数据节点。我们的复制进程对于存储数据是充足的,但它不提供冗余。所以我们建议2个或者更多的复制进程来达到高可用。数据节点是通过ndbd启动的。7.0后ndbmtd也可以用来管理了。
通常来说 mysql cluster 通常把表完整存在内存里相比于硬盘(这就是为什么它被成为内存数据库)在之前的版本里,mysql cluster 还是能把数据存在硬盘里的。
SQL node: This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the NDBCLUSTER storage engine. An SQL node is a mysqld process started with the --ndbcluster and --ndb-connectstring options, which are explained elsewhere in this chapter, possibly with additional MySQL server options as well.
An SQL node is actually just a specialized type of API node, which designates any application which accesses MySQL Cluster data. Another example of an API node is the ndb_restore utility that is used to restore a cluster backup. It is possible to write such applications using the NDB API. For basic information about the NDB API, see Getting Started with the NDB API.
Sql 节点: 这个节点是用来获取集群数据的。在mysql cluster 这个案例了,sql结点 是一个配有ndb集群存储引擎的传统 msyql 服务器。一个sql节点就是一个mysqld的启动进程 并配以 the --ndbcluster --ndb-connectstring 选项。
一个 sql 节点 事实上就是一个特别指定类型的api 节点。它指派应用 获取集群数据。另一个api节点的例子就是ndb_restore来实现集群备份。
Important(重要)
It is not realistic to expect to employ a three-node setup in a production environment. Such a
configuration provides no redundancy; to benefit from MySQL Cluster's high-availability features, you must use multiple data and SQL nodes. The use of multiple management nodes is also highly recommended.
部署三个节点是不现实的,没有冗余度。推荐多个数据及sql节点。多个管理节点也是推荐的。
For a brief introduction to the relationships between nodes, node groups, replicas, and partitions in MySQL Cluster, see Section 17.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”.
对于简单介绍nodes, node groups, replicas, and partitions in MySQL Cluster的关系,请看17.1.2
Configuration of a cluster involves configuring each individual node in the cluster and setting up individual communication links between nodes. MySQL Cluster is currently designed with the
intention that data nodes are homogeneous in terms of processor power, memory space, and
bandwidth. In addition, to provide a single point of configuration, all configuration data for the cluster as a whole is located in one configuration file.
集群的配置包含了和每个节点的配置和他们之间通讯的配置。Mysql cluster 现在设计一个目的,那就是数据节点的同构性。无论从处理器,内存以及带宽。除此之外,为了提供一个单点的配置,所有的配置数据作为一个整体放在一个配置文件中。
The management server manages the cluster configuration file and the cluster log. Each node in the cluster retrieves the configuration data from the management server, and so requires a way to
determine where the management server resides. When interesting events occur in the data nodes, the nodes transfer information about these events to the management server, which then writes the information to the cluster log.
管理节点服务器管理着集群配置文件盒集群日志。每个节点接受配置文件从这个管理服务器中而需要一种方式确认管理节点的存在。当一些事件在数据节点发生时。数据节点把信息发给管理节点。然后写到集群日志中
In addition, there can be any number of cluster client processes or applications. These include
standard MySQL clients, NDB-specific API programs, and management clients. These are described in the next few paragraphs.
除此之外,还有一些其他的客户端进程和应用。这包含了标准的mysql 客户端,ndb api 程序 和管理客户端
Standard MySQL clients. MySQL Cluster can be used with existing MySQL applications written in PHP, Perl, C, C++, Java, Python, Ruby, and so on. Such client applications send SQL statements to and receive responses from MySQL servers acting as MySQL Cluster SQL nodes in much the same way that they interact with standalone MySQL servers.
mysql客户端
MySQL clients using a MySQL Cluster as a data source can be modified to take advantage of the ability to connect with multiple MySQL servers to achieve load balancing and failover. For example, Java clients using Connector/J 5.0.6 and later can use jdbc:mysql:loadbalance:// URLs (improved in
Connector/J 5.1.7) to achieve load balancing transparently; for more information about using Connector/J with MySQL Cluster, see Using Connector/J with MySQL Cluster.
NDB client programs. Client programs can be written that access MySQL Cluster data directly from the NDBCLUSTER storage engine, bypassing any MySQL Servers that may connected to the cluster, using the NDB API, a high-level C++ API. Such applications may be useful for specialized purposes where an SQL interface to the data is not needed. For more information, see The NDB API.
NDB 客户端程序
Beginning with MySQL Cluster NDB 7.1, NDB-specific Java applications can also be written for MySQL Cluster, using the MySQL Cluster Connector for Java. This MySQL Cluster Connector includes ClusterJ, a high-level database API similar to object-relational mapping persistence frameworks such as Hibernate and JPA that connect directly to NDBCLUSTER, and so does not require access to a MySQL Server. Support is also provided in MySQL Cluster NDB 7.1 and later for ClusterJPA, an OpenJPA implementation for MySQL Cluster that leverages the strengths of ClusterJ and JDBC; ID lookups and other fast operations are performed using ClusterJ (bypassing the
MySQL Server), while more complex queries that can benefit from MySQL's query optimizer are sent through the MySQL Server, using JDBC. See Java and MySQL Cluster, and The ClusterJ API and Data Object Model, for more information.
