Chapter 基本概念
显著性检验(test of significance):计算P值
医学统计工作的内容:
1、实验设计:最关键最重要
2、收集资料:最基础
原始资料:实验数据
现场调查资料
医疗卫生工作记录
报表
报告卡
质量控制——精度和偏倚
3、整理资料
(1) 资料的逻辑检查(坏数)
(2) 一致性检查
(3) 原始数据加工:频数分布表
4、分析资料:统计描述(表、图、离散趋势、集中趋势)和统计推断
统计描述类型的选择:
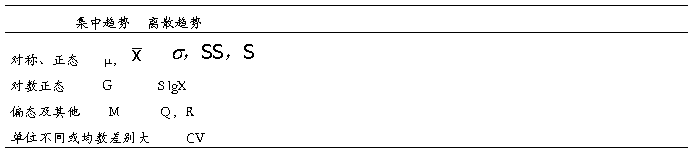
医学统计的资料类型:计量资料、计数资料、等级分组资料
医学统计学的对象:有变异的事物
总体和样本:
总体(population)的特性:同质性、大量性、差异性。
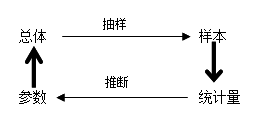
抽样的要求:代表性、随机性、可靠性、可比性。
样本的三性:代表性、随机性、可靠性。
可靠性(reliability):实验的结果要具有可重复性。即由科研课题的样本得出的结论所推测总体的结论有较大的可信度。
两样本间具有:可比性。
误差的类别:
1、系统误差(system error):在资料的收集过程中,由于仪器初始状态没有调零、标准试剂未经矫正、标准指定偏高或偏低等原因,造成的观察结果的倾向性的偏大或偏小。必须克服。
2、随机测量误差(random measurement error):在避免系统误差的情况下,由于各种偶然因素的影响造成对同一对象多次测量值的不一致。
3、抽样误差(sampling error):由于抽样造成的的样本统计量与总体参数之间的差别。不可避免。样本含量越大,抽样误差越小。如均数的抽样误差: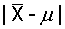 。
。
概率(probability):P(A)
小概率事件:P≤0.05(有统计学意义)或P≥0.01(有高度统计学意义)。
Chapter 集中趋势的统计描述
手工整理资料频数表(frequency table)的步骤:
1、求极差(全距)
2、确定组数、组距
参考组距=全距 / 组数
3、确定组段
4、手工编制划记表
直方图(histogram):
高度:各组的频数 纵轴
宽度:组距 横轴表示组限
均数(average):
适用:对称分布或偏度不大的资料,尤其适合正态分布。
1、算术均数(mean):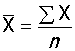
2、加权均数: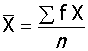
3、几何均数:
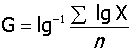 ,
,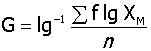
中位数(median):观察值按照从小到大排列时,居中心位置的数值。
适用于1、分布明显成偏态时,2、频数分布的一端或两端无确切数值时。不便于统计计算。
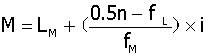
M:中位数;LM:M所在组的上限;f L:M所在组之前积累的频数;fM:M所在组的频数;i:组距。
百分位数(percentile):Px。在一组中找到这样一个数值P,全部观察值的x%小于P。P75、P25描述资料离散程度。
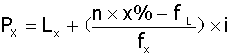
众数:一组观察值中,出现频率最高的那个观察值。若为分组资料,则为频率最高组的组中值。适用于大样本,但粗糙。
Chapter 离散程度的统计描述
离散的表述指标:
1、按间距计算:极差、四分位数间距
2、按平均差距:离均差平方和、方差、标准差、变异系数
极差(range,R):即全距。粗略。适用于任何分布。
四分位数间距(quartile,Q):一组观察值按大小排序后,分成四个数目相等的段落,每个段落观察值的数目占总例数的25%。去掉两端含有极端数值的25%,取中间的50%的观察值的数据范围即为~。
越大则数据变异越大。适用于偏态分布。
Q=P75 - P25
离均差平方和(sum of square of deviation):
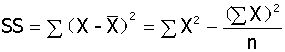
方差(variance):
样本方差 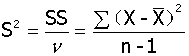
总体方差 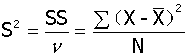
标准差(standard deviations):

适用于近似正态分布。
p.s.1、可用于合并资料的直接计算
2、与均数结合可以完整概括一个正态分布。
变异系数(CV):用于均属相差交大或单位不同的几组数据观察值的比较。
CV=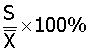
正态分布(normal distribution):
1、正偏态分布:高峰向左,长尾向右
负偏态分布:高峰向右,长尾向左。
2、μ和σ是正态分布总体的两个参数,对应样本统计量中的S和X。实际应用中μ和σ通常未知,可以将S和X作为总体参数的估计量使用。
注意对比: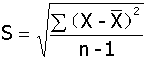
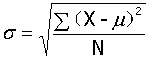
