数据挖掘-WAKA
实验报告
一、WEKA软件简介
在我所从事的证券行业中,存在着海量的信息和数据,但是这些数据日常知识发挥了一小部分的作用,其包含了大量的隐性的信息并不为所用,但是却可以为一些公司的决策和对客户的服务提供不小的价值。因此,我们可以通过一些数据采集、数据挖掘来获得潜在的有价值的信息。
数据挖掘就是通过分析存在于数据库里的数据来解决问题。在数据挖掘中计算机以电子化的形式存储数据,并且能自动的查询数据,通过关联规则、分类于回归、聚类分析等算法对数据进行一系列的处理,寻找和描述数据里的结构模式,进而挖掘出潜在的有用的信息。数据挖掘就是通过分析存在于数据库里的数据来解决问题。WEKA的出现让我们把数据挖掘无需编程即可轻松搞定。
WEKA是由新西兰怀卡托大学开发的开源项目,全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis)。WEKA是由JAVA编写的,它的源代码可通过http://www.cs.waikato.ac.nz/ml/WEKA得到,并且限制在GBU通用公众证书的条件下发布,可以运行在所有的操作系统中。是一款免费的,非商业化的机器学习以及数据挖掘软件
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以看一看WEKA的接口文档。在WEKA中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
安装WEKA也十分简单,首相要下载安装JDK环境 ,JDK在这个页面可以找到它的下载 http://java.sun.com/javase/downloads/index.jsp。点击JDK 6之后的Download按钮,转到下载页面。选择Accepct,过一会儿页面会刷新。我们需要的是这个 Windows Offline Installation, Multi-language jdk-6-windows-i586.exe 53.16 MB ,点击它下载。也可以右键点击它上面的链接,在Flashget等工具中下载。安装它和一般软件没什么区别。不过中间会中断一下提示你安装JRE,一并装上即可。之后就是安装WEKA软件,这个在网上很多地方都有。同样简单地按默认方法安装后即可使用。
…… …… 余下全文


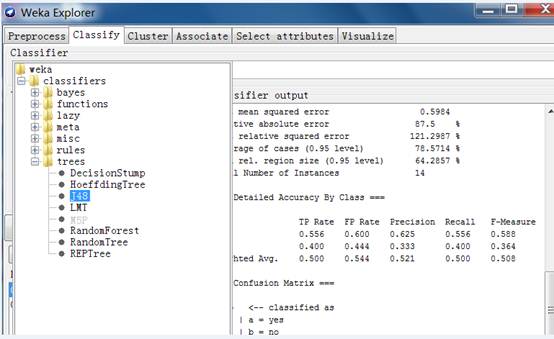
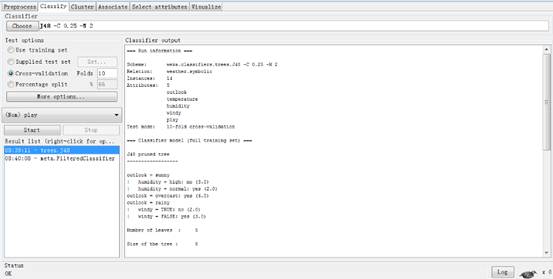
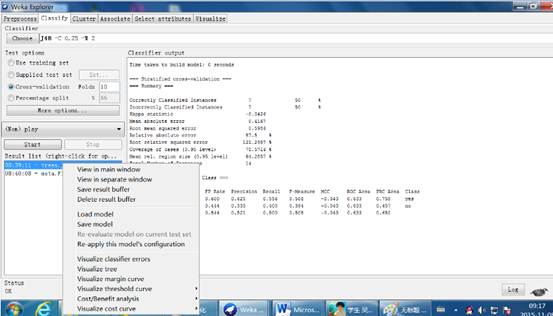
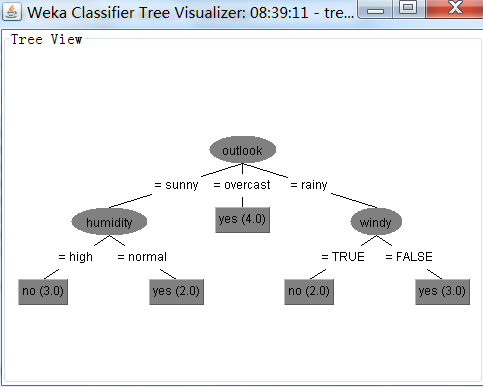
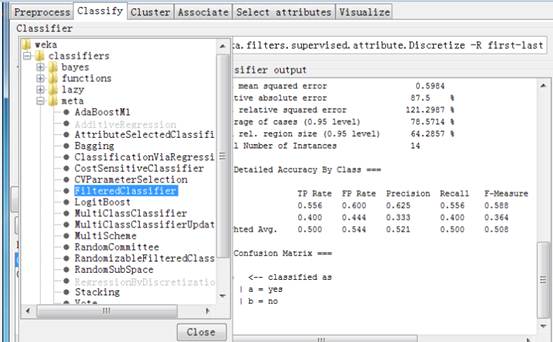
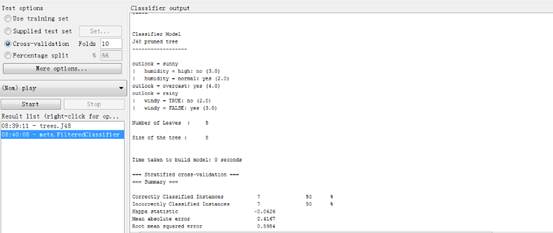
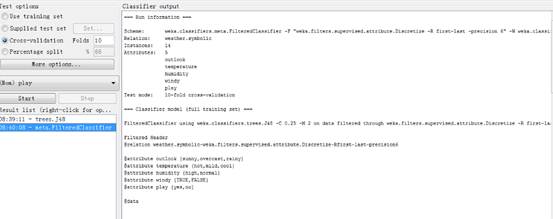
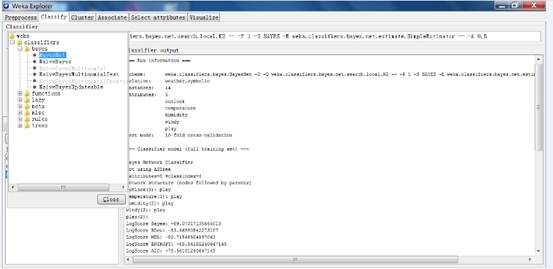
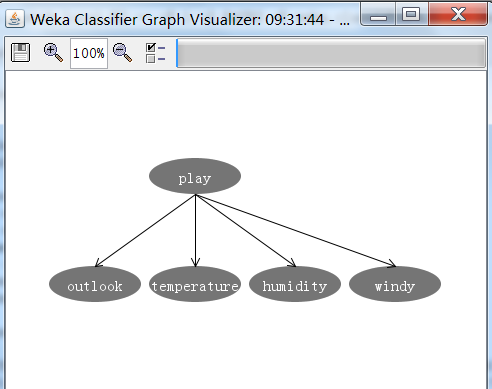



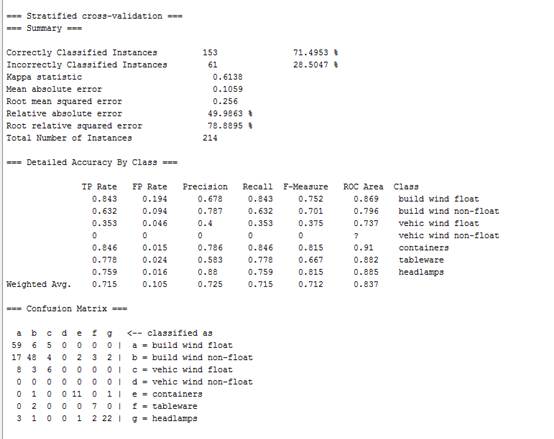
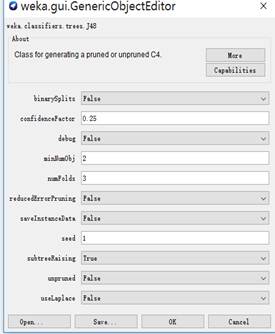 用j48决策树决策树分类算法,并用默认值执行
用j48决策树决策树分类算法,并用默认值执行