实验报告

实验三 连续变量的统计描述与参数估计
实验目的:
1.了解连续变量的统计描述指标体系和参数估计指标体系。
2.掌握具体案例的统计描述和分析。
3.学会bootstrap等方法。
实验原理:
1、spss的许多模块均可完成统计描述的任务。
2、spss有专门用于连续变量统计描述的过程。
3、spss可以进行频率等数据分析。
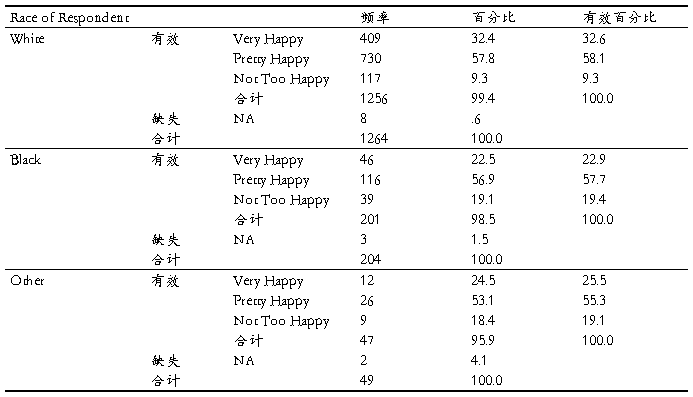
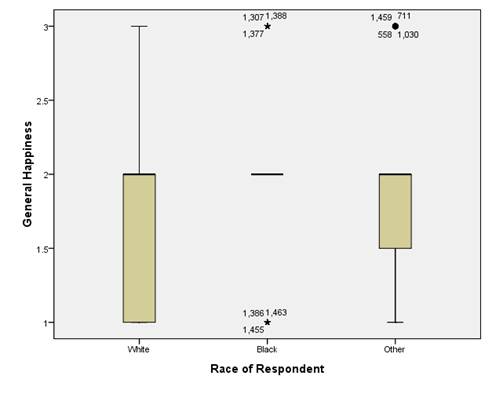
实验内容:1 根据CCSS数据,分析受访者的年龄分布情况,分城市/合并描述,并给出简要结果分析。
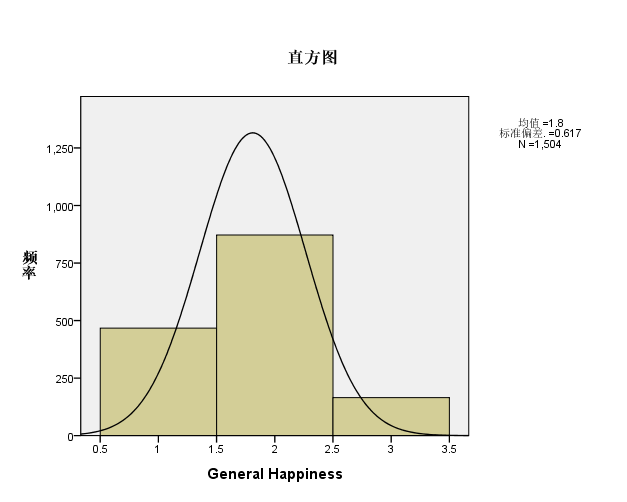
2 对CCSS中的总指数、现状指数和预期指数进行标准正态变换,对变换后的变量进行统计描述,并给出简要说明。
3根据CCSS 数据,分城市对现状指数的均数和标准差进行Bootstrap方法的参数点估计和区间估计,并同时与传统方法计算出的均值95%置信区间进行比较,给出简要结果分析。
4 根据CCSS项目数据,对职业和婚姻状况进行统计描述,并进行简 要说明。
5 根据CCSS项目数据,对职业和家庭月收入情况的关系进行统计描述,并进行行列百分比的汇总,对结果进行简要说明。
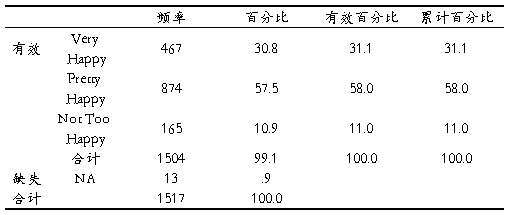
6根据CCSS项目数据,给出变量A3a各选项的频数分布情况,并分析每个选项的应答人次和应答人数百分比。
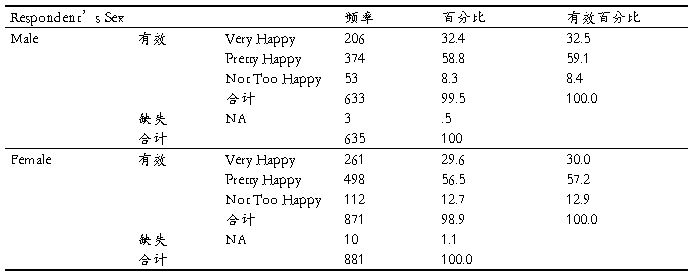
7根据CCSS项目数据,分城市考察A3a各选项的频数分布情况,并给出简要分析。
实验步骤:
(1) 在分析菜单中点击描述统计,打开对话框“探索”。把“S3年龄”添加到“因变量列表”,把“S0城市”添加到“因子列表”,把“ID”添加到“标注个案”,点击“确定”。
(2) 在分析菜单中点击描述统计,打开对话框“描述性”。把总指数[index1]、现状指数[index1a]和预期指数[index1b]添加到“变量”框中,选中下方的“将标准化得分另存为变量(Z)”,点击“确定”。
…… …… 余下全文
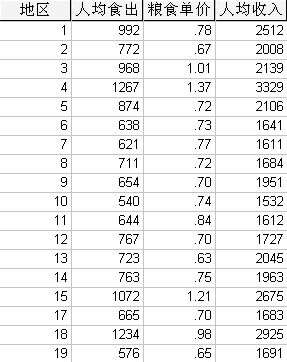