2、μ是位置参数,σ是变异参数。
描述方法:N(μ,σ2)
3、曲线下面积的意义:X1~X2出现的概率。
μ±σ 68.3%
μ±1.96σ (单侧μ±1.645σ) 95%
μ±2.58σ(单侧μ±2.33σ) 99%
标准正态分布(standard~):是μ=0,σ=1的正态分布。
对于任何参数为μ、σ的正态分布,都可以通过变量变换转化成标准正态分布: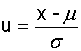 。
。
医学参考值范围(reference value range)的制定方法:
1、选择足够数量的正常人作为参照样本
2、对选定的参照样本进行准确的测定
3、决定取单侧范围还是双侧范围值
4、选择适当的百分范围
5、估计参考值范围的界限
Chapter 抽样误差与可信区间
中心极限定理:在样本含量很大的情况下(n≥50),无论样本测量量(X)服从什么分布,样本均数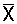 的抽样分布都近似服从以μ为均数的正态分布N(μ,σ2/n)
的抽样分布都近似服从以μ为均数的正态分布N(μ,σ2/n)
标准误(standard error):样本均数之间变异的标准差。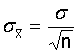
实际工作中总体标准差σ 未知,,用样本的标准差S代替: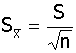
标准差与标准误的区别:

标准误(公式)的意义:
1、与标准差的联系:在样本含量一定的情况下,标准误与标准差成正比。
(1)当观察值的变异(标准差)较小时,样本均数之间的抽样误差较小,抽到的样本均数与总体均属可能相差较小,用估计μ的可靠性较好
(2)当观察值的变异较大时,样本均数之间的抽样误差较大,抽到的样本均数与总体均属可能相差较大,用估计μ的可靠性较差。
2、与样本含量的关系:与其平方根成反比,说明在同一总体中随机抽样,样本含量越大,标准误越小。
3、标准误反映了样本均数间的离散程度,也反映了样本均数与总体均数的差异。
参数估计(parameter estimation):指偶那个过样本参数估计总体参数,是统计推断的重要内容之一。常用方法有点估计、区间估计。
点估计(point ~):使用单一数值直接作为总体参数的估计值。适用于各种资料。
区间估计(interval ~):按照预先给定的概率计算出一个区间,使它能够包含总体参数。给定的概率(1-α)称为可信度。计算得到的区间称为可信区间(confidence interval,CI)
可信区间通常包括两个数值界定的可信限(confidence limit),分别为上限、下限。
总体均数估计的95%可信区间表示:该区间有95%的概率包含总体均数μ。注意不可以说“总体均数有95%的概率落在这个区间里”。
可信区间估计效果的比较:
1、(1-α)越接近1越好,概率↑
2、区间宽度越窄越好,精确度↑
但两者是矛盾的。一般选择(1-α)=95%。
t分布(t distribution):是以0为中心的对称分布;当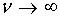 时,t分布的极限分布就是标准正态分布。在正态分布的总体中进行抽样,
时,t分布的极限分布就是标准正态分布。在正态分布的总体中进行抽样, 服从自由度
服从自由度 的t分布。
的t分布。
t的大小与α、自由度有关。
可信区间的计算:
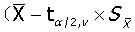 ,
,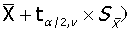
若n≥50,则t分布接近标准正态分布,则简化
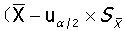 ,
,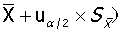
若σ已知,则可简化为
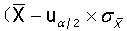 ,
,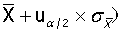
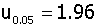 ,
,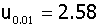
Chapter 假设检验
假设检验(hypothesis test):
目的:比较总体参数有无差别
基本思想:首先对所需比较的总体提出一个无差别的假设,然后通过样本数据推断是否拒绝这一假设。
基本方法:反证法和小概率事件。
基本步骤:
1、建立假设和确定检验水准
无效假设(null hypothesis):H0:μ=μ0(或μd=0),总体均数无差别。
备择假设(alternative ~):H0:μ≠μ0(或μd≠0),总体均数有差别
假设有单侧和双侧两种。应用单侧检验一定要有过硬的专业知识。一般选用双侧检验,因为双侧检验得出有显著差别的结论,单侧检验结论也一定是显著差别;然而反之不亦然。
检验水准亦称显著性水准(significance level),用α表示,是预先设定的拒绝域的概率值。一般取0.05。
2、选择检验方法和计算检验统计量

3、确定P值、做出统计推断结论
P值的意义:假设检验下结论的主要依据,指在原假设成立的条件下,观察到的样本差别是由机遇所致的概率。
结论:
1、p<α,样本数据差异显著,有统计学意义,拒绝H0,接受H1
2、P>α,样本数据差异不显著,无统计学意义,根据现有样本不足以拒绝H0(不等于接受H0)。
单样本的t检验:
条件:μ,,S,n
1、H0:μ=μ0 ,α=0.05,双侧检验
2、t=,
3、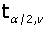
配对样本t检验:
条件:n,指标1、指标2(d,∑d,∑d2)
1、H0:μd=0,α=0.05
2、t=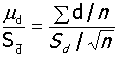
3、
成组设计实验的两样本均数比较
条件:n1,n2,1,2,S1,S2
1、H0:μ1=μ2 ,
2、u=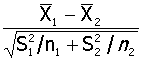
3、,
F检验:
条件:表格略
1、H0:各组总体均数相同,
H1:各组总体均数不全相同
2、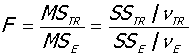 ,
,
vTR=k-1,vE=n-k
3、F符合自由度为(k-1,n-k)的F分布。
F值接近1,则可认为均值只来源于随机波动。若F>1,且F>Fα,(k-1,n-k),则P<α,……。
假设检验中的两类错误:
1、第一类错误:当H0为真时,拒绝H0接受H1。又称假阳性错误(阳性指两者总体参数有差异)。检验水准α是预先规定的犯第一类错误的概率的最大值。
2、第二类错误:当H0为假时,不拒绝H0。又称假阴性错误。概率大小用β表示,只取单侧,一般未知。
可证,α越大β越小,α越小β越越大。若要同时减少第一类错误和第二类错误,唯一方法是增大样本含量。
简单四格表的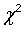 检验:
检验:

1、H0: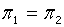 ,α=0.05
,α=0.05
2、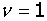
当n≥40,且所有T≥5时,四格表专用公式
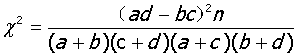
当n≥40,但有1<T≤5时,使用四格表校正公式
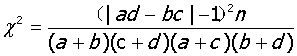
当n≤40,或有T≤1时,使用Fisher确切概率公式
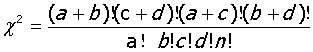
3、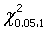 =3.84,
=3.84,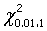 =6.63
=6.63
配对四格表检验:
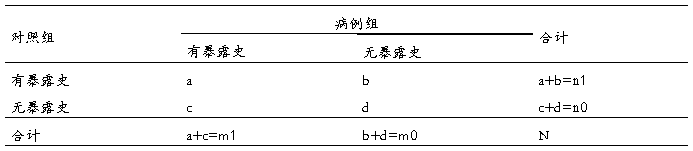
1、H0:,α=0.05
2、,
当b+c≥40时,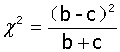
当b+c<40时,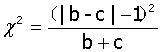
3、=3.84,=6.63
行*列资料的检验:
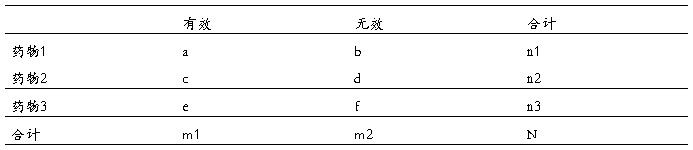
1、H0:各组有效率相同,
H1:各组有效率不全相同
2、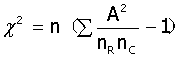 ,
,
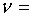 (行数-1)(列数-1)
(行数-1)(列数-1)
3、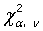
Chapter 相对数及其应用
相对数(relative number):是两个有关的据对数之比,也可以是两个有关的统计指标之比。常用的有:率、比值比、构成比。
率(rate):表示在一定的范围内某现象的发生数与可能发生的总数之比。
构成比(constitute ratio):表示某事物内部组成部分在总体中的比重。
相对比(relative ratio):A、B两有关联的指标之比,用以描述两者的对比水平。如RR。
第二篇:医学统计学总结
一、两组或多组计量资料的比较
1.两组资料:
1)大样本资料或服从正态分布的小样本资料
(1)若方差齐性,则作成组t检验
(2)若方差不齐,则作t’检验或用成组的Wilcoxon秩和检验
2)小样本偏态分布资料,则用成组的Wilcoxon秩和检验
2.多组资料:
1)若大样本资料或服从正态分布,并且方差齐性,则作完全随机的方差分析。如果方差分析的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:LSD检验,Bonferroni检验等)进行两两比较。
2)如果小样本的偏态分布资料或方差不齐,则作Kruskal Wallis的统计检验。如果Kruskal Wallis的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:用成组的Wilcoxon秩和检验,但用Bonferroni方法校正P值等)进行两两比较。
二、分类资料的统计分析
1.单样本资料与总体比较
1)二分类资料:
(1)小样本时:用二项分布进行确切概率法检验;
(2)大样本时:用U检验。
2)多分类资料:用Pearson c2检验(又称拟合优度检验)。
