数据挖掘实验报告
基于weka的数据分类分析实验报告
姓名: 学号:
1实验基本内容
本实验的基本内容是通过使用weka中的三种常见分类方法(朴素贝叶斯,KNN和决策树C4.5)分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。
2数据的准备及预处理
2.1格式转换方法
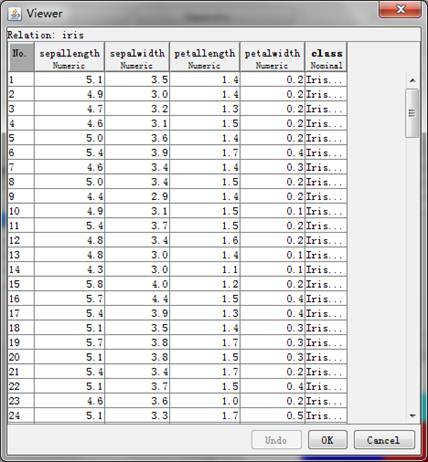
原始数据是老师直接给的arff文件,因此不用转换,可以直接导入。但如果原始数据是excel文件保存的xlsx格式数据,则需要转换成Weka支持的arff文件格式或csv文件格式。由于Weka对arff格式的支持更好,这里我们选择arff格式作为分类器原始数据的保存格式。
转换方法:假如我们准备分析的文件为“breast-cancer.xlsx”,则在excel中打开“breast-cancer.xlsx”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“breast-cancer”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“breast-cancer.csv”文件;然后,打开Weka的Exporler,点击Open file按钮,打开刚才得到的“filename”文件,点击“save”按钮,在弹出的对话框中,文件名输入“breast-cancer”,文件类型选择“Arff data files(*.arff)”,这样得到的数据文件为“breast-cancer.arff”。
1
数据挖掘实验报告
2.2如何建立数据训练集,校验集和测试集

通过统计数据信息,发现带有类标号的数据一共有286行,为了避免数据的过度拟合,必须把数据训练集和校验集分开,目前的拆分策略是训练集200行,校验集86行。类标号为‘no-recurrence-events’的数据有201条,而类标号为‘recurrence-events’的数据有85条,为了能在训练分类模型时有更全面的信息,所以决定把包含115条no-recurrence-events类标号数据和85条recurrence-events类标号数据作为模型训练数据集,而剩下的86条类标号类no-recurrence-events的数据将全部用于校验数据集,这是因为在校验的时候,两种类标号的数据的作用区别不大,而在训练数据模型时,则更需要更全面的信息,特别是不同类标号的数据的合理比例对训练模型的质量有较大的影响。另外,我们为了做预测测试,我们将分类标号为no-recurrence-events的86行数据集的分类标号去掉,作为预测数据集。
…… …… 余下全文