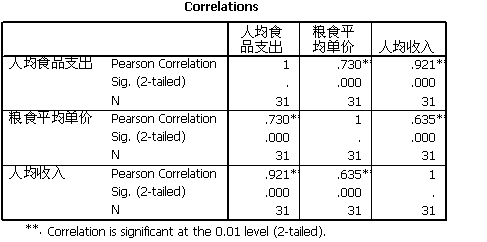
 b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,
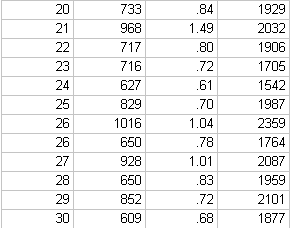
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate, 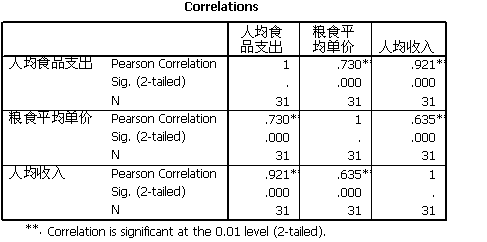


 b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate, 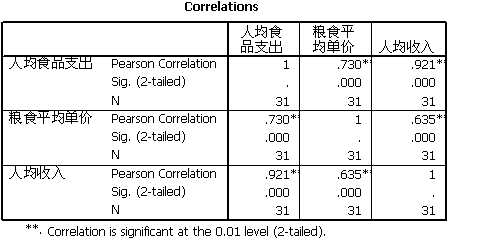

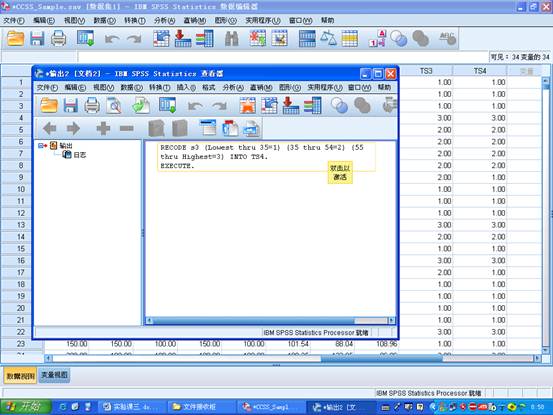
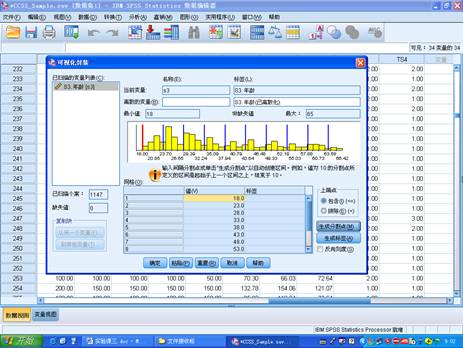
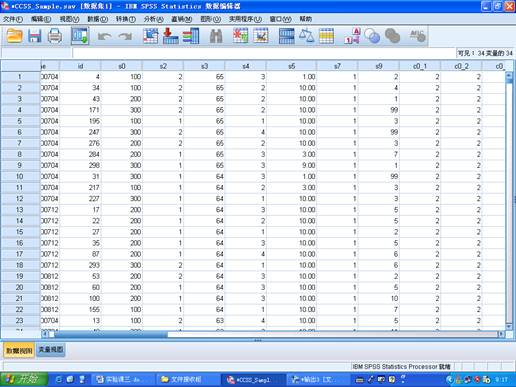



 b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,