2. 四格表资料
1)n>40并且所以理论数大于5,则用Pearson c2
2)n>40并且所以理论数大于1并且至少存在一个理论数<5,则用校正c2或用Fisher’s 确切概率法检验
3)n£40或存在理论数<1,则用Fisher’s 检验
3. 2×C表资料的统计分析
1)列变量为效应指标,并且为有序多分类变量,行变量为分组变量,则行评分的CMH c2或成组的Wilcoxon秩和检验
2)列变量为效应指标并且为二分类,列变量为有序多分类变量,则用趋势c2检验
3)行变量和列变量均为无序分类变量
(1)n>40并且理论数小于5的格子数<行列表中格子总数的25%,则用Pearson c2
(2)n£40或理论数小于5的格子数>行列表中格子总数的25%,则用Fisher’s 确切概率法检验
4. R×C表资料的统计分析
1)列变量为效应指标,并且为有序多分类变量,行变量为分组变量,则CMH c2或Kruskal Wallis的秩和检验
2)列变量为效应指标,并且为无序多分类变量,行变量为有序多分类变量,作none zero correlation analysis的CMH c2
3)列变量和行变量均为有序多分类变量,可以作Spearman相关分析
4)列变量和行变量均为无序多分类变量,
(1)n>40并且理论数小于5的格子数<行列表中格子总数的25%,则用Pearson c2
(2)n£40或理论数小于5的格子数>行列表中格子总数的25%,则用Fisher’s 确切概率法检验
三、Poisson分布资料
1.单样本资料与总体比较:
1)观察值较小时:用确切概率法进行检验。
2)观察值较大时:用正态近似的U检验。
2.两个样本比较:用正态近似的U检验。
配对设计或随机区组设计四、两组或多组计量资料的比较
1.两组资料:
1)大样本资料或配对差值服从正态分布的小样本资料,作配对t检验
2)小样本并且差值呈偏态分布资料,则用Wilcoxon的符号配对秩检验
2.多组资料:
1)若大样本资料或残差服从正态分布,并且方差齐性,则作随机区组的方差分析。如果方差分析的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:LSD检验,Bonferroni检验等)进行两两比较。
2)如果小样本时,差值呈偏态分布资料或方差不齐,则作Fredman的统计检验。如果Fredman的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:用Wilcoxon的符号配对秩检验,但用Bonferroni方法校正P值等)进行两两比较。
五、分类资料的统计分析
1.四格表资料
1)b+c>40,则用McNemar配对c2检验或配对边际c2检验
2)b+c£40,则用二项分布确切概率法检验
2.C×C表资料:
1)配对比较:用McNemar配对c2检验或配对边际c2检验
2)一致性问题(Agreement):用Kap检验
变量之间的关联性分析六、两个变量之间的关联性分析
1.两个变量均为连续型变量
1)小样本并且两个变量服从双正态分布,则用Pearson相关系数做统计分析
2)大样本或两个变量不服从双正态分布,则用Spearman相关系数进行统计分析
2.两个变量均为有序分类变量,可以用Spearman相关系数进行统计分析
3.一个变量为有序分类变量,另一个变量为连续型变量,可以用Spearman相关系数进行统计分析
七、回归分析
1.直线回归:如果回归分析中的残差服从正态分布(大样本时无需正态性),残差与自变量无趋势变化,则直线回归(单个自变量的线性回归,称为简单回归),否则应作适当的变换,使其满足上述条件。
2.多重线性回归:应变量(Y)为连续型变量(即计量资料),自变量(X1,X2,…,Xp)可以为连续型变量、有序分类变量或二分类变量。如果回归分析中的残差服从正态分布(大样本时无需正态性),残差与自变量无趋势变化,可以作多重线性回归。
1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
3.二分类的Logistic回归:应变量为二分类变量,自变量(X1,X2,…,Xp)可以为连续型变量、有序分类变量或二分类变量。
1)非配对的情况:用非条件Logistic回归
(1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
(2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
2)配对的情况:用条件Logistic回归
(1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
(2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
4.有序多分类有序的Logistic回归:应变量为有序多分类变量,自变量(X1,X2,…,Xp)可以为连续型
变量、有序分类变量或二分类变量。
1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
5.无序多分类有序的Logistic回归:应变量为无序多分类变量,自变量(X1,X2,…,Xp)可以为连续型变量、有序分类变量或二分类变量。
1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用