Management clients. These clients connect to the management server and provide commands for starting and stopping nodes gracefully, starting and stopping message tracing (debug versions only), showing node versions and status, starting and stopping backups, and so on. An example of this type of program is the ndb_mgm management client supplied with MySQL Cluster (see Section 17.4.5, “ndb_mgm — The MySQL Cluster Management Client”). Such applications can be written using the MGM API, a C-language API that communicates directly with one or more MySQL Cluster management servers. For more information, see The MGM API.
管理客户端
Oracle also makes available MySQL Cluster Manager, which provides an advanced command-line interface simplifying many complex MySQL Cluster management tasks, such restarting a MySQL
Cluster with a large number of nodes. The MySQL Cluster Manager client also supports commands for getting and setting the values of most node configuration parameters as well as mysqld server options and variables relating to MySQL Cluster. See MySQL™ Cluster Manager 1.3.0 User Manual, for more information.
Event logs. MySQL Cluster logs events by category (startup, shutdown, errors, checkpoints, and so on), priority, and severity. A complete listing of all reportable events may be found in Section 17.5.6, “Event Reports Generated in MySQL Cluster”. Event logs are of the two types listed here: 事件日志: 开关机,检查点,报错等等,记录所有事件日志
Cluster log: Keeps a record of all desired reportable events for the cluster as a whole.
集群日志:保留所有对于集群整体想要的报告事件
Node log: A separate log which is also kept for each individual node.
节点日志:一个单独的日志 保留在每个节点。
Note
Under normal circumstances, it is necessary and sufficient to keep and examine only the cluster log. The node logs need be consulted only for application development and debugging purposes.
Checkpoint. Generally speaking, when data is saved to disk, it is said that a checkpoint has been reached. More specific to MySQL Cluster, a checkpoint is a point in time where all committed transactions are stored on disk. With regard to the NDB storage engine, there are two types of
checkpoints which work together to ensure that a consistent view of the cluster's data is maintained. These are shown in the following list:
检查点: 同常来说,数据写到硬盘,检查点也是写到了。对于mysql cluster 来说,一个检查点意味着所有提交的数据都已写到了磁盘上。集群由两种检查点组成协同工作。
Local Checkpoint (LCP): This is a checkpoint that is specific to a single node; however, LCPs take place for all nodes in the cluster more or less concurrently. An LCP involves saving all of a node's data to disk, and so usually occurs every few minutes. The precise interval varies, and depends upon the amount of data stored by the node, the level of cluster activity, and other factors.
本地检查点:对于单一节点的检查点。与写数据到本节点磁盘有关,没几分钟刷一次。精确的时间间隔要看数据量和其他因素
Global Checkpoint (GCP): A GCP occurs every few seconds, when transactions for all nodes are synchronized and the redo-log is flushed to disk.
全局检查点。没几秒刷一次。所有节点的所有回话都被同步,重做日志文件写到磁盘上。
MySQL Cluster 架构(摘自博客)
Cluster分为SQL节点、数据节点、管理节点(MySQL Cluster提供了API供内部调用,外部应用程序可以通过API借口访问任意层方法)
SQL节点提供用户SQL指令请求,解析、连接管理,query优化和响、cache管理等、数据merge、sort,裁剪等功能,当SQL节点启动时,将向管理节点同步架构信息,用以数据查询路由
数据节点提供数据存取,持久化、API数据存取访问等功能
管理节点维护着节点活动信息,以及实施数据的备份和恢复等。管理节点会获取整个cluster环境中节点的状态和错误信息,并将各个cluster集群中各个节点的信息反馈给整个集群中其他的所有节点,这对于SQL节点的数据路由规则至关重要,当节扩容时,数据将会被rebuild
数据节点使用分片及多份数据存储,至少存放2份,数据存放于内存中,根据管理节点的规则进行持久化,作为数据存取地,需要大量内存支持
SQL节点作为查询入口,需要消耗大量cpu及内存资源,可使用分布式管理节点,并在SQL节点外封装一层请求分发及HA控制机制可解决单点及性能问题,其提供了线性扩展功能
管理节点维护着全局规则信息,当节点发生故障时,将会发生故障通告
在整个Cluster体系中,任何一个组建都支持动态扩展,线性扩展,提供了高可用,高性能的解决方案
问题:
当新增数据节点时,需要重构存取路径信息,对管理节点将造成数据重构压力,该操作建议在非业务高峰时进行
Cluster使用自动键值识别数据分片方案,用户无需关心数据切片方案(在5.1及以后提供了分区键规则),透明实现分布式数据库,数据分片规则根据1、主键、2唯一索引、3自动行标识rowid完成,再集群个数进行分布,其访问数据犹如RAID访问机制一样,能并行从各个节点抽取数据,散列数据,当使用非主键或分区键访问时,将导致所有簇节点扫描,影响性能(这是Cluster面对的核心挑战)